
写在前面相信大家一定对源码泄露并不陌生,这里也不赘述这个漏洞的原理和危害了,网上一搜也都有好多好多,看都看不完~~~那今天这里我们讲啥呢?那就直入主题吧~今天这里我就贴出我自己参…
写在前面
相信大家一定对源码泄露并不陌生,这里也不赘述这个漏洞的原理和危害了,网上一搜也都有好多好多,看都看不完~~~
那今天这里我们讲啥呢?那就直入主题吧~今天这里我就贴出我自己参考的加上自己写的fofa爬虫 + 源码泄露PoC之梦幻联动,希望能对大家有帮助。我也只是个菜鸡,如果有不足请指正出来,一起学习~
fofa爬虫
因为这里我没钱,充不起会员,所以其中只能爬1—5页,应该能满足大部分人的需求了~反正我满足了, 因为我没钱,呜呜呜
import requests
from lxml import etree
import random
import time
import urllib
import base64
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/54.0.2840.99 Safari/537.36",
}
#这里的代理IP需要自己去爬取或者添加
proxylist = [
{'HTTP': '112.84.54.35:9999'},
{'HTTP': '175.44.109.144:9999'},
{'HTTP': '125.108.119.23:9000'}
]
proxy = random.choice(proxylist)
def loadpage(url,begin,end):
for page in range(begin,end+1):
print("正在爬取第"+str(page)+"页:")
fullurl = url+"&page="+str(page)
response = requests.get(fullurl,headers=headers,proxies=proxy).text
html = etree.HTML(response)
req = html.xpath('//div[@class="fl box-sizing"]/div[@class="re-domain"]/a[@target="_blank"]/@href')
result = '\n'.join(req)
with open(r'url.txt',"a+") as f:
f.write(result+"\n")
print("----------------第"+str(page)+"页已完成爬取----------------"+'\n')
if __name__ == '__main__':
q = input('请输入关键字,如 "app="xxx" && country="CN":等等')
begin = int(input("请输入开始页数 最小为1:"))
end = int(input("请输入结束页数 最大为5:"))
cookie = input("请输入你的Cookie:")
cookies = '_fofapro_ars_session='+cookie+';result_per_page=20'
headers['cookie'] = cookies
url = "https://fofa.so/result?"
key = urllib.parse.urlencode({"q":q})
key2 = base64.b64encode(q.encode('utf-8')).decode("utf-8")
url = url+key+"&qbase64="+key2
loadpage(url,begin,end)
time.sleep(5)
源码泄露PoC
其中加入time.sleep()也是为了安全考虑吧,慢一点就慢一点,稳就行了
import requests
import time
with open("url.txt", 'r') as temp:
for url in temp.readlines():
url = url.strip('\n')
with open("web.txt", 'r') as web:
webs = web.readlines()
for web in webs:
web = web.strip()
u = url + web
r = requests.get(u)
# print("url为:"+u)
print("url为:" + u + ' ' + "状态为:%d" %r.status_code)
time.sleep(2) #想睡多久看自己~
w = open('write.txt', 'w+')
for web in webs:
web = web.strip()
u = url + web
r = requests.get(u)
w.write("url为:" + u + ' ' + "状态为:%d" %r.status_code + '\n')
梦幻联动
第一步
先把web.txt准备好,里面放上自己想跑的目录,这里截取部分我的txt吧。因为我的txt也很简陋,所以这里就不全贴出来了,想要的私聊我~

第二步
用fofa爬虫前首先我们需要获得其中的_fofapro_ars_session。
先要打开fofa,进行登录

然后去cookie中找到它,复制下来

然后就可以用fofa爬虫爬取我们所需要的url了,就像这样

然后按下回车,就会进行爬取,然后导入到我们的url.txt中,大家可以在这个文件中进行查看,也可以直接在PyCharm中查看

这里如果不放心可以自己在fofa中搜索一遍进行比对,发现是一模一样的

下一步就是开始启动我们的源码泄露PoC了
这里直接Run它
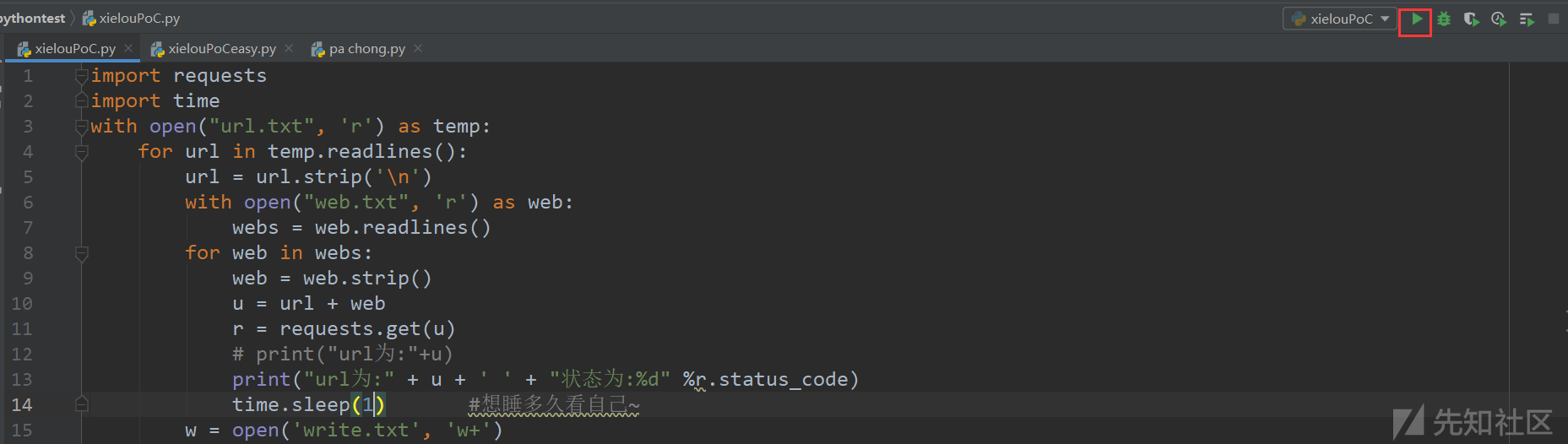
然后就是进入等待阶段。等待的时候可以泡上杯咖啡喝,啊,舒服~
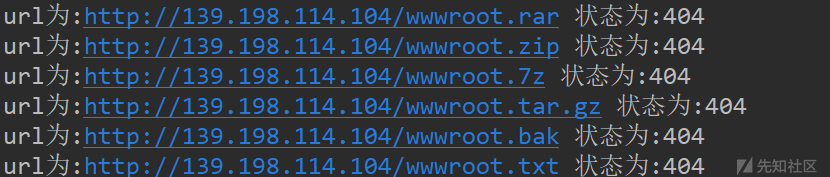
结束后,这份最后导出来的是叫write.txt。大家可以直接在PyCharm中看,也可以打开write.txt中查看。我相信大家都是会看状态码的,这里我就不赘述了

测试结束
福利
这里如果是只想测试一个网站,我这里附上另外一个PoC,大家可以用下面这个PoC,这里就不给大家演示了,跟上面的差不多,只是这份最后导出来的是write easy.txt
import requests
import time
url='' #想扫哪个网站自行将url粘贴到这里
with open("web.txt", 'r') as web:
webs = web.readlines()
for web in webs:
web = web.strip()
u = url + web
r = requests.get(u)
#print("url为:"+u)
print("url为:" + u + ' ' + "状态为:%d"%r.status_code)
time.sleep(2) #想睡多久看自己~
w = open('write easy.txt', 'w+')
for web in webs:
web = web.strip()
u = url + web
r = requests.get(u)
w.write("url为:" + u + ' ' + "状态为:%d"%r.status_code + '\n')
- 本文作者: Johnson666
- 本文来源: 奇安信攻防社区
- 原文链接: https://forum.butian.net/share/155
- 版权声明: 除特别声明外,本文各项权利归原文作者和发表平台所有。转载请注明出处!

