
Web 指纹识别虽然已经是老生常谈的话题,但其在漏洞挖掘 / 漏洞治理的过程中仍然有着举足轻重的作用。本文中将着重分析下指纹识别体系建设的一些维度和实现思路。
0x01 写在前面
Web 指纹识别虽然已经是老生常谈的话题,但其在漏洞挖掘 / 漏洞治理的过程中仍然有着举足轻重的作用:
- 红军:资产建模、漏洞应急时风险的快速收敛
- 蓝军:信息收集、漏洞挖掘过程中的针对组件漏洞的精准
- 空间测绘
- ...
实际落地时,无论甲方场景还是乙方场景,基本都是构建指纹体系,通过对指纹库的持续运营实现。指纹库通常由【Web 组件】 + 【识别该组件的规则】组成,识别过程通过解析流量,查找匹配的规则,输出指纹。本文中将着重分析下指纹识别体系建设的一些维度和实现思路。
大纲:
0x02 识别模式
主动识别
主动识别逻辑比较简单。主动访问特定的 URL ,从响应中提取特征信息,从而判定是否为某个 Web 组件。
例如:识别OFBiz,可主动访问/myportal/control/main,检查 Cookie 和响应 body 是否包括 OFBiz /ofbiz 等字样。

被动识别
被动接收所有流量,也就是说并不会额外发送请求。每条响应再去逐一匹配指纹库的每条规则。
请求数据源可来源于:
- 爬虫:基于
Chrome的爬虫,为了应对 js 动态页面 - 浏览器代理插件
- 对于甲方场景,可直接识别流量镜像
这里有几个场景急需解决:
- 减少发包次数:消息队列记录已发的包。
- 流量去重:被动识别的匹配次数是
响应数 * 规则数。为了降低轮训匹配的大量消耗,可以对爬虫 / 镜像中的流量进行去重,可大幅度减少要检测的响应数。对于相似流量比对,可参考腾讯src的策略。 - 资源调度:请求、去重、识别各模块使用消息队列通信,便于水平扩展。
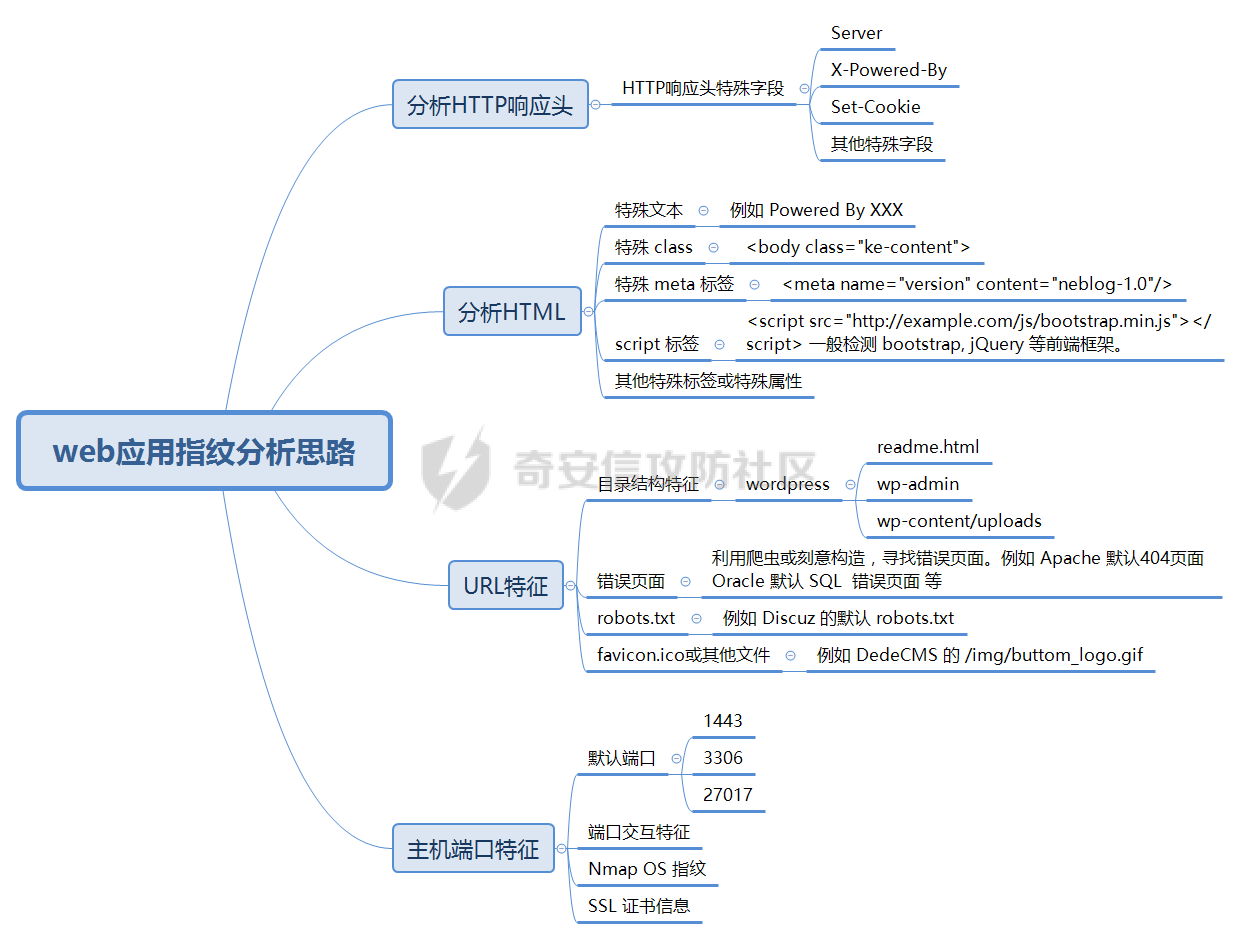
0x03 指纹特征维度
获取响应后可通过以下维度进行特征匹配。多个维度可以同时设定特征规则,最后通过加权计算后,输出指纹识别结果。
1.分析HTTP响应头
根据响应头中的信息进行匹配。重点关注 HTTP 的以下响应头,如:
ServerX-Powered-bySet-Cookie- 其他可能带有明显特征的头,例如
WWW-Authenticate
2.分析HTML
分析
- 特殊文本。响应的HTML中有明显的关键字。例如:
Powered By XXX - CSS 类选择器。例如:
<body class="ke-content"> - Meta 标签。例如:
<meta name="version" content="neblog-1.0"> - script标签。一般检测bootstrap、jQuery等前端框架。例如:
<script src="http://example.com/js/bootstrap.min.js"></script> - 其他特殊字段
3.分析URL特征
- 特有的目录结构特征。例如
wordpress默认带有readme.html,以及wp-admin、wp-content/uploads等目录;weblogic可能使用wls-wsat目录 - 错误页面。识别已有的错误页面响应,或主动构造错误页面,根据报错信息来判断。例如
Apache默认的404页面、Tomcat的报错页面、Mysql默认SQL错误信息 robots.txt。例如Discuz的默认robots.txt- 带有明显特征文件的
Hash(通常计算MD5)。例如:通用的特征文件,如favicon.ico、css、logo.ico、js等文件一般不会修改;其他带有明显特征的文件。例如Dedecms的/img/buttom_logo.gif
4.主机端口特征
- 默认端口。例如1443、306、27017
- 端口交互特征。例如获取banner
- 借助 nmap 操作系统指纹
- SSL 证书信息
0x04 一些想法
指纹识别看似简单的领域,其实深入研究后还是有很多值得钻研的点的,例如:
- 未知指纹的自动特征提取
- 流量建模提取共性
- 不同维度的权重
- 指纹字典的加载权重:历史记录命中率高的先加载
- 提升性能:任务动态调度、及时中断、异常处理等
如果有师傅有任何问题,或者想参与到指纹识别模块的开发中来,欢迎与我联系。
- 本文作者: jweny
- 本文来源: 奇安信攻防社区
- 原文链接: https://forum.butian.net/share/728
- 版权声明: 除特别声明外,本文各项权利归原文作者和发表平台所有。转载请注明出处!

