
社区提供的md在线写作编辑框对我来说实在是太小了,并且将本地图片文件上传到编辑框的过程实在是体验不佳,所以写了一个文章转换脚本,脚本编写的过程也是提供给各位师傅开发工具的一点点思路。
工具目的
- 解决编写文章时将本地图片上传到在线编辑框的繁琐,特别是写文章的时候,在线编辑图片上传完成时会自动定位到文章开头,又得慢慢往下拉页面...
- 专注于文章创作
适合人群
- 喜欢在本地用
Typora工具 md 写作的师傅
脚本编写
这里一共有两个文件夹和两个文件
old_file:用来存放本地编写的原md文件
new_file:运行脚本后生成的新md文件
config.ini:配置文件
convert.py:python脚本
其实想法也很简单,首先读取 old_file 文件夹下的原md文件,并且使用正则去提取其中的本地图片路径存进列表中
def old_file_read(file_name):
file = open("./old_file/"+file_name, 'r', encoding="utf-8").read()
file = urllib.parse.unquote(file)
return file
def get_image(file_name):
short_file_name = file_name.split(".")[0]
file_content = old_file_read(file_name)
img_pattern = r'(!\[.*?\]\({0}\.assets/image-.*?.png\))'.format(short_file_name)
image_list = re.findall(img_pattern, file_content)
return image_list
接着就是写请求将图片进行上传,并且提取返回包中的图片路径存在列表中
def upload_img(file_name):
img_list = get_image(file_name)
dir_list = []
img_path_list = []
for i in img_list:
short_file_name = file_name.split(".")[0]
img_pattern = r'({0}\.assets/image-.*?.png)'.format(short_file_name)
dir = re.findall(img_pattern, i)
print(dir)
dir_list.extend(dir)
for i in dir_list:
i = str(i)
real_file = "./old_file/" + i
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0",
"Host": "forum.butian.net",
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"X-CSRF-TOKEN": config['settings']['X-CSRF-TOKEN'],
"Connection": "close",
"Referer": "https://forum.butian.net/share/create",
"Cookie": config['settings']['cookie']
}
pattern = r"(image-.*?.png)"
img_name = re.search(pattern, i).group()
res = requests.post(url="https://forum.butian.net/image/uploadS3", headers=headers, files ={"file": open(real_file,"rb")}, verify=False)
img_url = res.text
print(f"\033[1;35m[+]{file_name} upload success! >> \033[0m" + img_url)
img_path = f"![{img_name}]" + f"({img_url})"
img_path_list.append(img_path)
return img_path_list
然后接下来将原文件中的本地图片路径替换为上传至奇安信攻防社区图床后的图片路径,并且生成新文件到 new_file 文件夹中
def custom_make_translation(text, translation):
regex = re.compile('|'.join(map(re.escape, translation)))
return regex.sub(lambda match: translation[match.group(0)], text)
def create_file(file_name):
content = old_file_read(file_name)
img_list = get_image(file_name)
if img_list:
path_list = upload_img(file_name)
dicts = dict()
for i,j in zip(img_list,path_list):
dicts[i]=j
content = custom_make_translation(content, dicts)
new_file = open("./new_file/"+file_name, 'w')
print(f"\033[1;32m[ok]{file_name} create success!\033[0m")
new_file.write(content)
完整代码如下
'''
Author: dota_st
blog: www.wlhhlc.top
'''
import requests
import re
import configparser
import warnings
import os
import urllib.parse
warnings.filterwarnings("ignore")
config = configparser.ConfigParser()
config.read("config.ini")
def old_file_read(file_name):
file = open("./old_file/"+file_name, 'r', encoding="utf-8").read()
file = urllib.parse.unquote(file)
return file
def get_image(file_name):
short_file_name = file_name.split(".")[0]
file_content = old_file_read(file_name)
img_pattern = r'(!\[.*?\]\({0}\.assets/image-.*?.png\))'.format(short_file_name)
image_list = re.findall(img_pattern, file_content)
return image_list
def upload_img(file_name):
img_list = get_image(file_name)
dir_list = []
img_path_list = []
for i in img_list:
short_file_name = file_name.split(".")[0]
img_pattern = r'({0}\.assets/image-.*?.png)'.format(short_file_name)
dir = re.findall(img_pattern, i)
print(dir)
dir_list.extend(dir)
for i in dir_list:
i = str(i)
real_file = "./old_file/" + i
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0) Gecko/20100101 Firefox/95.0",
"Host": "forum.butian.net",
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate",
"X-CSRF-TOKEN": config['settings']['X-CSRF-TOKEN'],
"Connection": "close",
"Referer": "https://forum.butian.net/share/create",
"Cookie": config['settings']['cookie']
}
pattern = r"(image-.*?.png)"
img_name = re.search(pattern, i).group()
res = requests.post(url="https://forum.butian.net/image/uploadS3", headers=headers, files ={"file": open(real_file,"rb")}, verify=False)
img_url = res.text
print(f"\033[1;35m[+]{file_name} upload success! >> \033[0m" + img_url)
img_path = f"![{img_name}]" + f"({img_url})"
img_path_list.append(img_path)
return img_path_list
def custom_make_translation(text, translation):
regex = re.compile('|'.join(map(re.escape, translation)))
return regex.sub(lambda match: translation[match.group(0)], text)
def create_file(file_name):
content = old_file_read(file_name)
img_list = get_image(file_name)
if img_list:
path_list = upload_img(file_name)
dicts = dict()
for i,j in zip(img_list,path_list):
dicts[i]=j
content = custom_make_translation(content, dicts)
new_file = open("./new_file/"+file_name, 'w')
print(f"\033[1;32m[ok]{file_name} create success!\033[0m")
new_file.write(content)
def main():
file_list = os.listdir("./old_file/")
files = " ".join(file_list)
logo = r"""
_____ _ _
/ __ \/\| | (_)| |
| | | | __ ___ __ / \ _ __| |_ _ ___| | ___
| | | |/ _` \ \/ / / /\ \ | '__| __| |/ __| |/ _ \
| |__| | (_| |> < / ____ \| | | |_| | (__| | __/
\___\_\\__,_/_/\_\/_/\_\_| \__|_|\___|_|\___|
Powered by dota_st
Blog's: https://www.wlhhlc.top/
"""
print(logo)
print(f"\033[1;34m[*]scan file_dir: {files}\033[0m")
for i in file_list:
if os.path.exists("./new_file/" + i):
pass
elif ".assets" in i:
pass
else:
create_file(i)
if __name__ == '__main__':
main()
使用方法
首先在config.ini文件中填写自己的账号cookie(注意:如果抓包获取到的cookie中带有url编码,请进行url解码在填写)
其次就是在 old_file 文件夹中新建和编写我们的 md 文章,然后Typora对图片设置如下相对路径规则
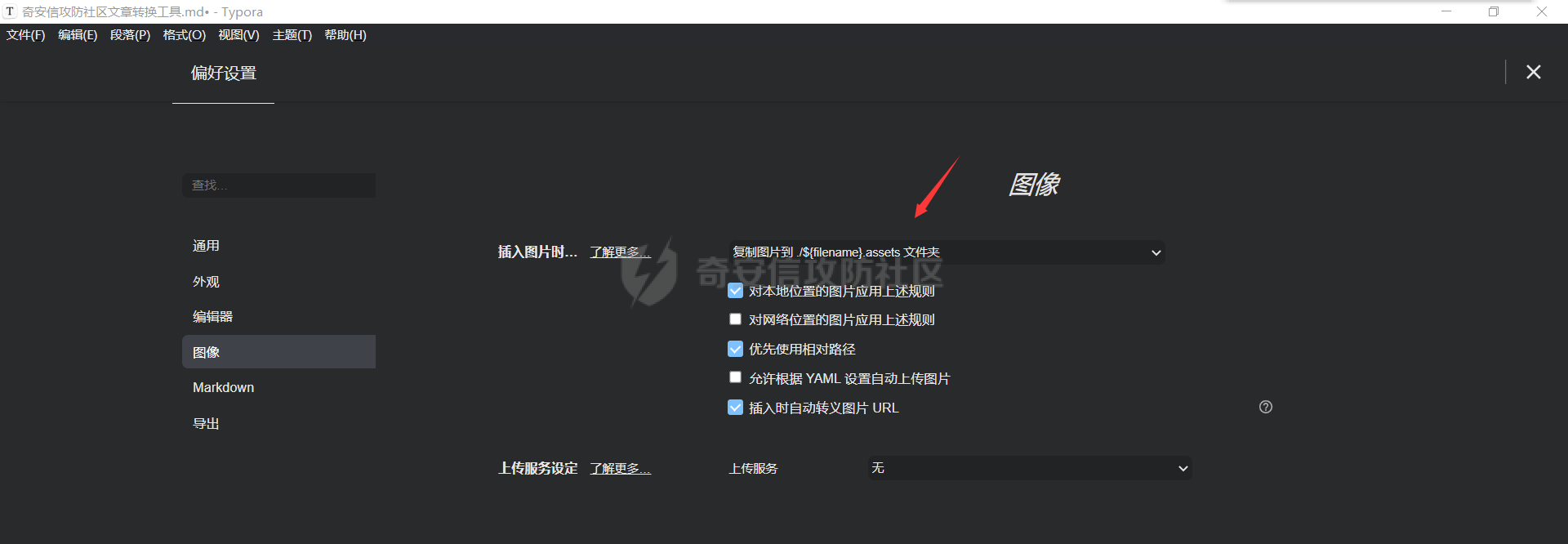
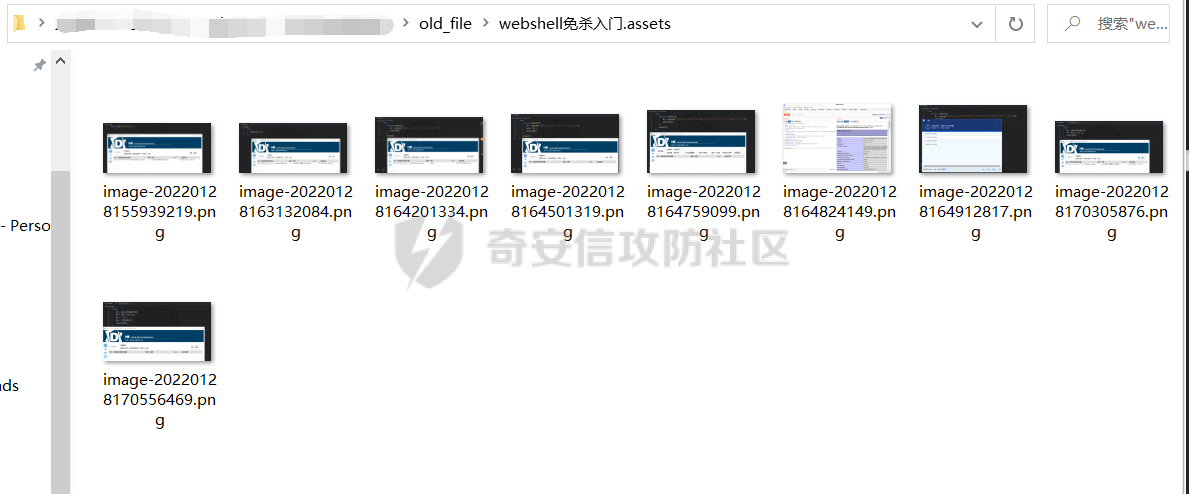
这样当我们截图图片后crtl+v粘贴到md中时,会自动存在当前 md 文件的同级目录下,并且其生成的图片文件夹命名格式为md文件名.assert
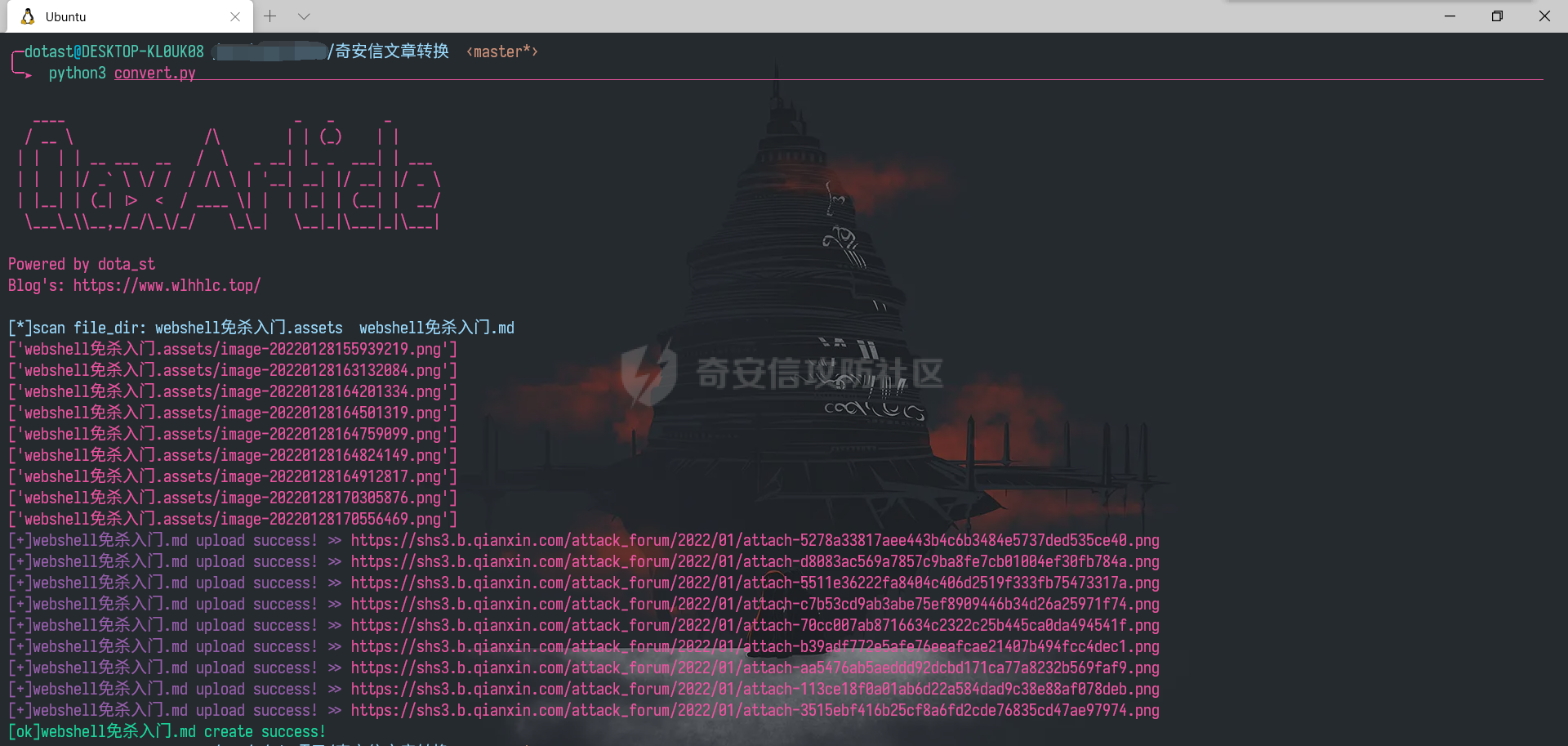
编写完后,运行脚本便会在 new_file 文件夹下生成转换后的 md 文件,打开复制内容粘贴到奇安信攻防社区中发布文章即可。运行效果如下
工具支持批量转换,已打包至github:https://github.com/dota-st/QaxArticle
总结
上面便是编写一个工具的过程及思路,该工具旨在提高编写文章的舒适感,希望能对师傅们提供绵薄之力。
- 本文作者: dota_st
- 本文来源: 奇安信攻防社区
- 原文链接: https://forum.butian.net/share/1172
- 版权声明: 除特别声明外,本文各项权利归原文作者和发表平台所有。转载请注明出处!

