
本文主要介绍CTF逆向题目曾经出现过的两种混淆技术:控制流平坦化和Debug Blocker技术
0x00 前言
本文主要介绍CTF逆向题目曾经出现过的两种混淆技术:控制流平坦化和Debug Blocker技术
0x01 控制流平坦化
控制流平坦化(control flow flattening)的基本思想主要是通过一个主分发器来控制程序基本块的执行流程,这样可以模糊基本块之间的前后关系,增加程序分析的难度。
举例说明:
一个程序的正常执行逻辑如下图
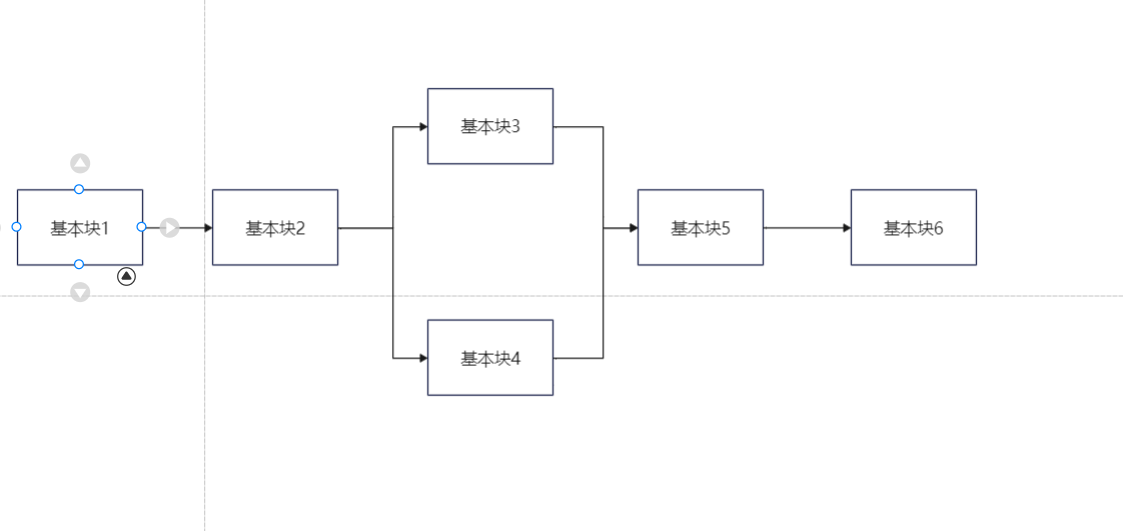
经过控制流平坦化后的执行流程就如下图
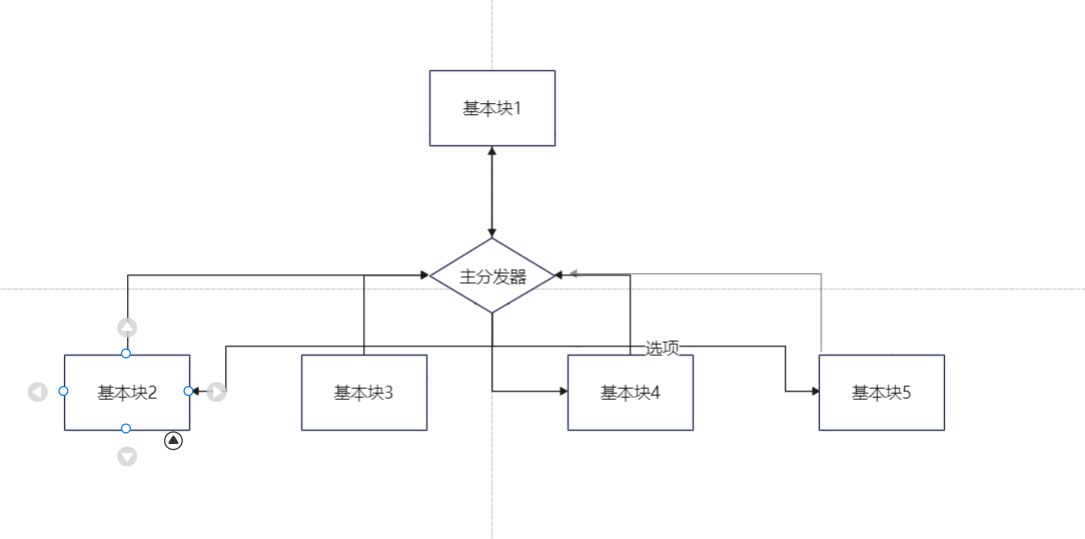
控制流平坦化的本质:混淆代码块之间的逻辑,将其之前的逻辑混肴成switch嵌套循环,增加分析难度。
利用angr符号执行去流平坦化
环境配置|ubuntu angr
首先安装一些依赖包
sudo apt-get install python-dev libffi-dev build-essential virtualenvwrapper
安装angr
mkvirtualenv angr && pip install angr
建议使用 virtualenv 来安装,因为 angr 用到的一些库和正常下的不一样,直接 pip 安装可能会安装不上去。我的ubuntu上无mkvirtualenv命令,但是很幸运,pip安装成功了
实战去流平坦化|[RoarCTF2019]polyre
从程序结构图可以看出非常明显的流平坦化特征
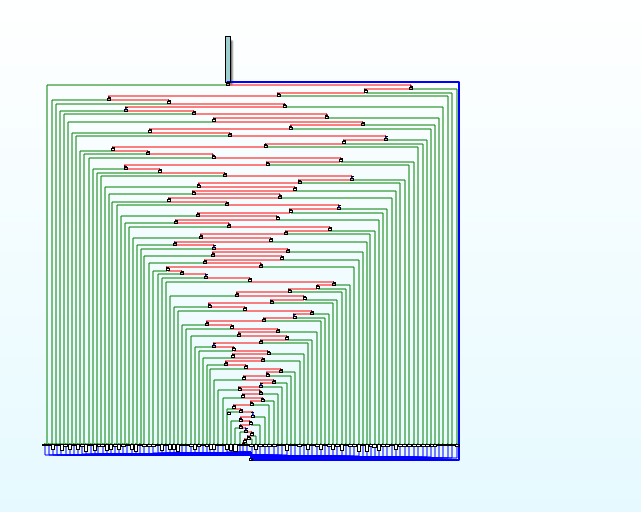
查看main函数地址

这里我们使用腾讯安全应急响应中心提供的工具进行去平坦化的处理,工具链接:
https://github.com/cq674350529/deflat
看到successful,标志着我们成功去除流平坦化混淆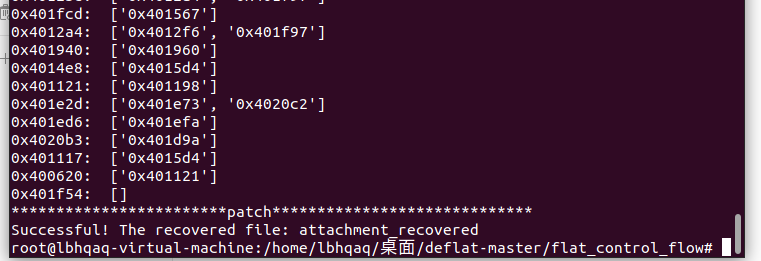
将我们去混淆的程序放入ida可以看到程序结构恢复到正常结构
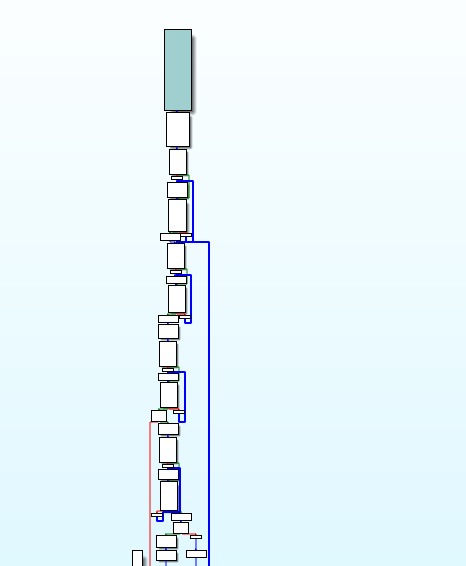
观察代码,此时开启了虚假控制流程,代码中的条件都是永真条件(while;do...while),因此可以在观察时忽略或删除while语句和do...while语句。

也可以写脚本来处理虚假控制流程,这里提供一个官方WP中给出的脚本,在IDA中的script中执行即可。
def patch_nop(start,end):
for i in range(start,end):
PatchByte(i, 0x90)
def next_instr(addr):
return addr+ItemSize(addr)
st = 0x0000000000401117
end = 0x0000000000402144
addr = st
while(addr<end):
next = next_instr(addr)
if "ds:dword_603054" in GetDisasm(addr):
while(True):
addr = next
next = next_instr(addr)
if "jnz" in GetDisasm(addr):
dest = GetOperandValue(addr, 0)
PatchByte(addr, 0xe9)
PatchByte(addr+5, 0x90)
offset = dest - (addr + 5)
PatchDword(addr + 1, offset)
print("patch bcf: 0x%x"%addr)
addr = next
break
else:
addr = next
最终我们得到了去平坦化之后的加密核心代码
__int64 __fastcall main(__int64 a1, char **a2, char **a3)
{
signed __int64 v4; // [rsp+1E0h] [rbp-110h]
signed int j; // [rsp+1E8h] [rbp-108h]
signed int i; // [rsp+1ECh] [rbp-104h]
signed int k; // [rsp+1ECh] [rbp-104h]
char s1[48]; // [rsp+1F0h] [rbp-100h]
char s[60]; // [rsp+220h] [rbp-D0h]
unsigned int v10; // [rsp+25Ch] [rbp-94h]
char *v11; // [rsp+260h] [rbp-90h]
int v12; // [rsp+26Ch] [rbp-84h]
bool v13; // [rsp+272h] [rbp-7Eh]
unsigned __int8 v14; // [rsp+273h] [rbp-7Dh]
int v15; // [rsp+274h] [rbp-7Ch]
char *v16; // [rsp+278h] [rbp-78h]
int v17; // [rsp+284h] [rbp-6Ch]
int v18; // [rsp+288h] [rbp-68h]
bool v19; // [rsp+28Fh] [rbp-61h]
char *v20; // [rsp+290h] [rbp-60h]
int v21; // [rsp+298h] [rbp-58h]
bool v22; // [rsp+29Fh] [rbp-51h]
__int64 v23; // [rsp+2A0h] [rbp-50h]
bool v24; // [rsp+2AFh] [rbp-41h]
__int64 v25; // [rsp+2B0h] [rbp-40h]
__int64 v26; // [rsp+2B8h] [rbp-38h]
__int64 v27; // [rsp+2C0h] [rbp-30h]
__int64 v28; // [rsp+2C8h] [rbp-28h]
int v29; // [rsp+2D0h] [rbp-20h]
int v30; // [rsp+2D4h] [rbp-1Ch]
char *v31; // [rsp+2D8h] [rbp-18h]
int v32; // [rsp+2E0h] [rbp-10h]
int v33; // [rsp+2E4h] [rbp-Ch]
bool v34; // [rsp+2EBh] [rbp-5h]
v10 = 0;
memset(s, 0, 0x30uLL);
memset(s1, 0, 0x30uLL);
printf("Input:", 0LL);
v11 = s;
__isoc99_scanf("%s", s, (dword_603054 - 1), 3788079310LL);
for ( i = 0; ; ++i )
{
v12 = i;
v13 = i < 64;
if ( i >= 64 )
break;
v14 = s[i];
v15 = v14;
if ( v14 == 10 )
{
v16 = &s[i];
*v16 = 0;
break;
}
v17 = i + 1;
}
for ( j = 0; ; ++j )
{
v18 = j;
v19 = j < 6;
if ( j >= 6 )
break;
v20 = s;
v4 = *&s[8 * j];
for ( k = 0; ; ++k )
{
v21 = k;
v22 = k < 64;
if ( k >= 64 )
break;
v23 = v4;
v24 = v4 < 0;
if ( v4 >= 0 )
{
v27 = v4;
v28 = 2 * v4;
v4 *= 2LL;
}
else
{
v25 = 2 * v4;
v26 = 2 * v4;
v4 = 2 * v4 ^ 0xB0004B7679FA26B3LL;
}
v29 = k;
}
v30 = 8 * j;
v31 = &s1[8 * j];
*v31 = v4;
v32 = j + 1;
}
v33 = memcmp(s1, &unk_402170, 0x30uLL);
v34 = v33 != 0;
if ( v33 != 0 )
puts("Wrong!");
else
puts("Correct!");
return v10;
}
通过观察可以,实际上这部分代码使用的是CRC32的查表法,对数据进行加密。
加密原理实际上就是CRC32算法:
输入一组长度48的字符串,每8个字节分为1组,共6组。对每一组取首位,判断正负。正值,左移一位;负值,左移一位,再异或0xB0004B7679FA26B3。重复判断操作64次,得到查表法所用的表。
因此我们只需要将整个加密过程逆向操作得到查表法的表
0x6666367b67616c66
0x63362d3039333932
0x2d363563342d3032
0x3539612d30376162
0x6631643365383537
0x7d38
再进行CRC64计算,就能得到flag
解密脚本
secret = [0xBC8FF26D43536296, 0x520100780530EE16, 0x4DC0B5EA935F08EC,
0x342B90AFD853F450, 0x8B250EBCAA2C3681, 0x55759F81A2C68AE4]
key = 0xB0004B7679FA26B3
flag = ""
# 产生CRC32查表法所用的表
for s in secret:
for i in range(64):
sign = s & 1
# 判断是否为负
if sign == 1:
s ^= key
s //= 2
# 防止负值除2,溢出为正值
if sign == 1:
s |= 0x8000000000000000
# 输出表
print(hex(s))
# 计算CRC64
j = 0
while j < 8:
flag += chr(s&0xFF)
s >>= 8
j += 1
print(flag)
0x02 Debug Blocker
Debug Blocker技术,顾名思义,是通过进程以调试模式运行自身或者其他可执行文件,使得我们难以动态调试。(在Windows中,一个进程无法被多个调试器进行调试,所以如果关键算法代码运行于被调试的子进程中,因为子进程与父进程之间构成调试者与被调试者的关系,就自然的形成了反调试作用)这是一种比较繁琐的反调试技术,常常应用在一些PE保护器中
debug blocker反调试特征
父与子的关系
调试器与被调试器关系中,调试进程与被调试进程首先是一种父子关系。
被调试进程不能在被其他调试器调试
Windows操作系统中,同一进程是无法同时被多个调试进程调试的,若想调试被调试进程,必须先切断原调试器与被调试者的关系。
终止调试进程的同时也终止被调试进程
强制终止调试进程以切断调试器-被调试器关系时,被调试进程也会同时终止。
调试器操作被调试者的代码
Debug Blocker技术中,调试器用来操作被调试进程的运行分支,生成或修改执行代码等,并且,调试器会对被调试进程的代码运行情况产生持续影响,缺少调试进程的前提下,仅凭被调试进程无法正常运行。
调试器处理被调试进程中发生的异常
调试者-被调试者关系中,被调试进程中发生的所有异常均有调试器处理。
被调试进程中故意触发某个异常时,若该异常未得到处理,则代码将无法继续运行。
被调试进程中发生异常时,进程会暂停,控制权转移到调试器,此时调试器可以修改被调试者的执行分支,此外也可以对被调试进程内部的加密代码解码,或者向寄存器、栈中存入某些特定值等。
debugBlocker实战|[2021MRCTF]MR_Register
破译debugBlocker保护程序的关键在子进程。分析方法很多,但绝大多数,只要找到debugblocker核心代码,静态分析和动调父进程看子进程反馈就好了。
跟进start函数,main函数一般在该语句后面一句被调用
*(_QWORD *)Buffer = 0i64;
v7 = 0;
PipeAttributes.bInheritHandle = 1;
PipeAttributes.lpSecurityDescriptor = 0i64;
PipeAttributes.nLength = 24;
if ( IsDebuggerPresent() )
{
sub_4026EA();
result = 0;
}
else
{
GetModuleFileNameA(0i64, Filename, 0xC8u);
CreatePipe(&hFile, &hWritePipe, &PipeAttributes, 0);
sprintf(Buffer, "%x", hWritePipe);
SetEnvironmentVariableA("hWrite", Buffer);
if ( !CreateProcessA(0i64, Filename, 0i64, 0i64, 1, 3u, 0i64, 0i64, &StartupInfo, (LPPROCESS_INFORMATION)&hProcess) )
{
v4 = GetLastError();
exit(v4);
}
GetStartupInfoA(&StartupInfo);
sub_40188D();
CloseHandle(hProcess);
CloseHandle(*(&hProcess + 1));
result = 1;
}
return result;
}
其实这里的if else语句就区别了父进程与子进程执行不同的语句,因为创建出的子进程是调试模式运行的。这里关注一下创建进程的dwCreationFlags参数
接下来继续分析后面父进程处理子进程异常的部分也就是sub_40188D()函数关键是看DebugEvent.dwDebugEventCode == 1的活动:接受处理来自子进程的异常,进而修改子进程代码。
参考大佬博客,找到了子进程异常的代码
第一次交互:通过除0异常触发
for ( i = 374; i >= 0; --i )
Buffer[i] ^= Buffer[i + 1] ^ i; // 对表进行了一个简单异或运算。
Buffer[375] = 120;
rip += 2;
第二次交互:通过int3交互,解密代码。
地址:0x0000401E1C
for ( i = 0; i <= 0x57D; ++i )
*((_BYTE *)v5 + i) ^= i;
rip += 2;
第三次,在patch后的代码第一次遇到int3,触发异常交互:
rip += 2
利用idapython patch文件,nop掉无用的代码
修改后我们得到关键函数

发现加密逻辑非常简单,逆向反写就可以得出flag
#include <stdio.h>
unsigned int enc[100] =
{
0x4d, 0x52, 0xe2, 0x188, 0x2b0, 0x4b3, 0x7a6, 0xc8d, 0x14a1, 0x218d, 0x36a7, 0x5864, 0x8f80, 0xe843, 0x17827, 0x2609d, 0x3d926, 0x63a38, 0xa13c5, 0x104e5c, 0x1a6252, 0x2ab122, 0x4513b3, 0x6fc534, 0xb4d955, 0x1249eb9, 0x1d9786d, 0x2fe179d, 0x4d7906b, 0x7d5a841, 0xcad38cd, 0x1482e18b
};
char flag[100];
int main(void)
{
int i = 0;
int init = enc[0]+enc[1];
flag[0] = enc[0], flag[1] = enc[1];
for(i = 2; i < 100; i++)
{
flag[i] = enc[i]-enc[i-1]-enc[i-2];
}
for(i = 0; i < 100; i++)
putchar(flag[i]);
}
0x03 后记
正如本文标题,浅浅学习了一波两种小众混淆技术。该部分内容难度较大,考察程序逆向的熟练性,路漫漫其修远兮,吾将上下而求索。
0x04 参考链接
https://blog.csdn.net/szxpck/article/details/107347638
https://zhuanlan.zhihu.com/p/345843635
https://security.tencent.com/index.php/blog/msg/112
- 本文作者: 绿冰壶
- 本文来源: 奇安信攻防社区
- 原文链接: https://forum.butian.net/share/1508
- 版权声明: 除特别声明外,本文各项权利归原文作者和发表平台所有。转载请注明出处!

