
如何编写一个高效且准确,最重要还是要快的URL去重脚本,是一个需要大量实践基础+拥有好的想法+具备工程化思想的难题
记一次分析crawlergo的URL去重原理
0x00 起序
crawlergo是一款实践广泛、效果广受好评的智能爬虫,其设计、理念和实现都有很多值得借鉴的点,自从crawlergo的作者宣布开源,自己就一直想找机会分析下这工具,本文主要通过分析其中的URL去重功能达到抛砖引玉的效果。
0x01 项目引入
下载项目:git clone https://github.com/Qianlitp/crawlergo.git,然后导入Goland IDE中。
查看Problems的时候,发现了很多缺失Package的错误, Shift 连按两下,输入proxy进去设置GoLand的全局代理,然后点击Show Quick Fixes 重新导入依赖包即可。
配置好Configuration参数,然后开始通过Debug分析程序的执行流程。
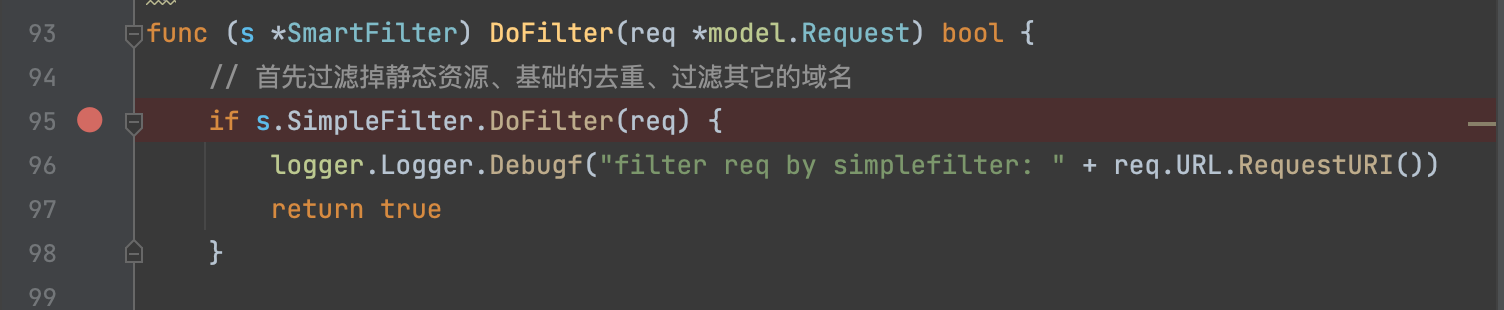
断点我选择断在URL去重的入口: pkg/filter/smart_filter.go line:93 DoFilter函数
0x02 执行流程
1)新建爬虫任务,指定URL过滤器
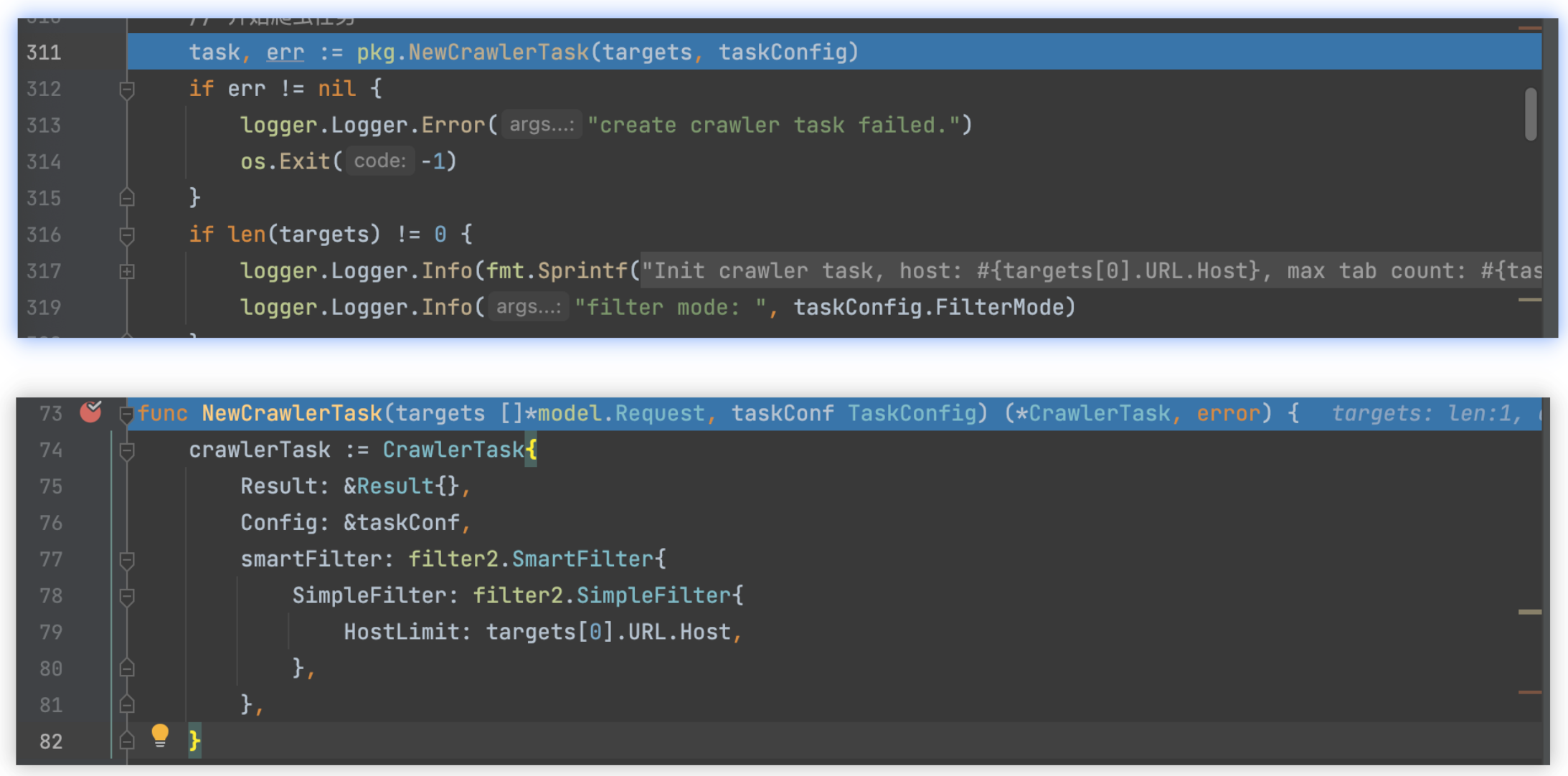
smartFilter: filter2.SmartFilter{
SimpleFilter: filter2.SimpleFilter{
HostLimit: targets[0].URL.Host,
},
},
2)URL过滤器,初始化,采用sync的结构存储数据,保证线程安全
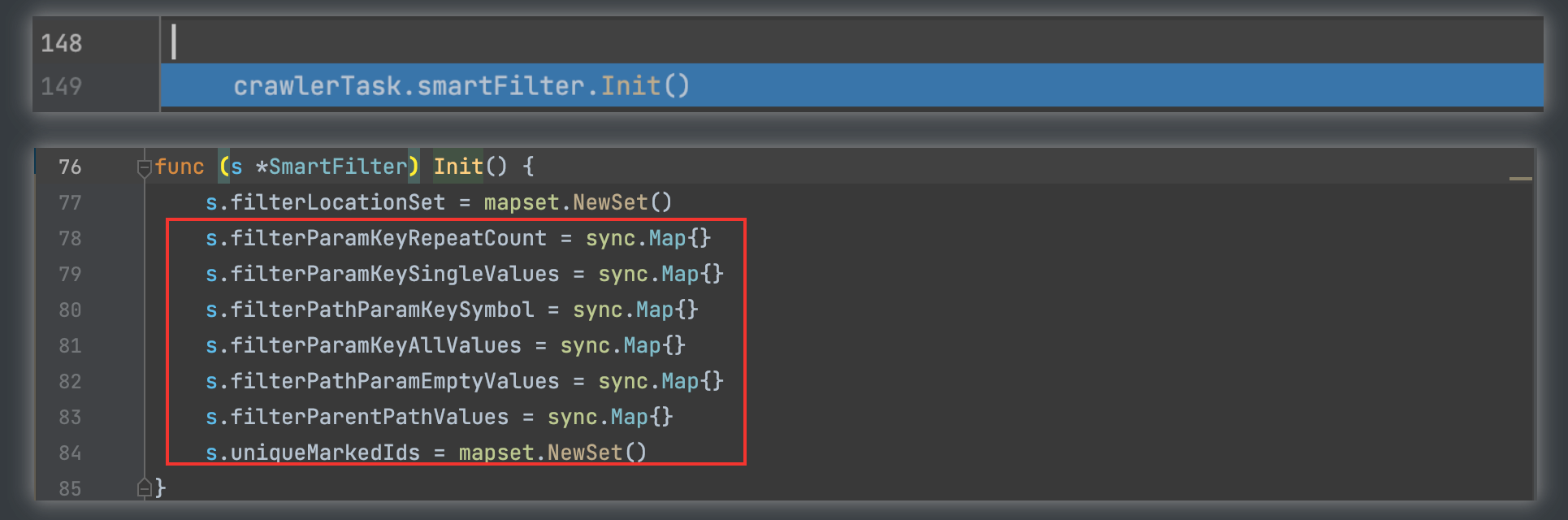
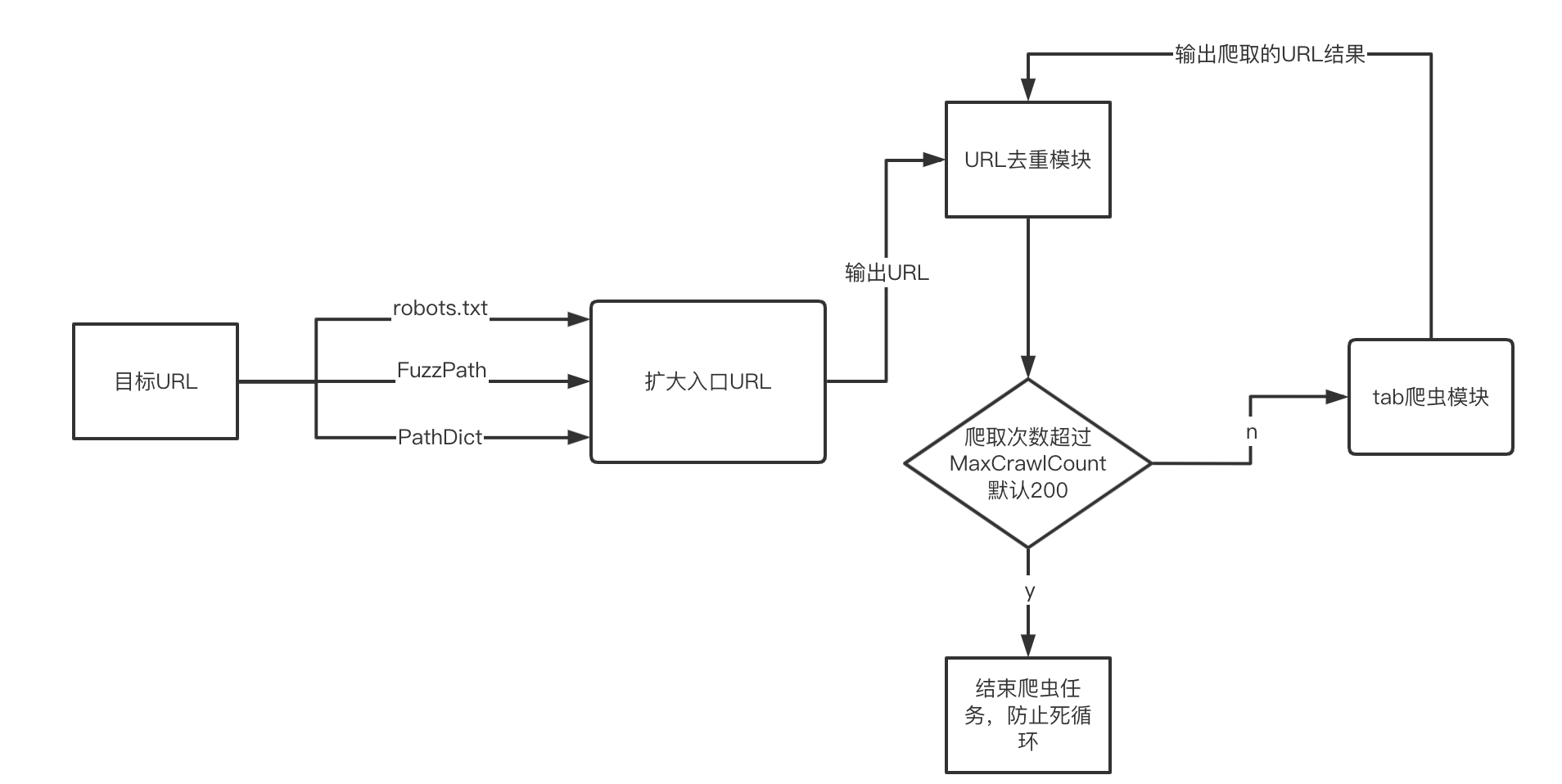
3)根据配置通过Robots信息或路径FUZZ/字典路径来扩充入口页面t.Targets列表,提高爬虫覆盖面。
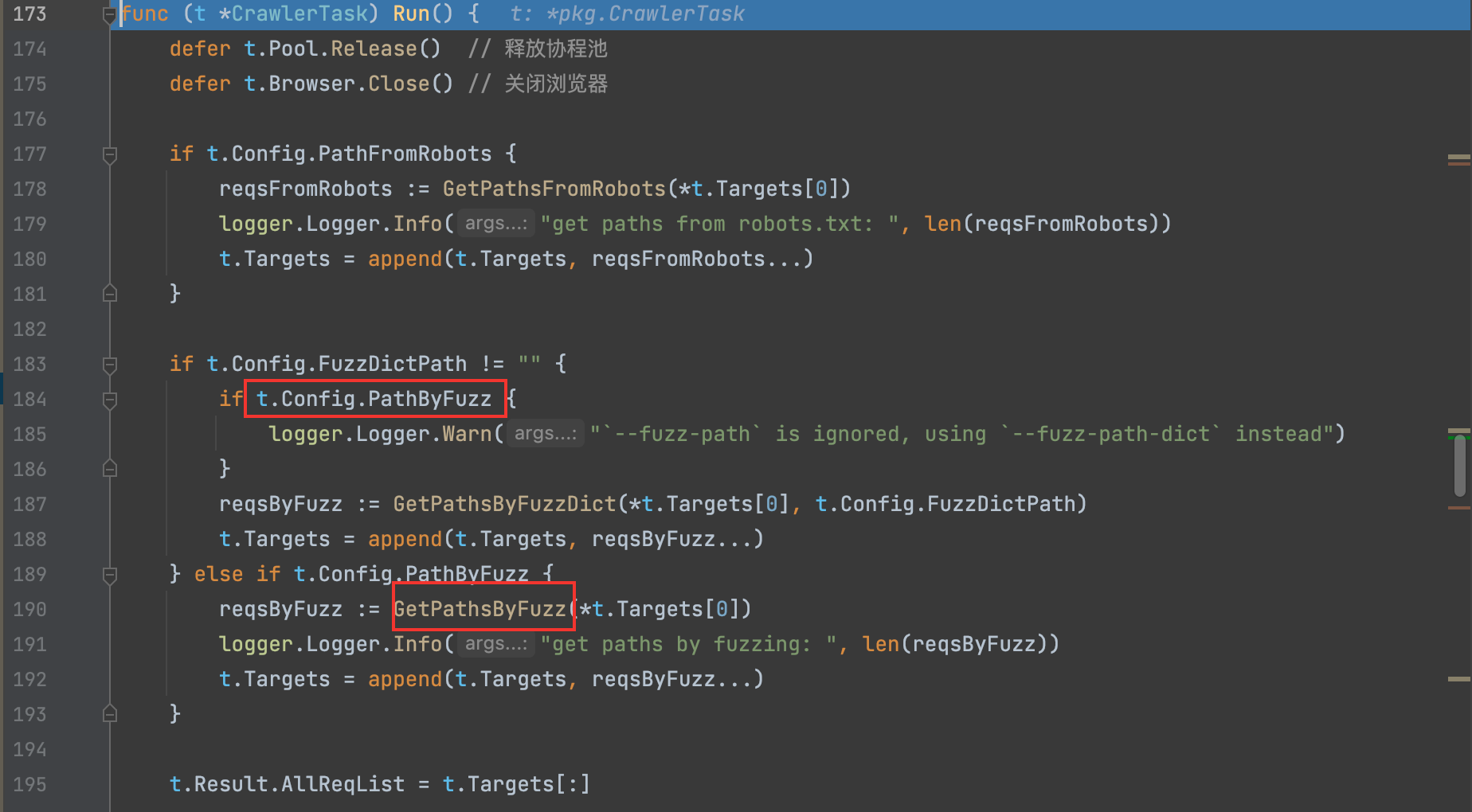
4)遍历入口URLt.Targets列表,并调用smartFilter智能去重模块的DoFilter函数过滤(后面重点分析这个去重模块)
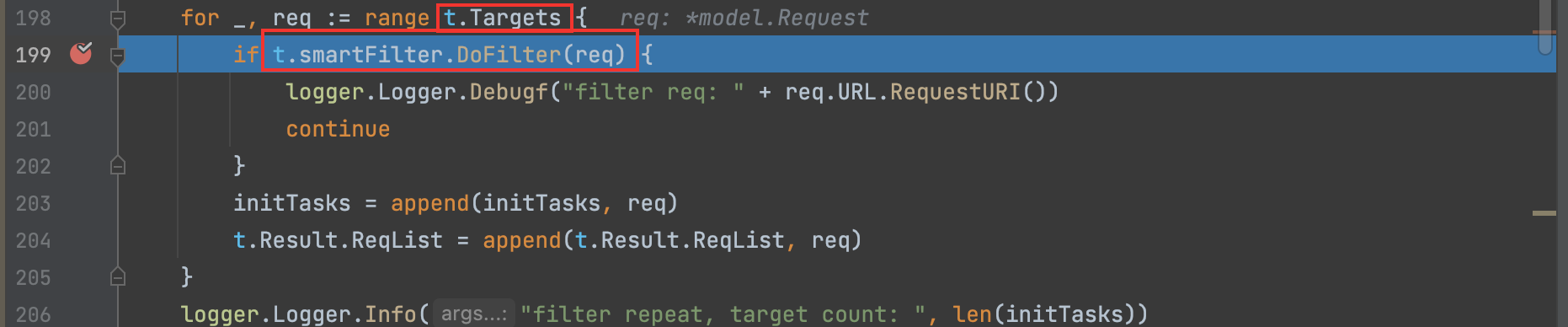
5)去重筛选出有效的URL后将其传入到任务池(协程实现)。
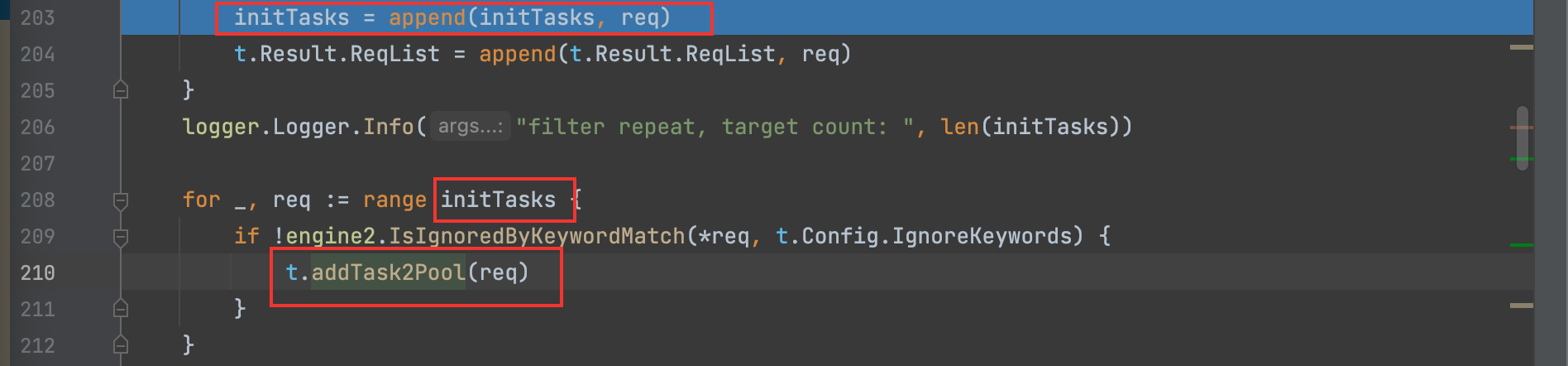
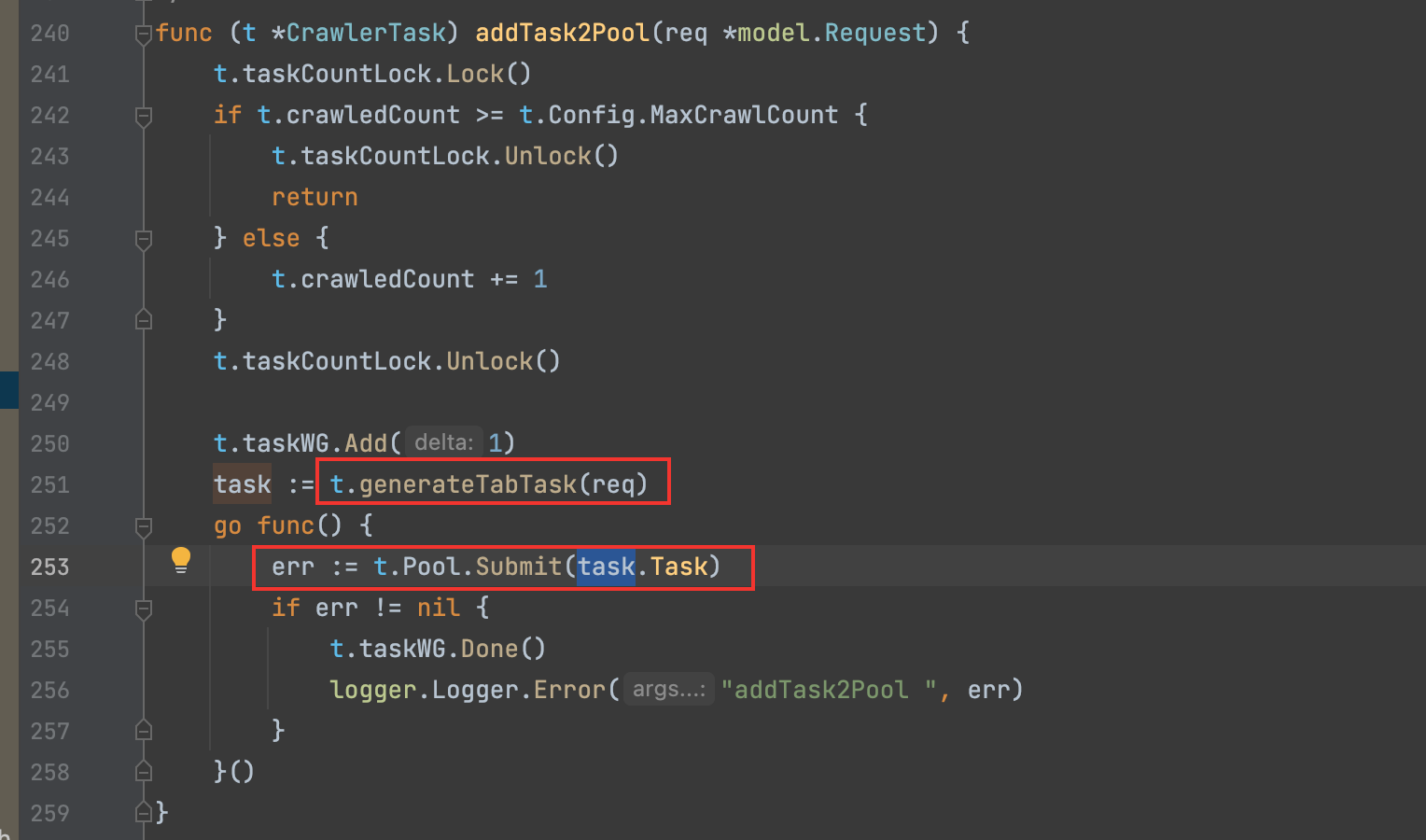
6)协程执行的单元函数Task,先初始化浏览器的参数设置,然后获取结果tab.ResultList
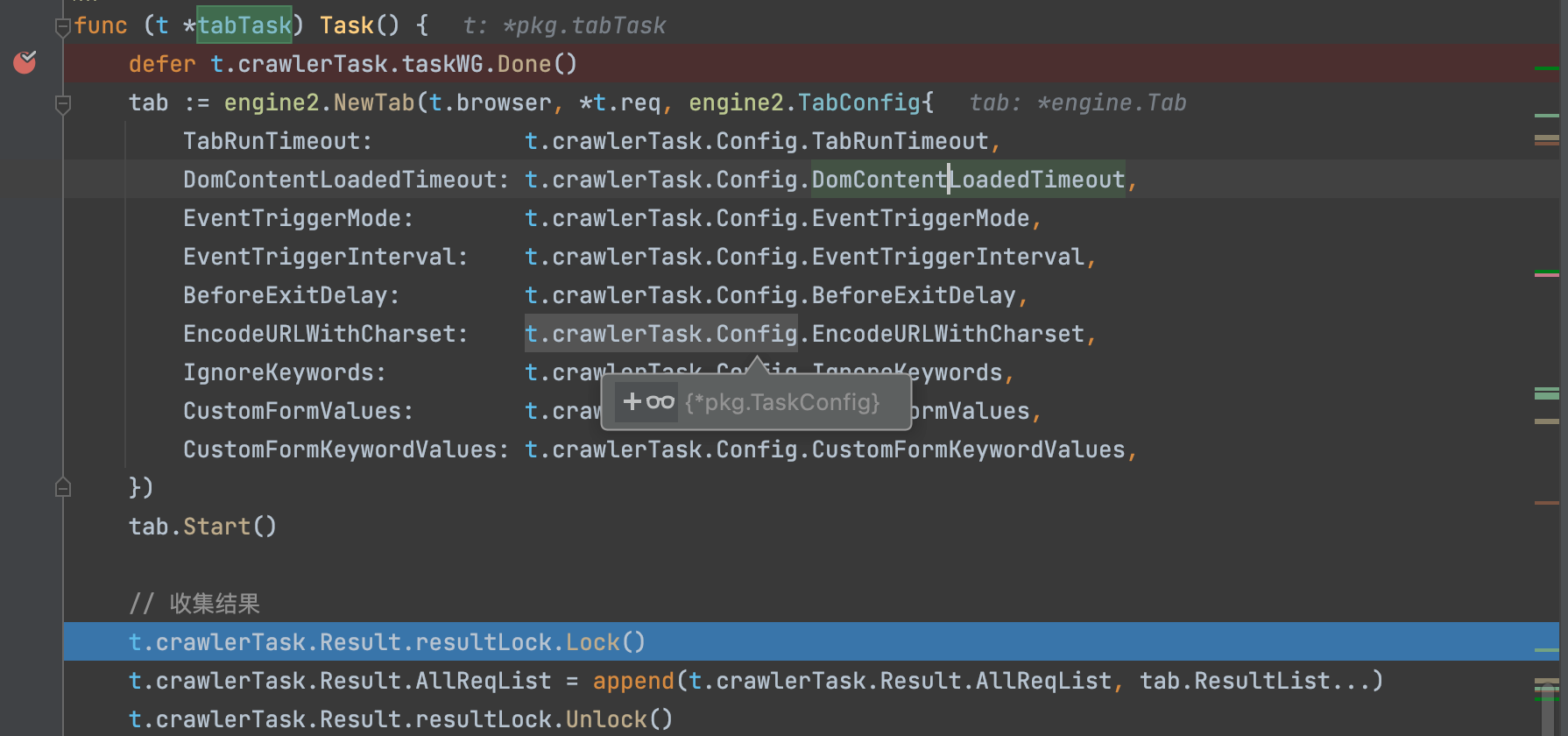
然后遍历通过扫描前期入口URL得到结果tab.ResultList,根据用户的过滤设置(simple/smart/strict三种模式),这里主要是区分第一种和最后两种,过滤出不重复的URL后,最后通过t.crawlerTask.addTask2Pool(req)放回到协程任务池,进行新的一轮爬取。
程序执行流程示意图如下:
0x03 URL去重
从0x02的分析可知,URL去重模块分别在入口URL和扫描时产生的新URL都会调用到,如果URL去重模块做得好,可以大大地减少爬虫的任务量,减少递归次数,并且有效保证URL的有效率。结合自己对Crawlergo的使用体验,Crawlergo的URL去重模块是比较优秀值得一探究竟的。
0x3.1 过滤静态资源
跟进smart_filter.go的DoFilter处理逻辑:
开始先通过SimpleFilter.DoFilter过滤掉静态资源,看下这部分怎么处理。

初始化一个集合数据结构,然后判断域名是否需要过滤,然后利用集合数据结构判断是否已经重复,如果没重复,则继续向下判断是否为静态资源进行过滤。
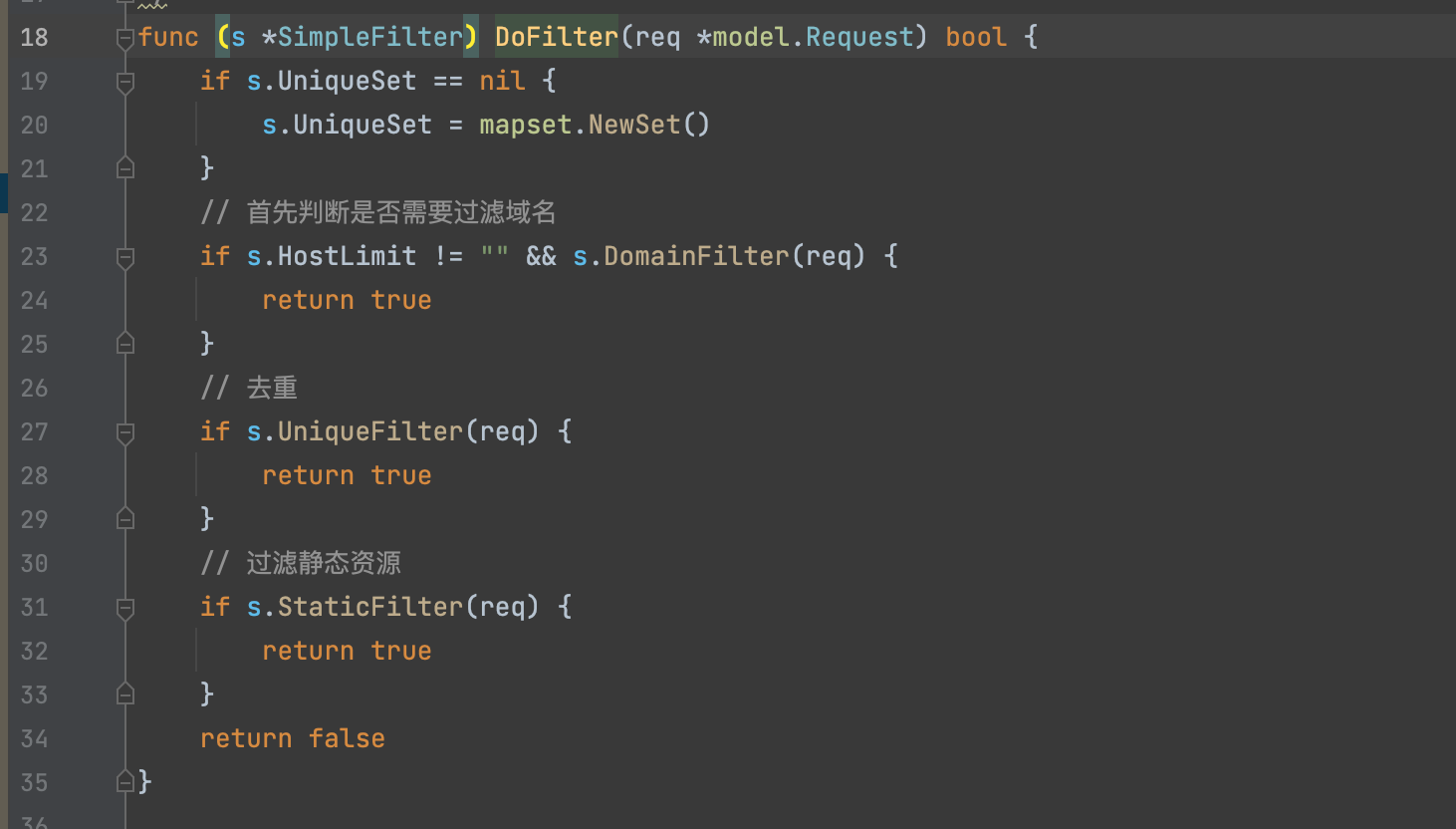
在这个过程,整体URL简单去重的思路UniqueFilter,通过判断UniqueSet集合是否包含了请求的req.UniqueId()这个特征来判断请求是否重复。
func (s *SimpleFilter) UniqueFilter(req *model.Request) bool {
if s.UniqueSet == nil {
s.UniqueSet = mapset.NewSet()
}
if s.UniqueSet.Contains(req.UniqueId()) {
return true
} else {
s.UniqueSet.Add(req.UniqueId())
return false
}
}
针对请求的数据生成一个哈希特征,Crawlergo分别提取了请求方法、URL、请求数据,甚至后端请求重定向这些维度的数据进行md5生成,用于一一标识对应的请求。(这是一种独特的做法)
func (req *Request) NoHeaderId() string {
return tools.StrMd5(req.Method + req.URL.String() + req.PostData)
}
func (req *Request) UniqueId() string {
if req.RedirectionFlag {
return tools.StrMd5(req.NoHeaderId() + "Redirection")
} else {
return req.NoHeaderId()
}
}
关于静态资源的判断,Crawlergo采取了通过判断后缀的方式,先生成一个可标记常见静态资源后缀的map类型,然后用请求URL的后缀作为键值进行过滤。
func (s *SimpleFilter) StaticFilter(req *model.Request) bool {
if s.UniqueSet == nil {
s.UniqueSet = mapset.NewSet()
}
// 首先将slice转换成map
extMap := map[string]int{}
staticSuffix := append(config.StaticSuffix, "js", "css", "json")
for _, suffix := range staticSuffix {
extMap[suffix] = 1
}
if req.URL.FileExt() == "" {
return false
}
if _, ok := extMap[req.URL.FileExt()]; ok {
return true
}
return false
}
0x3.2 打标记
过滤完静态资源后,通过打标记将符合某种特征的URL一般化,再进行过滤。
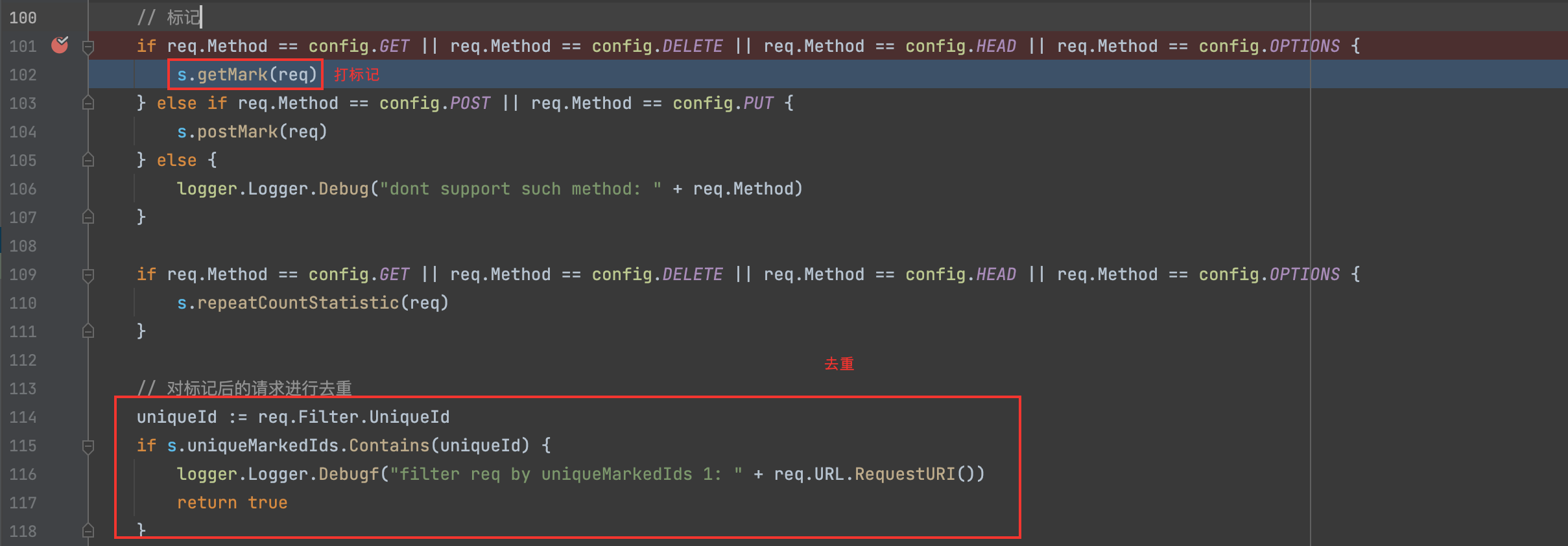
通过跟进getMark函数,打标记的过程,
func (s *SmartFilter) getMark(req *model.Request) {
// 首先是解码前的预先替换
todoURL := *(req.URL)
todoURL.RawQuery = s.preQueryMark(todoURL.RawQuery)
// 依次打标记
queryMap := todoURL.QueryMap()
queryMap = s.markParamName(queryMap)
queryMap = s.markParamValue(queryMap, *req)
markedPath := s.MarkPath(todoURL.Path)
// 计算唯一的ID
var queryKeyID string
var queryMapID string
if len(queryMap) != 0 {
queryKeyID = s.getKeysID(queryMap)
queryMapID = s.getParamMapID(queryMap)
} else {
queryKeyID = ""
queryMapID = ""
}
pathID := s.getPathID(markedPath)
req.Filter.MarkedQueryMap = queryMap
req.Filter.QueryKeysId = queryKeyID
req.Filter.QueryMapId = queryMapID
req.Filter.MarkedPath = markedPath
req.Filter.PathId = pathID
// 最后计算标记后的唯一请求ID
req.Filter.UniqueId = s.getMarkedUniqueID(req)
}
计算唯一请求ID这个特征来源于:请求方法+参数特征(key+value)+路径特征+请求host+Fragment,甚至如果URL没有Path和参数的时候,https也作为一个特征,然后将特征字符串进行哈希得到一个32位的md5,方便比较。
/**
计算标记后的唯一请求ID
*/
func (s *SmartFilter) getMarkedUniqueID(req *model.Request) string {
var paramId string
if req.Method == config.GET || req.Method == config.DELETE || req.Method == config.HEAD || req.Method == config.OPTIONS {
paramId = req.Filter.QueryMapId
} else {
paramId = req.Filter.PostDataId
}
uniqueStr := req.Method + paramId + req.Filter.PathId + req.URL.Host
if req.RedirectionFlag {
uniqueStr += "Redirection"
}
if req.URL.Path == "/" && req.URL.RawQuery == "" && req.URL.Scheme == "https" {
uniqueStr += "https"
}
if req.URL.Fragment != "" && strings.HasPrefix(req.URL.Fragment, "/") {
uniqueStr += req.URL.Fragment
}
return tools.StrMd5(uniqueStr)
}
0x3.3 阈值去重
打完标记后,代码逻辑没有直接进行去重,而是将URL数量统计,用于后续根据阈值来去重。

对于阈值的计算,Crawlergo作者并没有对POST的请求进行统计,个人猜测应该是作者根据大量的实践经验,发现相似的无效请求大多数都是来自GET请求,至于忽略POST请求的原因:一方面确实是少,另一方面爬虫触发POST请求的能力也确实有限。
跟进去
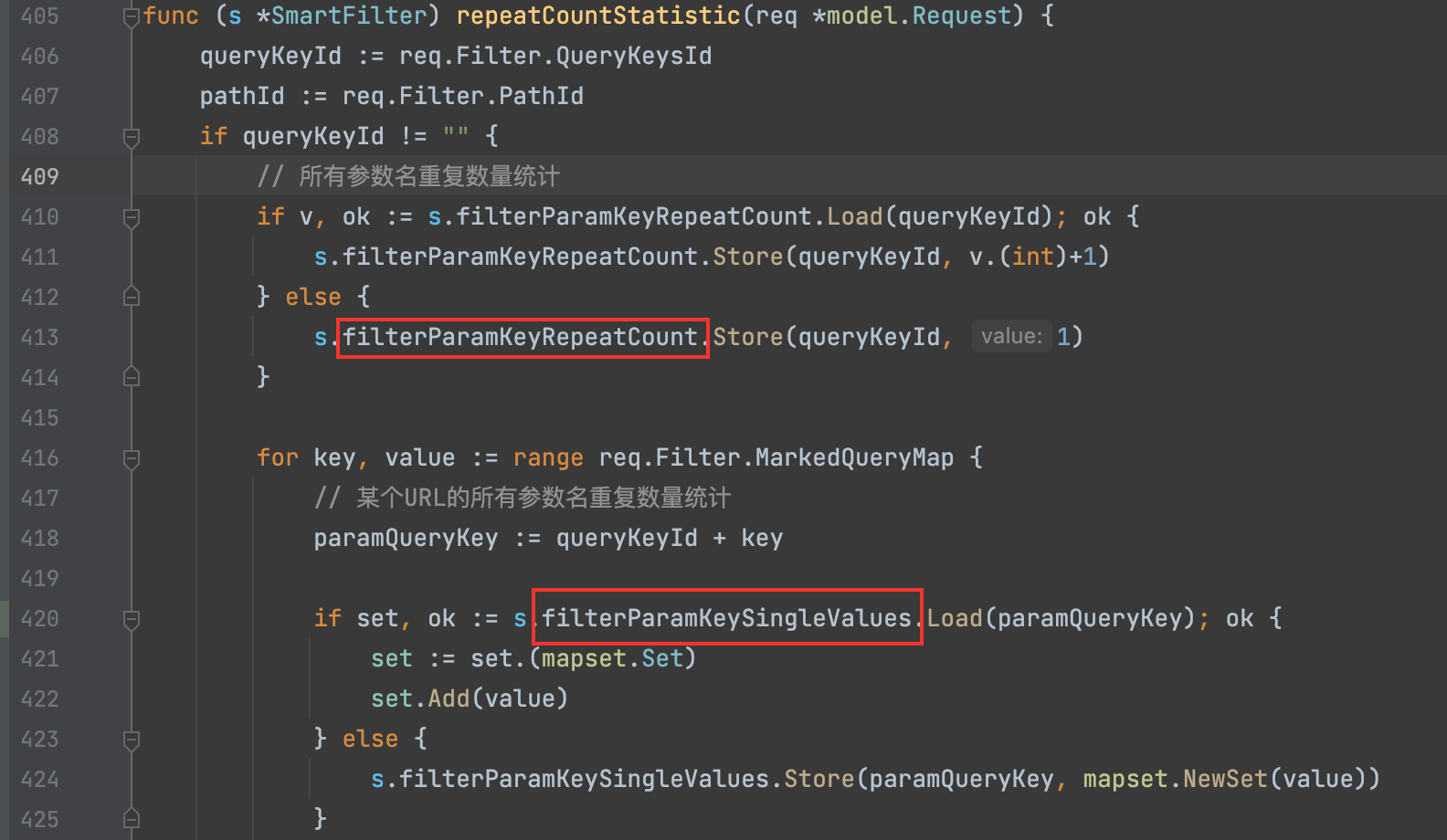
主要统计了下面的信息
filterParamKeyRepeatCount //所有参数名重复数量统计
filterParamKeySingleValues // 某个queryKeyId里某个参数出现的次数
filterParamKeyAllValues //某个参数重复数量统计
filterPathParamEmptyValues //PATH下的空值参数名个数
filterPathParamKeySymbol //某path下的参数值去重标记出现次数统计
filterParentPathValues //相同父级path下的path的个数
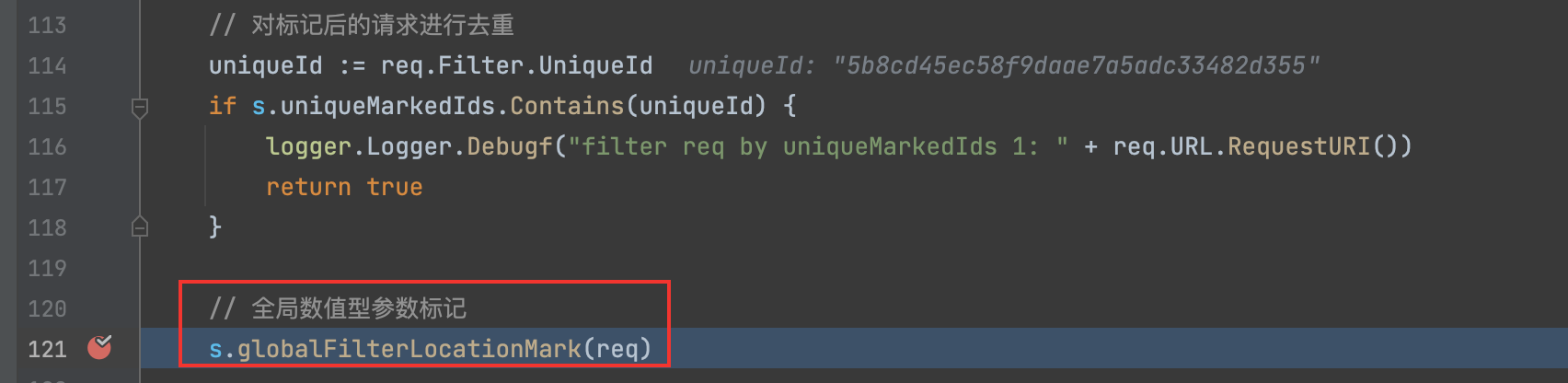
0x3.4 去重标记请求
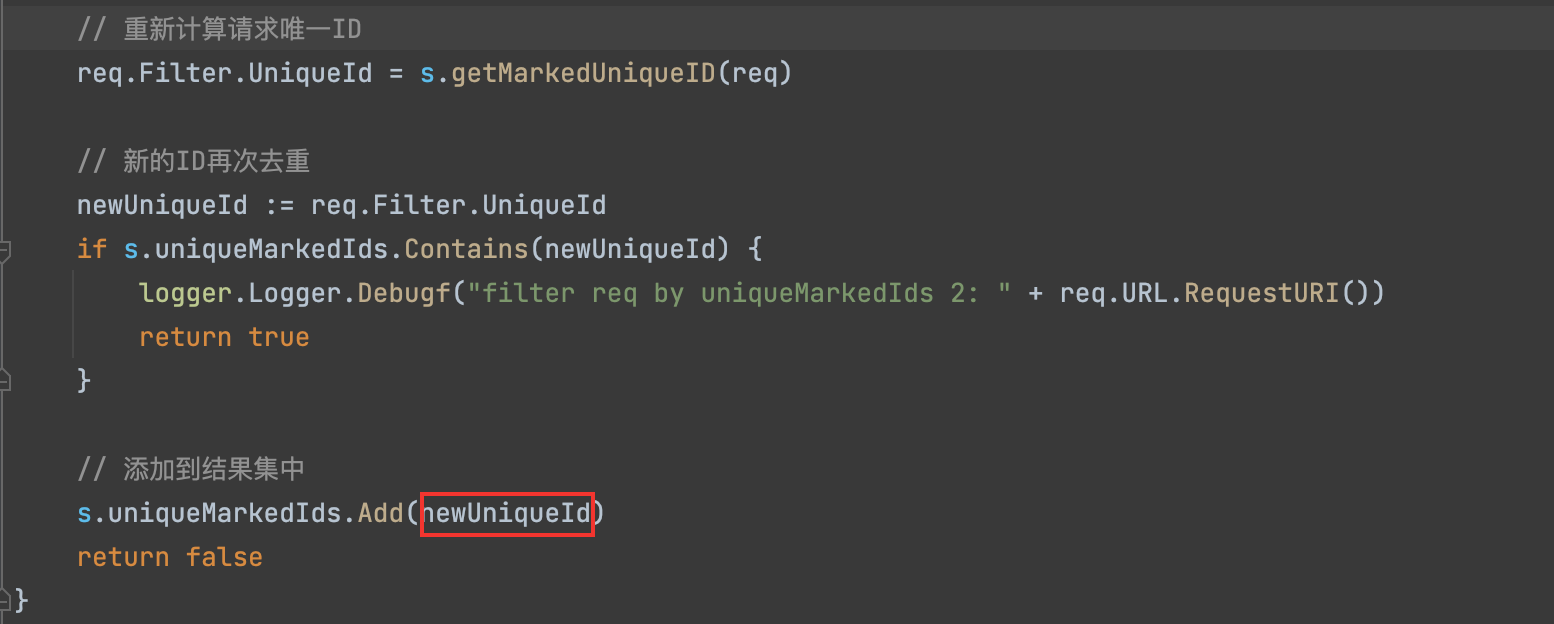
uniqueId := req.Filter.UniqueId
if s.uniqueMarkedIds.Contains(uniqueId) {
logger.Logger.Debugf("filter req by uniqueMarkedIds 1: " + req.URL.RequestURI())
return true
}
uniqueMarkedIds存放标记后的URLUniqueId, 若标记后算出来已经有存在的,则需要过滤掉。

0x3.5 全局数值型参数
121 Line 向下执行这个函数,分析完后,恕笔者愚钝,真不知道该函数想解决什么问题。
/**
全局数值型参数过滤
*/
func (s *SmartFilter) globalFilterLocationMark(req *model.Request) {
name := req.URL.Hostname() + req.URL.Path + req.Method
if req.Method == config.GET || req.Method == config.DELETE || req.Method == config.HEAD || req.Method == config.OPTIONS {
for key := range req.Filter.MarkedQueryMap {
name += key
// name: qq.com/user/signup.phpGETabc
if s.filterLocationSet.Contains(name) {
req.Filter.MarkedQueryMap[key] = CustomValueMark
}
}
} else if req.Method == config.POST || req.Method == config.PUT {
for key := range req.Filter.MarkedPostDataMap {
name += key
if s.filterLocationSet.Contains(name) {
req.Filter.MarkedPostDataMap[key] = CustomValueMark
}
}
}
}
这让我觉得很困惑,因为filterLocationSet集合里面的值是爬虫填充表单的时候获取到的value值
req.URL.Hostname() + req.URL.Path + req.Method + key

回到globalFilterLocationMark函数的处理,就变成
name := req.URL.Hostname() + req.URL.Path + req.Method + key1 + key2 + ...
无论如何,s.filterLocationSet.Contains(name)只要这个判断为真,那么执行下面这个语句就是多余的。
req.Filter.MarkedQueryMap[key] = CustomValueMark
0x3.6 处理阈值超标
前面0x3.3我们保存了URL各个状态的统计信息。
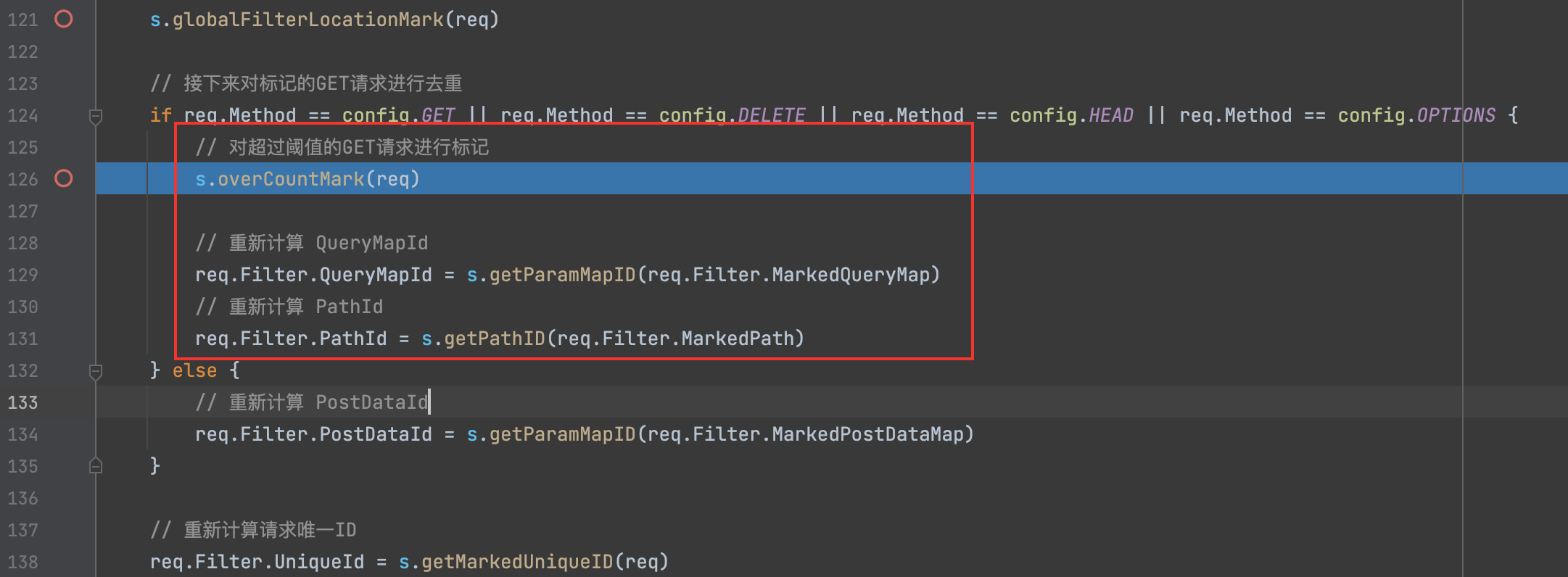
跟进去
1)某个URL的所有参数名重复数量超过阈值 且该参数有超过三个不同的值 则打标记
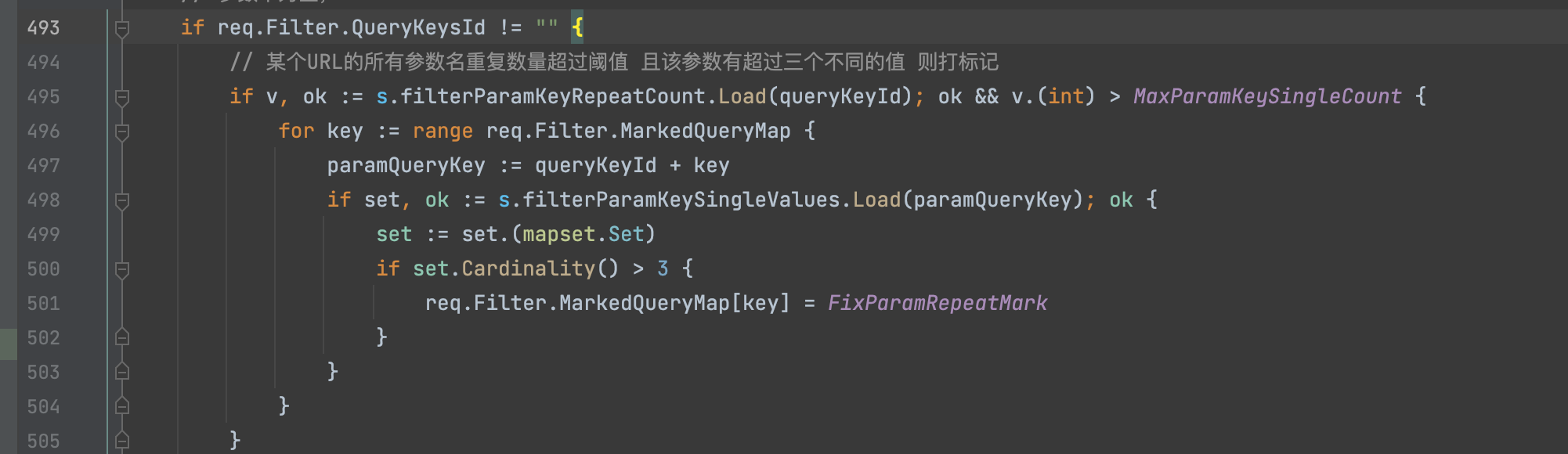
如果一个URL中的参数key的特征多次在其他URL中出现,这里阈值默认是大于8次,大于的话,需要比较参数特征,如果出现有3种以上的参数特征,比如
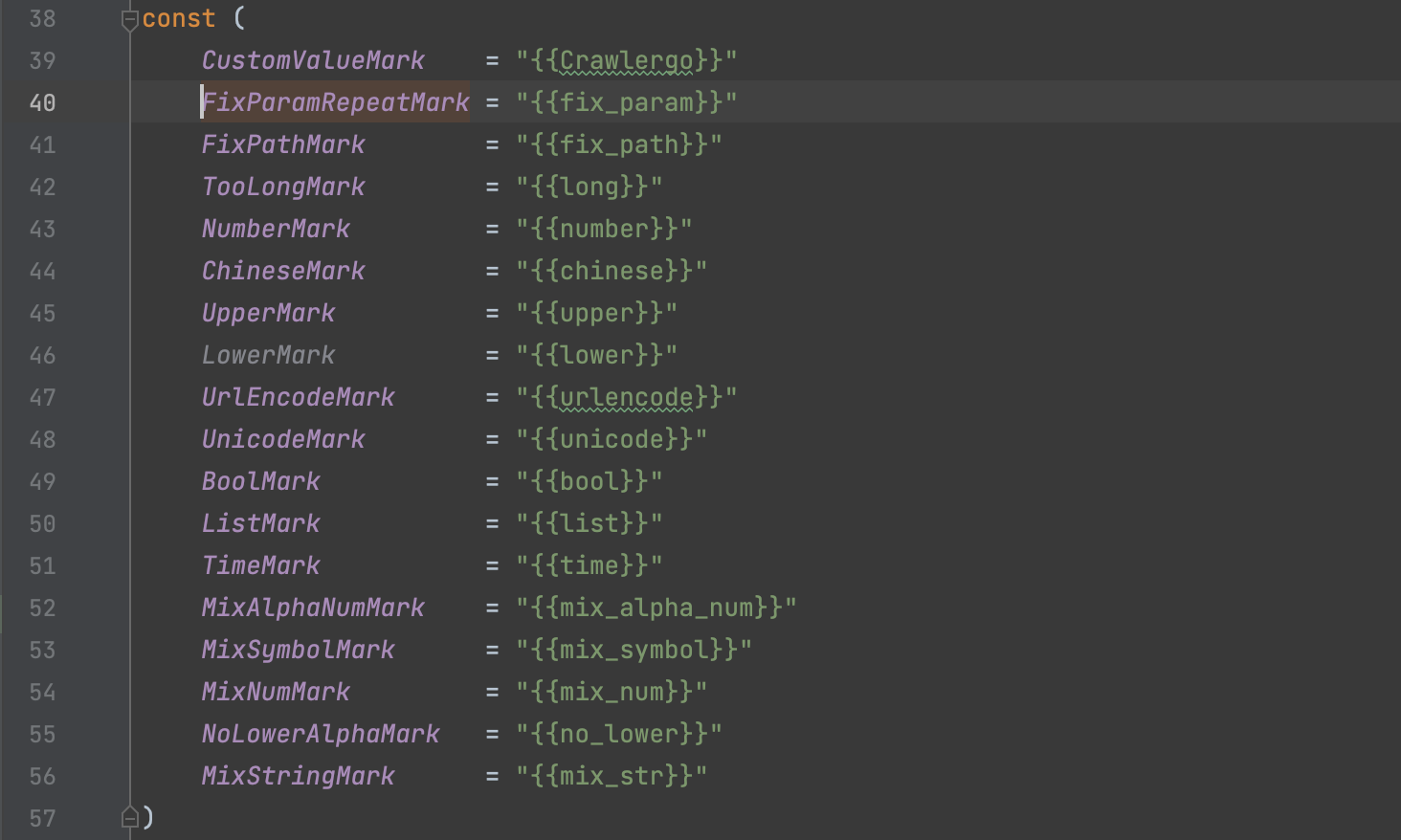
那么就需要将这些特征给统一成FixParamRepeatMark,达到进一步过滤重复相似URL的效果。
第一步针对的是queryKeyId,也就是一个URL所有参数提取出来的特征,针对的是一个整体达到一个阈值标准,然后再针对其中每一个的参数对应的值出现的次数进行二次标记。
...
那么key:a就会被重新标记。
2) 所有URL中,某个参数不同的值出现次数超过阈值,打标记去重
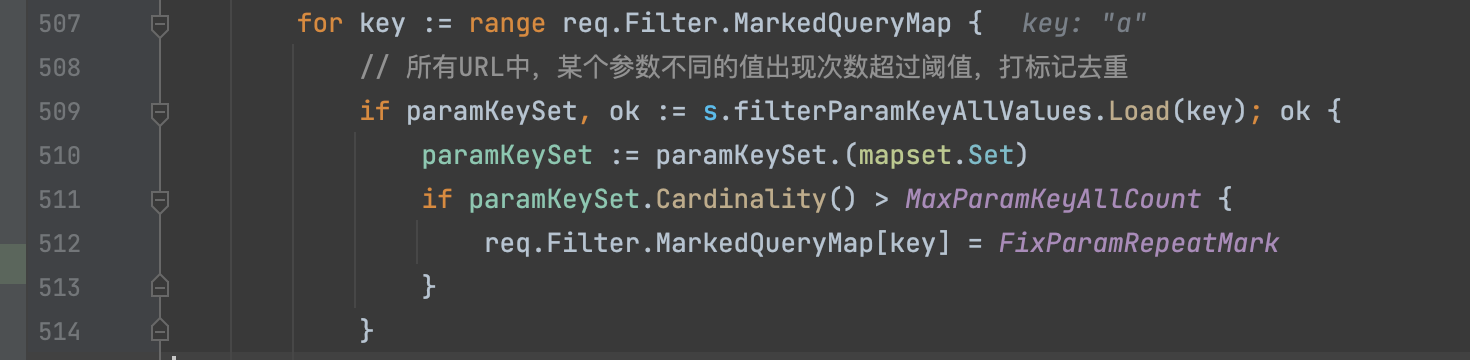
第二步针对的是URL的某个key,也就是某个参数出现不同的值的次数进行过滤
...
那么key:a就会被重新标记。
3) 某个PATH的GET参数值去重标记出现次数超过阈值,则对该PATH的该参数进行全局标记

第三步就是将路径与参数绑定在了一起
...
那么key: a 就会被重新标记
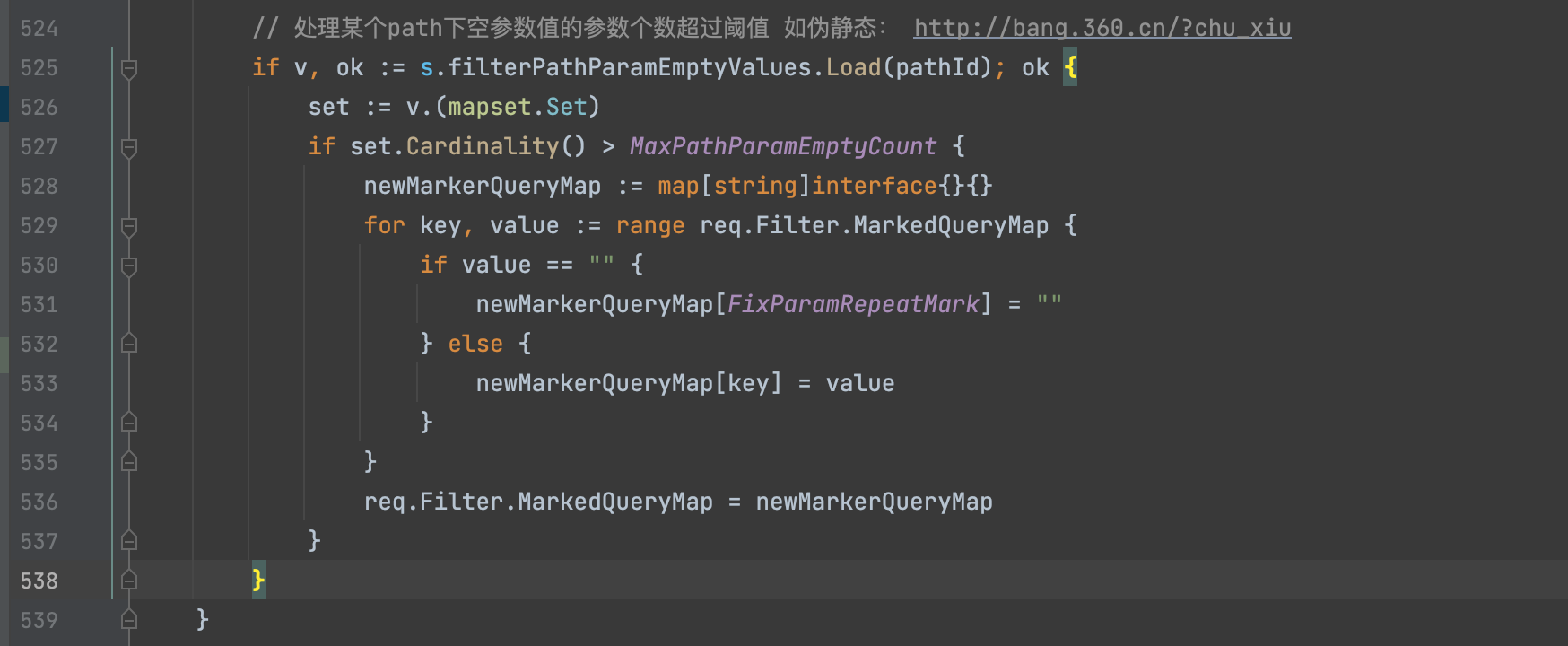
4)处理某个path下空参数值的参数个数超过阈值
5) 处理伪静态
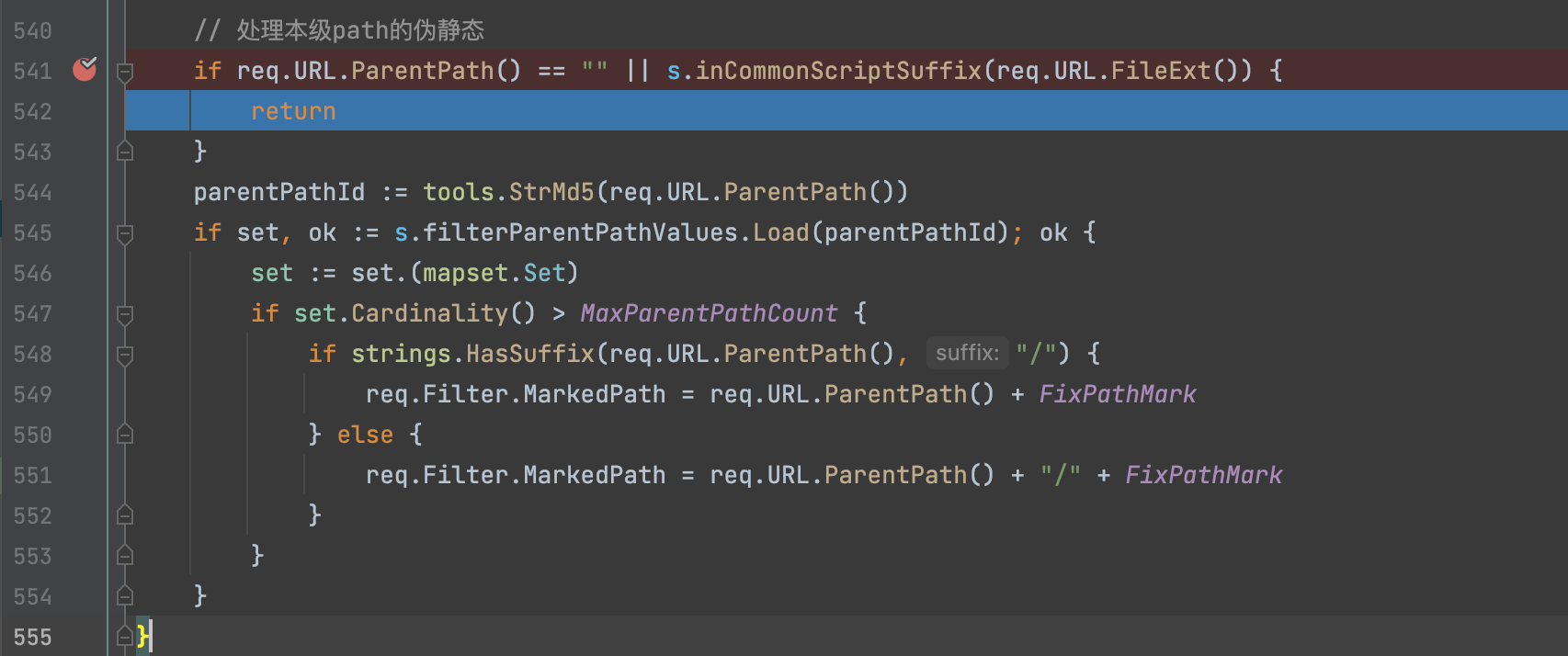
如果不是常见的php、asp、jsp、asa后缀结尾的话,那么会统计父级目录下的URL出现次数是否超过了32次,超过的话,会将当前Path进行标记:
/user/signup.php -> /user/\{\{fix_path\}\}
6)重新计算第二次标记=>UniqueID过滤
0x04 学习思路
Crawlergo的去重思路的核心在于: 通过打标记一般化,控制特征数目,降低运算复杂度
一般去重的暴力思路就是: n^2
按照Crawlergo的思路,举一个例子:
http://baidu.com/?a=1
http://baidu.com/?a=2
http://baidu.com/?a=3
http://baidu.com/?a=4
http://baidu.com/?a=5
http://baidu.com/?a=你
http://baidu.com/?a=好
现在给你URL,http://baidu.com/?a=hi,让你做一个去重,那么肯定是需要遍历7次的,如果再给你一个URL你又要遍历7次,但是如果我们第一次遍历的时候打上了标记,形成一个标记集合。
[http://baidu.com/?a=\{\{number\}\}, http://baidu.com/?a=\{\{chinese\}\}]
那么我们第二次的话,只需要遍历2次就行,并且能有效的达到初步的相似URL去重的功能,一举两得。
第二: 需要比较的集合是从小开始逐渐变大的
这种思想是非常有可取之处的,且处处都能看到这种影子,所以URL去重的速度,都是先快后慢,前期先放入一些例子到某个容器中,然后取一个例子判断是否在容器中,如果不在,则添加进去,从而达到一个去重的效果,这样也可以降低复杂度。
第三:丰富的标记规则
足足定义18种基于正则的类型,甚至对伪静态也增加了规则判断。
CustomValueMark= "\{\{Crawlergo\}\}"
FixParamRepeatMark = "\{\{fix_param\}\}"
FixPathMark= "\{\{fix_path\}\}"
TooLongMark= "\{\{long\}\}"
NumberMark = "\{\{number\}\}"
ChineseMark= "\{\{chinese\}\}"
UpperMark = "\{\{upper\}\}"
LowerMark = "\{\{lower\}\}"
UrlEncodeMark = "\{\{urlencode\}\}"
UnicodeMark= "\{\{unicode\}\}"
BoolMark = "\{\{bool\}\}"
ListMark = "\{\{list\}\}"
TimeMark = "\{\{time\}\}"
MixAlphaNumMark= "\{\{mix_alpha_num\}\}"
MixSymbolMark = "\{\{mix_symbol\}\}"
MixNumMark = "\{\{mix_num\}\}"
NoLowerAlphaMark = "\{\{no_lower\}\}"
MixStringMark = "\{\{mix_str\}\}"
// 常见的值一般为 大写字母、小写字母、数字、下划线的任意组合,组合类型超过三种则视为伪静态
} else {
count := 0
if alphaLowerRegex.MatchString(valueStr) {
count += 1
}
if alphaUpperRegex.MatchString(valueStr) {
count += 1
}
if numberRegex.MatchString(valueStr) {
count += 1
}
if strings.Contains(valueStr, "_") || strings.Contains(valueStr, "-") {
count += 1
}
if count >= 3 {
markedParamMap[key] = MixStringMark
}
}
第四:基于阈值二次过滤
单纯依靠标记进行过滤的话,笔者之前也写过类似的思想,可是在实践的时候发现,URL在真实情况的规则有非常多且很难用正则表达式去准确定义出来。Crawlergo为了避免出现同样的由于规则覆盖不全,爬虫出现大量URL的情况,选择基于Path、基于参数等一些参数进行阈值限制实现在广泛程度达到过滤效果,实现有效地控制爬取到的有效URL在一个可接受的数量区间中,当然这种方式,可能会导致"误杀某些URL",但是这也不失为一种值得去接纳的处理方式。
0x05 个人看法
目前来说,解决大量URL相似去重这个问题,对于拥有无限扫描节点和无限扫描能力的企业扫描器来说,可能算不上什么问题,全都扫一次就完事了,根本不会漏扫,这是最稳的,但是,对于一些自研的资源有限的扫描器来说,URL去重是一个值得去花时间攻克的问题,毕竟60W URL经过去重后只剩下3W URL再丢给扫描器来说完全就是两个概念,但是实际上60WURL真实有效URL数目是不到3k的,所以说优化空间还有很大,如何编写一个高效且准确,最重要还是要快的URL去重脚本,是一个需要大量实践基础+拥有好的想法+具备工程化思想的难题,关注我,一起交流学习吧。
0x06 参考链接
- 本文作者: xq17
- 本文来源: 奇安信攻防社区
- 原文链接: https://forum.butian.net/share/1764
- 版权声明: 除特别声明外,本文各项权利归原文作者和发表平台所有。转载请注明出处!

