
在web渗透过程中,Web指纹识别是信息收集环节中⼀个重要的步骤。通过⼀些开源的⼯具、平台或者⼿⼯检测准确的获取CMS类型、Web服 务组件类型及版本信息可以帮助安全⼯程师快速有效的去验证已知漏洞。本篇文章主要通过分析当下使用较为热门的几种指纹识别工具源码,分享作者获得的对于web指纹识别原理的深入思考
在web渗透过程中,Web指纹识别是信息收集环节中⼀个重要的步骤。通过⼀些开源的⼯具、平台或者⼿⼯检测准确的获取CMS类型、Web服 务组件类型及版本信息可以帮助安全⼯程师快速有效的去验证已知漏洞。本篇文章主要通过分析当下使用较为热门的几种指纹识别工具源码,分享作者获得的对于web指纹识别原理的深入思考
0x00 前言
在我们平常看到的刑侦题材的小说、电视剧、电影中,指纹是一个绕不开的概念,⼈的指纹可以分辨不同的⼈,因为⼈的⼿指指纹每个⼈都不⼀样,所以可以作为分辨不同⼈的⽅式。按这种逻辑,我们去思考“指纹“的本质,是不是就是事物独一无二的特征?我们进一步思考,网站有没有“指纹” 呢?答案是肯定的。
0x01 常见指纹检测的对象
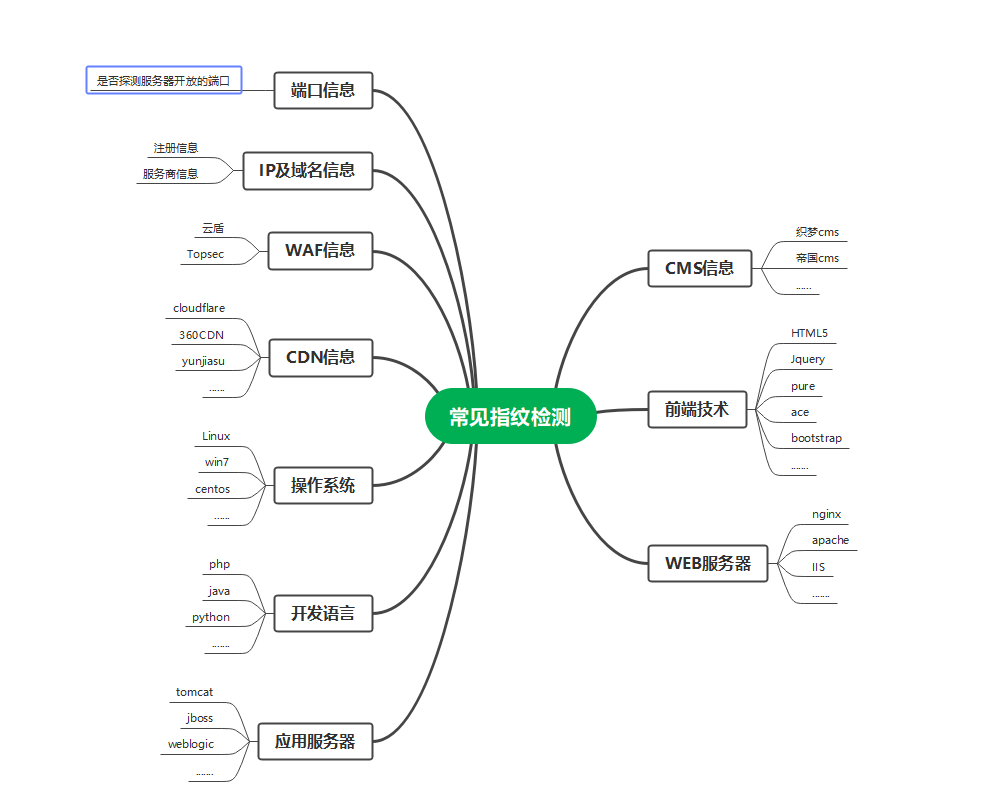
那么针对这些系统和服务如何进⾏指纹识别呢?既然指纹就是特征,系统服务特有的特征,所以指纹库 也就是特征库就是指纹识别的关键,⽬前国内外也有⼀些好⽤的⼯具,⽐如nmap、whatweb等知名 ⼯具。下面我们来介绍实战中指纹识别的常见方式
0x02 工具识别
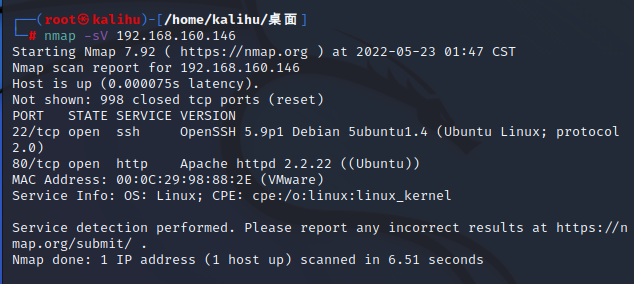
nmap
-sV (版本探测)
打开版本探测。 也可以用-A同时打开操作系统探测和版本探测。
nmap -sV www.yourdomains.com
-O (启用操作系统检测)
也可以使用**-A**来同时启用操作系统检测和版本检测。
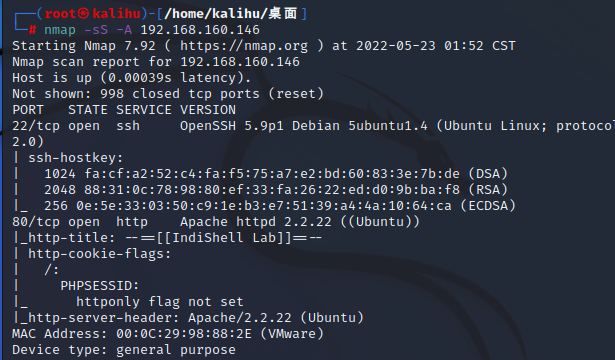
提高效率的几个参数
--osscan-limit (针对指定的目标进行操作系统检测)
如果发现一个打开和关闭的TCP端口时,操作系统检测会更有效。 采用这个选项,Nmap只对满足这个
条件的主机进行操作系统检测,这样可以 节约时间,特别在使用-P0扫描多个主机时。这个选项仅在使
用 -O或-A 进行操作系统检测时起作用。
--osscan-guess; --fuzzy (推测操作系统检测结果)
当Nmap无法确定所检测的操作系统时,会尽可能地提供最相近的匹配,Nmap默认 进行这种匹配,使
用上述任一个选项使得Nmap的推测更加有效。
whatweb
whatweb 是一个 web 应用程序指纹识别工具。可自动识别 CMS、BLOG 等 Web 系统。
这里还是利用vulhub上的一个靶机来测试,检测出服务器为apache,操作系统为 Ubuntu Linux等有效信息

0x03 工具是如何识别指纹信息的?
由于指纹识别工具的发展,其实渗透测试工作中,大多数情况下只需要使用工具来进行指纹识别就可以了。可写的东西确实有限。
然而求知欲非常强的我们不满足于单调的使用工具(其实是觉得报告字数太少了) 于是我们决定找几个开源的指纹识别工具的源码瞧一瞧,弄明白工具获取站点指纹信息的逻辑。
Webfinger 工具源码分析
Webfinger是一款很小巧的工具,由Python2编写,使用Fofa的指纹库
Github地址:https://github.com/se55i0n/Webfinger
首先使用Navicat查看Fofa库
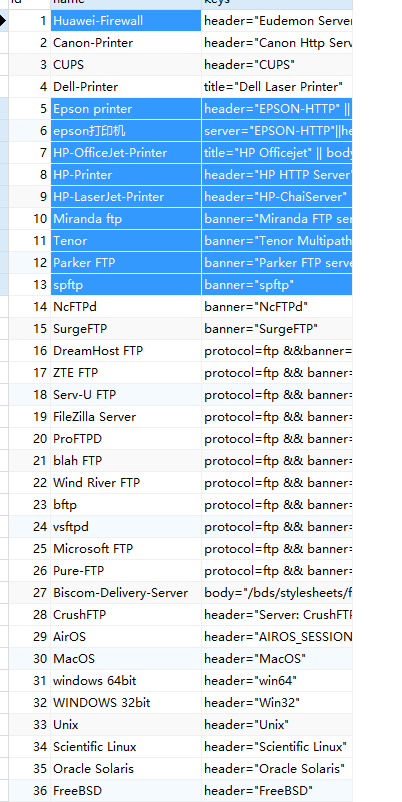
该库收录了一千条规则,比较齐全。通过判断返回包中 header body等字段的内容来进行判断。
接下来研究源码。 关键函数Cmsscanner
class Cmsscanner(object):
def __init__(self, target):
self.target = target
self.start = time.time()
setting()
def get_info(self):
"""获取web的信息"""
try:
r = requests.get(url=self.target, headers=agent,
timeout=3, verify=False)
content = r.text
try:
title = BeautifulSoup(content, 'lxml').title.text.strip()
return str(r.headers), content, title.strip('\n')
except:
return str(r.headers), content, ''
except Exception as e:
pass
def check_rule(self, key, header, body, title):
"""指纹识别"""
try:
if 'title="' in key:
if re.findall(rtitle, key)[0].lower() in title.lower():
return True
elif 'body="' in key:
if re.findall(rbody, key)[0] in body:return True
else:
if re.findall(rheader, key)[0] in header:return True
except Exception as e:
pass
def handle(self, _id, header, body, title):
"""取出数据库的key进行匹配"""
name, key = check(_id)
#满足一个条件即可的情况
if '||' in key and '&&' not in key and '(' not in key:
for rule in key.split('||'):
if self.check_rule(rule, header, body, title):
print '%s[+] %s %s%s' %(G, self.target, name, W)
break
#只有一个条件的情况
elif '||' not in key and '&&' not in key and '(' not in key:
if self.check_rule(key, header, body, title):
print '%s[+] %s %s%s' %(G, self.target, name, W)
#需要同时满足条件的情况
elif '&&' in key and '||' not in key and '(' not in key:
num = 0
for rule in key.split('&&'):
if self.check_rule(rule, header, body, title):
num += 1
if num == len(key.split('&&')):
print '%s[+] %s %s%s' %(G, self.target, name, W)
else:
#与条件下存在并条件: 1||2||(3&&4)
if '&&' in re.findall(rbracket, key)[0]:
for rule in key.split('||'):
if '&&' in rule:
num = 0
for _rule in rule.split('&&'):
if self.check_rule(_rule, header, body, title):
num += 1
if num == len(rule.split('&&')):
print '%s[+] %s %s%s' %(G, self.target, name, W)
break
else:
if self.check_rule(rule, header, body, title):
print '%s[+] %s %s%s' %(G, self.target, name, W)
break
else:
#并条件下存在与条件: 1&&2&&(3||4)
for rule in key.split('&&'):
num = 0
if '||' in rule:
for _rule in rule.split('||'):
if self.check_rule(_rule, title, body, header):
num += 1
break
else:
if self.check_rule(rule, title, body, header):
num += 1
if num == len(key.split('&&')):
print '%s[+] %s %s%s' %(G, self.target, name, W)
def run(self):
try:
header, body, title = self.get_info()
for _id in xrange(1, int(count())):
try:
self.handle(_id, header, body, title)
except Exception as e:
pass
except Exception as e:
print e
finally:
print '-'*54
print u'%s[+] 指纹识别完成, 耗时 %s 秒.%s' %(O, time.time()-self.start, W)
首先是获取fofa指纹库的信息,获取到信息后,对信息进行加工处理:
if '||' in key and '&&' not in key and '(' not in key:
for rule in key.split('||'):
if self.check_rule(rule, header, body, title):
print '%s[+] %s %s%s' %(G, self.target, name, W)
break
处理成我们想要的格式之后,进行规则校验,检测是否获取到合法的 header title body信息:
def check_rule(self, key, header, body, title):
try:
if 'title="' in key:
if re.findall(rtitle, key)[0].lower() in title.lower():
return True
elif 'body="' in key:
if re.findall(rbody, key)[0] in body: return True
else:
if re.findall(rheader, key)[0] in header: return True
except Exception as e:
pass
这几条规则的正则
rtitle = re.compile(r'title="(.*)"')
rheader = re.compile(r'header="(.*)"')
rbody = re.compile(r'body="(.*)"')
rbracket = re.compile(r'\((.*)\)')
接下来使用requests请求获得响应header和body,利用beautifulsoup对body进行解析获得title信息
r = requests.get(url=self.target, headers=agent,
timeout=3, verify=False)
content = r.text
try:
title = BeautifulSoup(content, 'lxml').title.text.strip()
return str(r.headers), content, title.strip('\n')
except:
return str(r.headers), content, ''
P.S:BeautifulSoup:解析和提取源代码数据的工具
详细介绍:https://baijiahao.baidu.com/s?id=1730159257158644560&wfr=spider&for=pc
这款工具比较优秀的是对于原始数据的解析处理这一部分:使用 1||2||(3&&4)的结构进行分割。确保3,4 与 1,2数据的分割。
使用num计数确保与操作中的每一项都通过检查,然后再依次进行或操作的检查。 最后将处理好的结果输出。
if '&&' in re.findall(rbracket, key)[0]:
for rule in key.split('||'):
if '&&' in rule:
num = 0
for _rule in rule.split('&&'):
if self.check_rule(_rule, header, body, title):
num += 1
if num == len(rule.split('&&')):
print '%s[+] %s %s%s' % (G, self.target, name, W)
break
else:
if self.check_rule(rule, header, body, title):
print '%s[+] %s %s%s' % (G, self.target, name, W)
break
webanalyzer工具源码分析
该工具的整体逻辑其实十分简单。作者也很贴心的 给了一张完备的规则注释表
| name | string | 规则名称 | rulename |
|---|---|---|---|
| search | string | 搜索的位置,可选值为 all, headers, title, body, script, cookies, headers[key], meta[key], cookies[key] | body |
| regexp | string | 正则表达式 | wordpress.* |
| text | string | 明文搜索 | wordpress |
| version | string | 匹配的版本号 | 0.1 |
| offset | int | regexp 中版本搜索的偏移 | 1 |
| certainty | int | 确信度 | 75 |
| md5 | string | 目标文件的 md5 hash 值 | beb816a701a4cee3c2f586171458ceec |
| url | string | 需要请求的 url | /properties/aboutprinter.html |
| status | int | 请求 url 的返回状态码,默认是 200 | 400 |
当接收到的match 中存在 url 字段,且满足要求(plugin 是属于 custom 类型且 aggression 开启) 则向该url发送json请求获取相关信息
def parse_rules(src, dst):
curdir = os.getcwd()
with open(os.path.join(curdir, src, "apps.json")) as fd:
c = json.load(fd)
m = {
'headers': parse_headers,
'html': parse_html,
'meta': parse_meta,
'scripts': parse_scripts,
'cookies': parse_cookies,
}
apps = c['technologies']
for name in apps:
matches = []
for key in apps[name]:
if key not in m:
continue
接着 分别在 headers,cookies,html,script,meta处根据search字段定位搜索位置,根据 regexp/text 进行文本匹配,或者 status 匹配状态码,或者 md5 匹配 body 的 hash 值
match 中存在 version 就表明规则直接出对应版本,如果存在 offset 就表明需要从 regexp 中匹配出版本。如果 rule 中存在 condition,则根据 condition 判断规则是否匹配(默认每个 match 之间的关系为 or)
def parse_meta(rule):
matches = []
for key, value in rule['meta'].items():
value = parse_value(value)
match = {
"search": "meta[%s]" % key,
'regexp': value['regexp']
}
if 'version' in value:
match['offset'] = value['version']
if 'confidence' in value:
match['certainty'] = value['confidence']
matches.append(match)
return matches
每一处进行的处理非常相似,所以这里只放对meta部分。
FingerPrint工具源码分析
Perl语言编写,使用Wappalyzer工具的库。作者疑似是百度的小姐姐(赛高)
https://github.com/tanjiti/FingerPrint
代码注释非常详细,可读性极高,不愧是大佬
逻辑非常简单,发送一个特定的请求包,之后将获取的返回包放入Wappalyzer库提供的接口,数据经处理后 以json格式输出结果
发送请求包的相关源码:
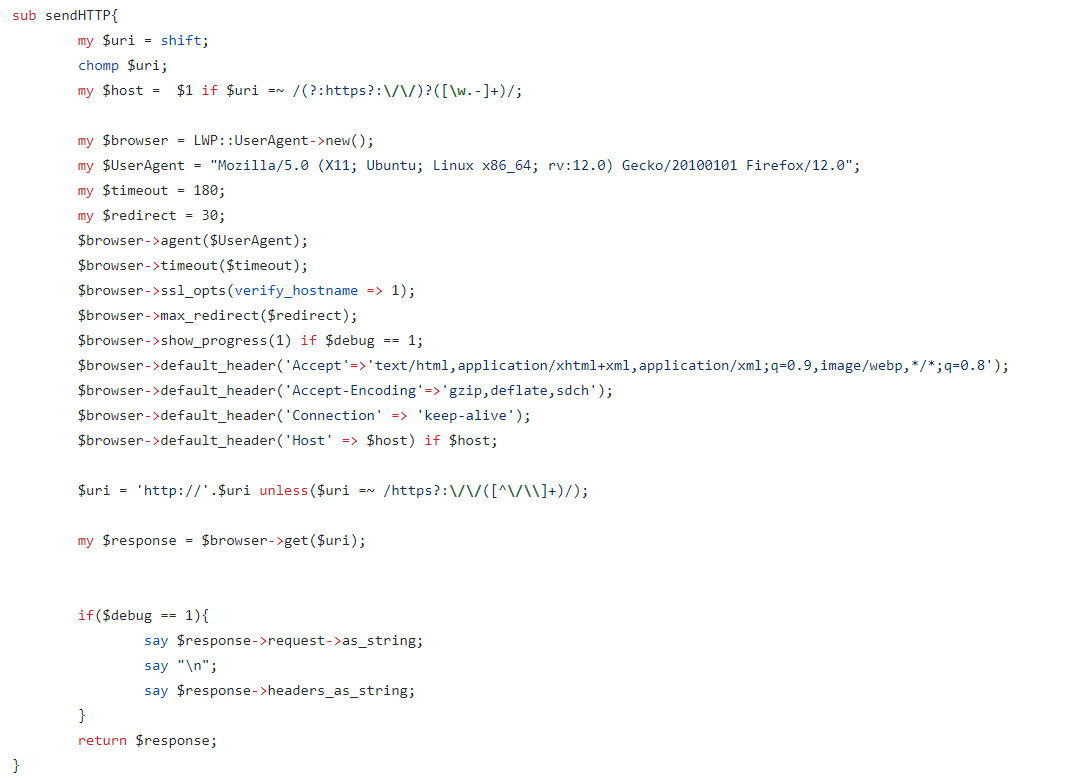
将返回包数据传入提供的接口的相关源码:
sub getFP{
my ($url,$rule_file) = @_;
my $response = sendHTTP($url);
#add your new finger print rule json file
add_clues_file($rulefile) if $rulefile and -e $rulefile;
my %detected = detect(
html=> $response->decoded_content,
headers => $response->headers,
url => $uri,
# cats => ["cms"],
);
my $result = jsonOutput($url,\%detected);
return $result;
}
0x04 总结
上文中我们通过研读三款常用指纹识别工具的源码,建立了对指纹识别原理的初步认识。现在让我们简单总结一下常见的指纹识别方式,方便我们后序自开发指纹识别工具、以及手工渗透测试过程中更加敏锐的识别网站cms信息。
特定⽂件的MD5
特定⽂件的MD5 ⼀些⽹站的特定图⽚⽂件、js⽂件、CSS等静态⽂件,如favicon.ico、css、logo.ico、js等⽂件⼀般 不会修改,通过爬⾍对这些⽂件进⾏抓取并⽐对md5值,如果和规则库中的Md5⼀致则说明是同⼀ CMS。这种⽅式速度⽐较快,误报率相对低⼀些,但也不排除有些⼆次开发的CMS会修改这些⽂件。
正常⻚⾯或错误⽹⻚中包含的关键字
先访问⾸⻚或特定⻚⾯如robots.txt等,通过正则的⽅式去匹配某些关键字,如Poweredby Discuz、dedecms等。 或者可以构造错误⻚⾯,根据报错信息来判断使⽤的CMS或者中间件信息,⽐较常⻅的如tomcat的报 错⻚⾯。
请求头信息的关键字匹配
根据⽹站response返回头信息进⾏关键字匹配,whatweb和Wappalyzer就是通过banner信息来快
速识别指纹,之前fofa的web指纹库很多都是使⽤的这种⽅法,效率⾮常⾼,基本请求⼀次就可以,但
搜集这些规则可能会耗时很⻓。⽽且这些banner信息有些很容易被改掉。
根据responseheader⼀般有以下⼏种识别⽅式:
(1)查看http响应报头的X-Powered-By字段来识别;
(2)根据Cookies来进⾏判断,⽐如⼀些waf会在返回头中包含⼀些信息,如360wzws、Safedog、 yunsuo等;
(3)根据header中的Server信息来判断,如DVRDVS-Webs、yunjiasu-nginx、 Mod_Security、nginx-wallarm等;
(4)根据WWW-Authenticate进⾏判断,⼀些路由交换设备可能存在这个字段,如NETCORE、 huawei、h3c等设备。
部分URL中包含的关键字
例如wp-includes、dede等URL关键特征 通过规则库去探测是否有相应⽬录,或者根据爬⾍结果对链接url进⾏分析,或者对robots.txt⽂件中 ⽬录进⾏检测等等⽅式,通过url地址来判别是否使⽤了某CMS,⽐如wordpress默认存在wpincludes和wp-admin⽬录,织梦默认管理后台为dede⽬录,solr平台可能使⽤/solr⽬录, weblogic可能使⽤wls-wsat⽬录等。
开发语⾔的识别
web开发语⾔⼀般常⻅的有PHP、jsp、aspx、asp等,常⻅的识别⽅式有:
(1)通过爬⾍获取动态链接进⾏直接判断是⽐较简便的⽅法。 asp判别规则如下:
<a[^>]*?href=('|")[^http][^>]*?\.asp(\?|\#|\1)
其他语⾔替换 相应asp即可。
(2)通过 X-Powered-By 进⾏识别:
⽐较常⻅的有 X-Powered-By: ASP.NET 或者 X-Powered-By: PHP/7.1.8
(3)通过 Set-Cookie 进⾏识别:
这种⽅法⽐较常⻅也很快捷,⽐如 Set-Cookie 中包含 PHPSSIONID 说明是php、包 含 JSESSIONID 说明是java、包含 ASP.NET_SessionId 说明是aspx等。
0x05 参考文章
https://github.com/wappalyzer/wappalyzer/blob/master/src/wappalyzer.js
https://blog.csdn.net/weixin_44420143/article/details/118674474
https://github.com/webanalyzer/rules/blob/build/tools/wappalyzer.py
https://github.com/webanalyzer/rules
https://www.freebuf.com/column/168786.html
https://github.com/tanjiti/FingerPrint/blob/master/FingerPrint.pl
- 本文作者: 绿冰壶
- 本文来源: 奇安信攻防社区
- 原文链接: https://forum.butian.net/share/1686
- 版权声明: 除特别声明外,本文各项权利归原文作者和发表平台所有。转载请注明出处!

