
这是一套全然不同的架构。它拥有一套全然不同的指令集。从arm32 x86,x64到MIPS。从汇编走向另一种汇编。研究 分析 比较。从这篇文章开始
0x01 前言
这是一套全然不同的架构。
它拥有一套全然不同的指令集。
从arm32 x86,x64到MIPS。从汇编走向另一种汇编。
研究 分析 比较
从这篇文章开始
0x02 MIPS 概述
老规矩,上官方解释。
MIPS32的架构是一种基于固定长度的定期编码指令集,并采用导入/存储(load/store)数据模型。经改进,这种架构可支持高级语言的优化执行。在路由器中,经常使用的一种MIPS架构就是MIPS32。MIPS的系统结构及设计理念比较先进,其指令系统经过通用处理器指令体系MIPS I、MIPS II、MIPS III、MIPS IV、MIPS V,以及嵌入式指令体系MIPS16、MIPS32到MIPS64的发展。
总而言之,MIPS架构是一种支持高级语言执行的,arm32,x64等我们常见之外的又一种处理架构。
接下来,为了满足我们快速学习以便处理逆向题目的需求,从寄存器和汇编指令两个方面学习一下MIPS架构。
0x03 MIPS寄存器
MIPS32的指令中除了加载/存储指令以外,都使用寄存器或者立即数作为操作数,以便让编译器通过保持对寄存器内数据的频繁存取进一步优化代码的生成性能。
MIPS32寄存器分为两类:通用寄存器(GPR)和特殊寄存器。
通用寄存器
在MIPS体系结构中有32个通用寄存器,在汇编程序中,可以用编号$0~$31表示,也可以用寄存器的名字表示,如$sp、$t1、$ta等,如下图
| 编号 | 寄存器名称 | 寄存器描述 |
|---|---|---|
| 0 | zero | 第0号寄存器,其值始终为0.为0这个有用常数提供了一个简洁的编码形式 |
| 1 | $at | 保留寄存器 |
| 2~3 | $v0~v1 | values, 保存表达式或函数返回结果 |
| 4-7 | $a0~a3 | aruments, 作为函数的前4个参数 |
| 8~15 | $t0~$t7 | temporaries,供汇编程序使用的临时寄存器 |
| 16~23 | $s0~$s7 | saved values,子函数使用时需要先保存原寄存器的值 |
| 24~25 | $t8~t9 | temporaries, 供汇编程序的临时寄存器,补充$t0~t7 |
| 26~27 | $k0~$k1 | 保留,中断处理函数使用 |
| 28 | $gp | global pointer,全局指针 |
| 29 | $sp | stack pointer, 堆栈指针,指向堆栈的栈顶 |
| 30 | $fp | frame pointer, 保存栈指针 |
| 31 | $ra | return address, 返回地址 |
特殊寄存器
MIPS32架构中定义了3个特殊寄存器。PC(程序计数器)、HI(乘除结果高位寄存器)和LO(乘除结果低位寄存器)。在进行乘法运算时,HI和LO保存乘法的运算结果,其中HI存储高32位,LO存储低32位;而在进行除法运算时,HI保存余数,LO存储商。
0x04 MIPS 汇编指令
mips架构有一套自己的汇编语言体系,常有指令总结在下表中
| 指令 | 功能 | 应用实例 |
|---|---|---|
| LB | 从存储器中读取一个字节的数据到寄存器中 | LB R1, 0(R2) |
| LH | 从存储器中读取半个字的数据到寄存器中 | LH R1, 0(R2) |
| LW | 从存储器中读取一个字的数据到寄存器中 | LW R1, 0(R2) |
| LD | 从存储器中读取双字的数据到寄存器中 | LD R1, 0(R2) |
| L.S | 从存储器中读取单精度浮点数到寄存器中 | L.S R1, 0(R2) |
| L.D | 从存储器中读取双精度浮点数到寄存器中 | L.D R1, 0(R2) |
| LBU | 功能与LB指令相同,但读出的是不带符号的数据 | LBU R1, 0(R2) |
| LHU | 功能与LH指令相同,但读出的是不带符号的数据 | LHU R1, 0(R2) |
| LWU | 功能与LW指令相同,但读出的是不带符号的数据 | LWU R1, 0(R2) |
| SB | 把一个字节的数据从寄存器存储到存储器中 | SB R1, 0(R2) |
| SH | 把半个字节的数据从寄存器存储到存储器中 | SH R1,0(R2) |
| SW | 把一个字的数据从寄存器存储到存储器中 | SW R1, 0(R2) |
| SD | 把两个字节的数据从寄存器存储到存储器中 | SD R1, 0(R2) |
| S.S | 把单精度浮点数从寄存器存储到存储器中 | S.S R1, 0(R2) |
| S.D | 把双精度数据从存储器存储到存储器中 | S.D R1, 0(R2) |
| DADD | 把两个定点寄存器的内容相加,也就是定点加 | DADD R1,R2,R3 |
| DADDI | 把一个寄存器的内容加上一个立即数 | DADDI R1,R2,#3 |
| DADDU | 不带符号的加 | DADDU R1,R2,R3 |
| DADDIU | 把一个寄存器的内容加上一个无符号的立即数 | DADDIU R1,R2,#3 |
| ADD.S | 把一个单精度浮点数加上一个双精度浮点数,结果是单精度浮点数 | ADD.S F0,F1,F2 |
| ADD.D | 把一个双精度浮点数加上一个单精度浮点数,结果是双精度浮点数 | ADD.D F0,F1,F2 |
| ADD.PS | 两个单精度浮点数相加,结果是单精度浮点数 | ADD.PS F0,F1,F2 |
| DSUB | 两个寄存器的内容相减,也就是定点数的减 | DSUB R1,R2,R3 |
| DSUBU | 不带符号的减 | DSUBU R1,R2,R3 |
| SUB.S | 一个双精度浮点数减去一个单精度浮点数,结果为单精度 | SUB.S F1,F2,F3 |
| SUB.D | 一个双精度浮点数减去一个单精度浮点数,结果为双精度浮点数 | SUB.D F1,F2,F3 |
| SUB.PS | 两个单精度浮点数相减 | SUB.SP F1,F2,F3 |
| DDIV | 两个定点寄存器的内容相除,也就是定点除 | DDIV R1,R2,R3 |
| DDIVU | 不带符号的除法运算 | DDIVU R1,R2,R3 |
| DIV.S | 一个双精度浮点数除以一个单精度浮点数,结果为单精度浮点数 | DIV.S F1,F2,F3 |
| DIV.D | 一个双精度浮点数除以一个单精度浮点数,结果为双精度浮点数 | DIV.D F1,F2,F3 |
| DIV.PS | 两个单精度浮点数相除,结果为单精度 | DIV.PS F1,F2,F3 |
| DMUL | 两个定点寄存器的内容相乘,也就是定点乘 | DMUL R1,R2,R3 |
| DMULU | 不带符号的乘法运算 | DMULU R1,R2,R3 |
| MUL.S | 一个双精度浮点数乘以一个单精度浮点数,结果为单精度浮点数 | DMUL.S F1,F2,F3 |
| MUL.D | 一个双精度浮点数乘以一个单精度浮点数,结果为双精度浮点数 | DMUL.D F1,F2,F3 |
| MUL.PS | 两个单精度浮点数相乘,结果为单精度浮点数 | DMUL.PS F1,F2,F3 |
| AND | 与运算,两个寄存器中的内容相与 | ANDR1,R2,R3 |
| ANDI | 一个寄存器中的内容与一个立即数相与 | ANDIR1,R2,#3 |
| OR | 或运算,两个寄存器中的内容相或 | ORR1,R2,R3 |
| ORI | 一个寄存器中的内容与一个立即数相或 | ORIR1,R2,#3 |
| XOR | 异或运算,两个寄存器中的内容相异或 | XORR1,R2,R3 |
| XORI | 一个寄存器中的内容与一个立即数异或 | XORIR1,R2,#3 |
| BEQZ | 条件转移指令,当寄存器中内容为0时转移发生 | BEQZ R1,0 |
| BENZ | 条件转移指令,当寄存器中内容不为0时转移发生 | BNEZ R1,0 |
| BEQ | 条件转移指令,当两个寄存器内容相等时转移发生 | BEQ R1,R2 |
| BNE | 条件转移指令,当两个寄存器中内容不等时转移发生 | BNE R1,R2 |
| J | 直接跳转指令,跳转的地址在指令中 | J name |
| JR | 使用寄存器的跳转指令,跳转地址在寄存器中 | JR R1 |
| JAL | 直接跳转指令,并带有链接功能,指令的跳转地址在指令中,跳转发生时要把返回地址存放到R31这个寄存器中 | JAL R1 name |
| JALR | 使用寄存器的跳转指令,并且带有链接功能,指令的跳转地址在寄存器中,跳转发生时指令的放回地址放在R31这个寄存器中 | JALR R1 |
| MOV.S | 把一个单精度浮点数从一个浮点寄存器复制到另一个浮点寄存器 | MOV.S F0,F1 |
| MOV.D | 把一个双精度浮点数从一个浮点寄存器复制到另一个浮点寄存器 | MOV.D F0,F1 |
| MFC0 | 把一个数据从通用寄存器复制到特殊寄存器 | MFC0 R1,R2 |
| MTC0 | 把一个数据从特殊寄存器复制到通用寄存器 | MTC0 R1,R2 |
| MFC1 | 把一个数据从定点寄存器复制到浮点寄存器 | MFC1 R1,F1 |
| MTC1 | 把一个数据从浮点寄存器复制到定点寄存器 | MTC1 R1,F1 |
| LUI | 把一个16位的立即数填入到寄存器的高16位,低16位补零 | LUI R1,#42 |
| DSLL | 双字逻辑左移 | DSLL R1,R2,#2 |
| DSRL | 双字逻辑右移 | DSRL R1,R2,#2 |
| DSRA | 双字算术右移 | DSRA R1,R2,#2 |
| DSLLV | 可变的双字逻辑左移 | DSLLV R1,R2,#2 |
| DSRLV | 可变的双字罗伊右移 | DSRLV R1,R2,#2 |
| DSRAV | 可变的双字算术右移 | DSRAV R1,R2,#2 |
| SLT | 如果R2的值小于R3,那么设置R1的值为1,否则设置R1的值为0 | SLT R1,R2,R3 |
| SLTI | 如果寄存器R2的值小于立即数,那么设置R1的值为1,否则设置寄存器R1的值为0 | SLTI R1,R2,#23 |
| SLTU | 功能与SLT一致,但是带符号的 | SLTU R1,R2,R3 |
| SLTUI | 功能与SLT一致,但不带符号 | SLTUI R1,R2,R3 |
| MOVN | 如果第三个寄存器的内容为负,那么复制一个寄存器的内容到另外一个寄存器 | MOVN R1,R2,R3 |
| MOVZ | 如果第三个寄存器的内容为0,那么复制一个寄存器的内容到另外一个寄存器 | MOVZ R1,R2,R3 |
| TRAP | 根据地址向量转入管态 | |
| ERET | 从异常中返回到用户态 | |
| MADD.S | 一个双精度浮点数与单精度浮点数相乘加,结果为单精度 | |
| MADD.D | 一个双精度浮点数与单精度浮点数相乘加,结果为双精度 | |
| MADD.PS | 两个单精度浮点数相乘加,结果为单精度 |
0x05 浅解MIPS程序逆向分析
工欲善其事必先利其器|ghidra下载
在x86等常见架构下IDA的反编译非常的给力,但是在mips下,IDA即使有Retdec插件的帮助,反编译的局限性也比较大(mips64此插件就反编译不了),不过没有关系,MIPS架构逆向分析有他的专门工具ghidra
github下载链接
https://github.com/NationalSecurityAgency/ghidra
ghidra是一款由美国国安局开发,用于对彪IDA的逆向分析工具,如果想更深入的了解ghidra工具,可以看下面这个链接。
https://zhuanlan.zhihu.com/p/59637690
当然,如果你对ida拥有深沉的爱,IDA 对于分析mips程序的专属插件 Retdec必不可少
https://github.com/avast-tl/retdec/releases
或许你也可以使用ida7.5+版本,内置mips分析插件
工欲善其事必先利其器|MIPS运行环境配置
安装qemu和所需要的库
apt install qemu-user-static
sudo apt install libc6-mips64-cross
根据不同的misp架构版本,需要下载不同的运行库。要查找这些命令库,需要我们在命令行输入
qemu[tab][tab]
qemu常见的安装报错处理,下面这篇文章写的很清楚了
https://blog.csdn.net/yalecaltech/article/details/104297419
磨刀不误砍柴工|MIPS简单ctf题目尝试
[UTCTF2020]babymips
ida7.5+可以部分反编译mips架构程序,虽然效果一般但是在这道题还是够用的,我们反编译关键函数,发现加密逻辑很简单,为a1[]进行一个简单的异或。
int __fastcall sub_401164(int a1, int a2)
{
int v2; // $v0
int result; // $v0
int v4; // $v0
unsigned int i; // [sp+1Ch] [+1Ch]
if ( std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::size(a2) != 0x4E )
{
LABEL_2:
v2 = std::operator<<<std::char_traits<char>>(&std::cout, "incorrect");
result = std::ostream::operator<<(v2, &std::endl<char,std::char_traits<char>>);
}
else
{
for ( i = 0; i < std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::size(a2); ++i )
{
if ( (*(char *)std::__cxx11::basic_string<char,std::char_traits<char>,std::allocator<char>>::operator[](a2, i) ^ (i + 23)) != *(char *)(a1 + i) )
goto LABEL_2;
}
v4 = std::operator<<<std::char_traits<char>>(&std::cout, "correct!");
result = std::ostream::operator<<(v4, &std::endl<char,std::char_traits<char>>);
}
return result;
}
接着我们尝试读汇编寻找a1数据
有一些命令我们需要熟练掌握:
1. lw (load word)加载指令,存储器和寄存器沟通的两个桥梁之一,同理还有 la(load address) li (load immediate data) ld(dword) lh(半字) lb(字节)lwc1(加载浮点数)......在ida里看到此类的姑且就当成x86里的mov就好
2.sw(store word)储存指令,存储器和寄存器沟通的另一个桥梁,通常是存到栈里。
3.add 相加 当然还有 mul(乘) sub(减) div(除) ,拿add说明:在ida里很多长daddiu,addiu这个样子,需要注意的是加减乘除是分整数(add),单精度浮点数(add.s),双精度浮点数的(add.d),需注意!
4.beq bne 两数相等,两数不相等,通常结合slt(set less then)来当c语言里的“if”,还要注意的就是分支延时(下文会说)
5. jar 把它当作x86下的call
6. c.eq.s 或者 c.eq.d 分别是单精度浮点数,与双精度浮点数的比较
找到a[1]的原始数据在
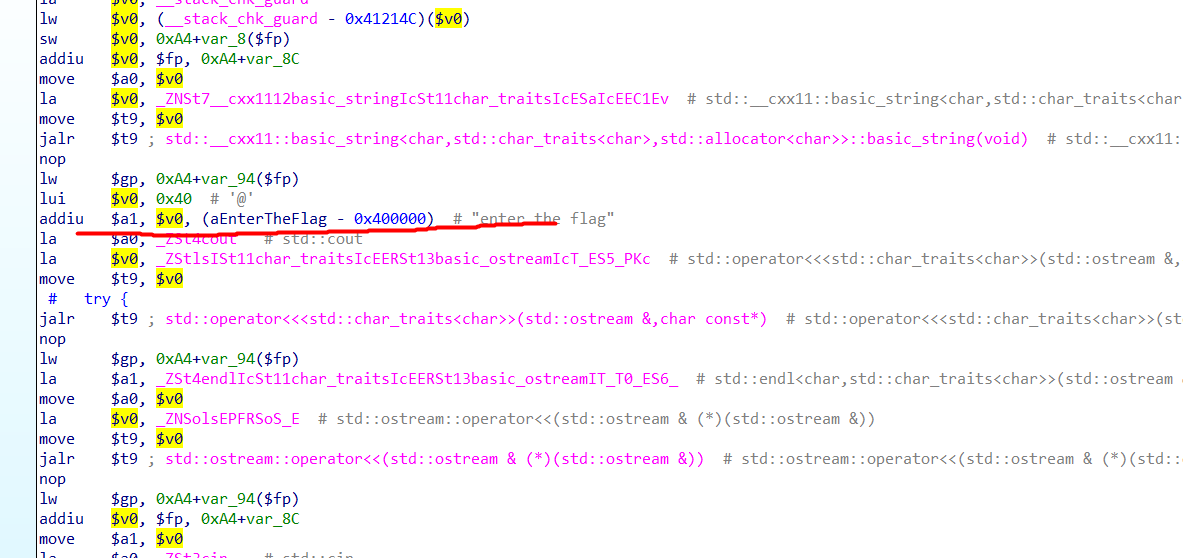
写脚本解密即可:
a="62 6C 7F 76 7A 7B 66 73 76 50 52 7D 40 54 55 79 40 49 47 4D 74 19 7B 6A 42 0A 4F 52 7D 69 4F 53 0C 64 10 0F 1E 4A 67 03 7C 67 02 6A 31 67 61 37 7A 62 2C 2C 0F 6E 17 00 16 0F 16 0A 6D 62 73 25 39 76 2E 1C 63 78 2B 74 32 16 20 22 44 19"
a=a.split()
for i in range(len(a)):
print(chr(eval("0x"+a[i])^(i+23)),end="")
[QCTF2018]Xman-babymips
不得不感叹ida的强大,本题的反汇编代码比较成功
反编译加密函数,发现是一个简单移位运算。
int __fastcall sub_4007F0(const char *a1)
{
char v1; // $v1
int result; // $v0
size_t i; // [sp+18h] [+18h]
for ( i = 5; i < strlen(a1); ++i )
{
if ( (i & 1) != 0 )
v1 = (a1[i] >> 2) | (a1[i] << 6);
else
v1 = (4 * a1[i]) | (a1[i] >> 6);
a1[i] = v1;
}
if ( !strncmp(a1 + 5, (const char *)off_410D04, 0x1Bu) )
result = puts("Right!");
else
result = puts("Wrong!");
return result;
}
可以直接逆向反写加密得到flag
a=[0x52,0xfd,0x16,0xa4,0x89,0xbd,0x92,0x80,0x13,0x41,0x54,0xa0,0x8d,0x45,0x18,0x81,0xde,0xfc,0x95,0xf0,0x16,0x79,0x1a,0x15,0x5b,0x75,0x1f]
flag=''
for i in range(0,len(a)):
if i%2==0:
a[i]= (a[i]&0x3f) << 2 | (a[i]&0xc0) >> 6 #相当于循环左移2位(里面的与操作是为了防止溢出)
flag+=chr(a[i]^0x20 - i-5)
else:
a[i]=(a[i]&0xfc) >> 2 | (a[i]&0x3 ) << 6 #相当于循环右移2位(里面的与操作是为了防止溢出)
flag+=chr(a[i]^0x20 - i-5)
print('flag{'+flag)
也可以采用爆破的方式
flag = "qctf{"
keys = [0x52, 0xFD, 0x16, 0xA4, 0x89, 0xBD, 0x92, 0x80,
0x13, 0x41, 0x54, 0xA0, 0x8D, 0x45, 0x18, 0x81, 0xDE, 0xFC, 0x95, 0xF0, 0x16, 0x79, 0x1A, 0x15,
0x5B, 0x75, 0x1F]
print (len(keys))
for i in xrange(5,0x20):
for c in xrange(0,0x100):
fst = (c ^ ((0x20-i)))
if (i % 2) == 0:
res = ((fst << 2) % 0x100) | (fst >> 6)
else:
res = (fst >> 2) | ((fst << 6) % 0x100)
if (res == keys[i-5]):
flag += chr(c)
print (flag)
由于IDA对于本题程序的反汇编比较成功,分析程序的过程比较顺利。mips的题目是这样的,三分天注定,七分靠打拼,只能说这道题目中我们的运气比较好。
[ciscn2018]2ex
静态分析,前面讲过 mips架构中的la指令,类似于x86中的mov指令。
发现程序存储了了可疑字符串
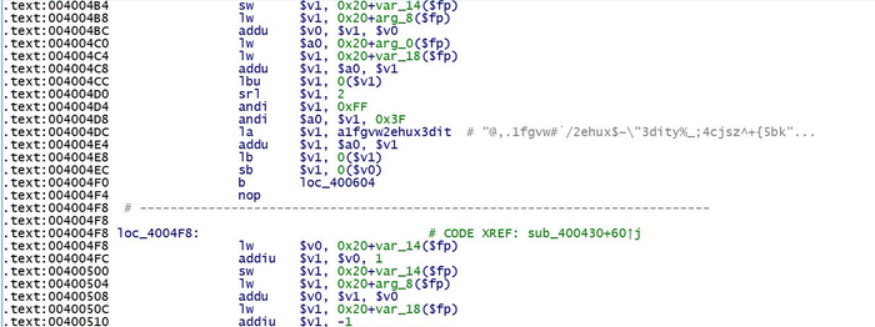
反编译比较成功,从关键函数看出为base64换表加密,可疑字符串为变态base表
int __fastcall sub_400430(int a1, unsigned int a2, int a3)
{
unsigned int v3; // $v0
int v4; // $v0
int v5; // $v0
int v6; // $v0
unsigned int i; // [sp+8h] [+8h]
unsigned int v9; // [sp+8h] [+8h]
int v10; // [sp+Ch] [+Ch]
v10 = 0;
for ( i = 0; i < a2; ++i )
{
v3 = i % 3;
if ( i % 3 == 1 )
{
v5 = v10++;
*(a3 + v5) = byte_410200[16 * (*(a1 + i - 1) & 3) + ((*(a1 + i) >> 4) & 0xF)];
}
else if ( v3 == 2 )
{
*(a3 + v10) = byte_410200[4 * (*(a1 + i - 1) & 0xF) + ((*(a1 + i) >> 6) & 3)];
v6 = v10 + 1;
v10 += 2;
*(a3 + v6) = byte_410200[*(a1 + i) & 0x3F];
}
else if ( !v3 )
{
v4 = v10++;
*(a3 + v4) = byte_410200[(*(a1 + i) >> 2) & 0x3F];
}
}
金麟岂是池中物|MIPS复杂题目探究
[DDCTF2018]baby_mips
先使用readelf 读取一下文件
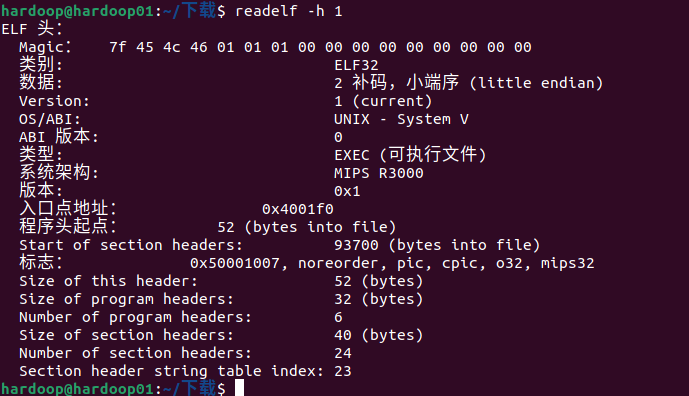
小端序程序,能够直接运行
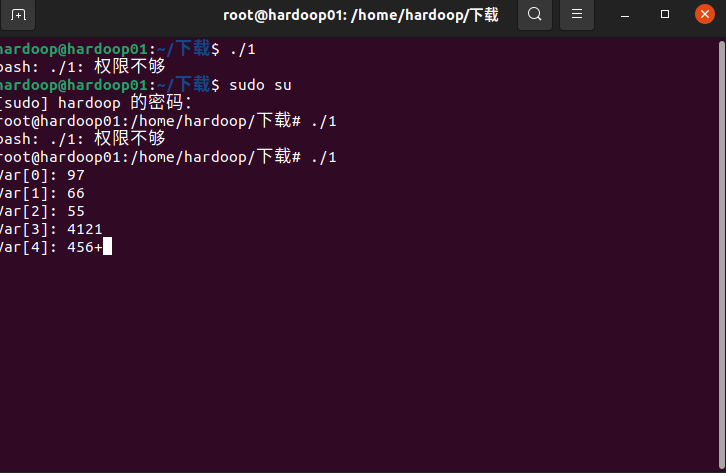
动调准备
选择debugger setup,勾选下图标注的两个选项。
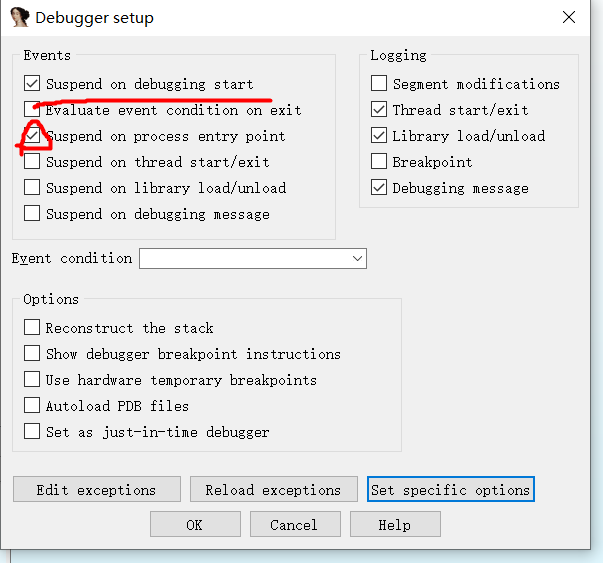
这样我们就成功进入了动态调试
连上之后我们一路单步,来到运行时报错的位置。
ida报错
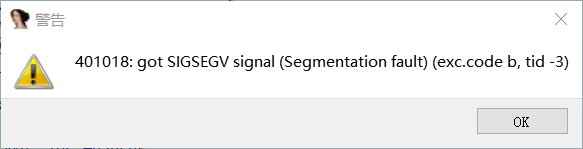
查看此时的机器码

问题出在EB,因为我们是在x86下模拟的mips,XEB在x86指令集下是jmp指令,这导致程序让我们遇到这个指令就跳转四字节。又因为一条mips指令为4字节 EB 02 0A E7 相当于跳到下一条指令(mips下一条指令固定是4字节),所以造成了段错误(简而言之就是访问了不该访问的地址),这个东西不止导致动调失败,也会导致静态反编译失败。
编写idapython脚本去花,把所有的eb02都nop掉
from idc_bc695 import *
addr1 = 0x004001F0
addr2 = 0X00403234
while addr1<=addr2:
if Byte(addr1)==0xeb and Byte(addr1+1)==0x02:
PatchByte(addr1,0x00)
PatchByte(addr1+1,0x00)
PatchByte(addr1+2,0x00)
PatchByte(addr1+3,0x00)
addr1=addr1+4
使用ghidra反编译,这次可以看到加密函数逻辑了。一个十三元一次函数求解,果断上我们的z3约束求解神器
from z3 import *
a = [BitVec("a%d"%i, 32) for i in range(16)]
s = Solver()
s.add(0xca6a*a[0] -0xd9ee*a[1] +0xc5a7*a[2] +0x19ee*a[3] +0xb223*a[4] +0x42e4*a[5] +0xc112*a[6] -0xcf45*a[7] +0x260d*a[8] +0xd78d*a[9] +0x99cb*a[10] -0x3e58*a[11] -0x97cb*a[12] +0xfba9*a[13] -0xdc28*a[14] +0x859b*a[15] == 0xaa2ed7)
s.add(0xf47d*a[0] +0x12d3*a[1] -0x4102*a[2] +0xcedf*a[3] -0xafcf*a[4] -0xeb20*a[5] -0x2065*a[6] +0x36d2*a[7] -0x30fc*a[8] -0x7e5c*a[9] +0xeea8*a[10] +0xd8dd*a[11] -0xae2*a[12] +0xc053*a[13] +0x5158*a[14] -0x8d42*a[15] == 0x69d32e)
s.add(0xffff52cf*a[0] -0x4fea*a[1] +0x2075*a[2] +0x9941*a[3] -0xbd78*a[4] +0x9e58*a[5] +0x40ad*a[6] -0x8637*a[7] -0x2e08*a[8] +0x4414*a[9] +0x2748*a[10] +0x1773*a[11] +0xe414*a[12] -0x7b19*a[13] +0x6b71*a[14] -0x3dcf*a[15] == 0x3b89d9)
s.add(0xffffedd7*a[0] -0x1df0*a[1] +0x8115*a[2] +0x54bd*a[3] -0xf2ba*a[4] +0xdbd*a[5] +0x1dcf*a[6] +0x272*a[7] -0x2fcc*a[8] -0x93d8*a[9] -0x6f6c*a[10] -0x98ff*a[11] +0x2148*a[12] -0x6be2*a[13] +0x2e56*a[14] -0x7bdf*a[15] == 0xff6a5aea)
s.add(0xffffa8c1*a[0] +0xdc78*a[1] -0x380f*a[2] +0x33c0*a[3] -0x7252*a[4] -0xe5a9*a[5] +0x7a53*a[6] -0x4082*a[7] -0x584a*a[8] +0xc8db*a[9] +0xd941*a[10] +0x6806*a[11] -0x8b97*a[12] +0x23d4*a[13] +0xac2a*a[14] +0x20ad*a[15] == 0x953584)
s.add(0x5bb7*a[0] -0xfdb2*a[1] +0xaaa5*a[2] -0x50a2*a[3] -0xa318*a[4] +0xbcba*a[5] -0x5e5a*a[6] +0xf650*a[7] +0x4ab6*a[8] -0x7e3a*a[9] -0x660c*a[10] +0xaed9*a[11] -0xa60f*a[12] +0xf924*a[13] -0xff1d*a[14] +0xc888*a[15] == 0xffd31341)
s.add(0x812d*a[0] -0x402c*a[1] +0xaa99*a[2] -0x33b*a[3] +0x311b*a[4] -0xc0d1*a[5] -0xfad*a[6] -0xc1bf*a[7] -0x1560*a[8] -0x445b*a[9] -0x9b78*a[10] +0x3b94*a[11] +0x2531*a[12] -0xfb03*a[13] +0x8*a[14] +0x8721*a[15] == 0xff9a6b57)
s.add(0x15c5*a[0] +0xb128*a[1] -0x957d*a[2] +0xdf80*a[3] +0xee68*a[4] -0x3483*a[5] -0x4b39*a[6] -0x3807*a[7] -0x4f77*a[8] +0x652f*a[9] -0x686f*a[10] -0x7fc1*a[11] -0x5d2b*a[12] -0xb326*a[13] -0xacde*a[14] +0x1f11*a[15] == 0xffd6b3d3)
s.add(0xaf37*a[0] +0x709*a[1] +0x4a95*a[2] -0xa445*a[3] -0x4c32*a[4] -0x6e5c*a[5] -0x45a6*a[6] +0xb989*a[7] +0xf5b7*a[8] +0x3980*a[9] -0x151d*a[10] +0xaf13*a[11] +0xa134*a[12] +0x67ff*a[13] +0xce*a[14] +0x79cf*a[15] == 0xc6ea77)
s.add(0xffff262a*a[0] +0xdf05*a[1] -0x148e*a[2] -0x4758*a[3] -0xc6b2*a[4] -0x4f94*a[5] -0xf1f4*a[6] +0xcf8*a[7] +0xf5f1*a[8] -0x7883*a[9] -0xe2c6*a[10] -0x67*a[11] +0xeccc*a[12] -0xc630*a[13] -0xba2e*a[14] -0x6e41*a[15] == 0xff1daae5)
s.add(0xffff9be3*a[0] -0x716d*a[1] +0x4505*a[2] -0xb99d*a[3] +0x1f00*a[4] +0x72bc*a[5] -0x7ff*a[6] +0x8945*a[7] -0xcc33*a[8] -0xab8f*a[9] +0xde9e*a[10] -0x6b69*a[11] -0x6380*a[12] +0x8cee*a[13] -0x7a60*a[14] +0xbd39*a[15] == 0xff5be0b4)
s.add(0x245e*a[0] +0xf2c4*a[1] -0xeb20*a[2] -0x31d8*a[3] -0xe329*a[4] +0xa35a*a[5] +0xaacb*a[6] +0xe24d*a[7] +0xeb33*a[8] +0xcb45*a[9] -0xdf3a*a[10] +0x27a1*a[11] +0xb775*a[12] +0x713e*a[13] +0x5946*a[14] +0xac8e*a[15] == 0x144313b)
s.add(0x157*a[0] -0x5f9c*a[1] -0xf1e6*a[2] +0x550*a[3] -0x441b*a[4] +0x9648*a[5] +0x8a8f*a[6] +0x7d23*a[7] -0xe1b2*a[8] -0x5a46*a[9] -0x5461*a[10] +0xee5f*a[11] -0x47e6*a[12] +0xa1bf*a[13] +0x6cf0*a[14] -0x746b*a[15] == 0xffd18bd2)
s.add(0xf81b*a[0] -0x76cb*a[1] +0x543d*a[2] -0x4a85*a[3] +0x1468*a[4] +0xd95a*a[5] +0xfbb1*a[6] +0x6275*a[7] +0x30c4*a[8] -0x9595*a[9] -0xdbff*a[10] +0x1d1d*a[11] +0xb1cf*a[12] -0xa261*a[13] +0xf38e*a[14] +0x895c*a[15] == 0xb5cb52)
s.add(0xffff6b97*a[0] +0xd61d*a[1] +0xe843*a[2] -0x8c64*a[3] +0xda06*a[4] +0xc5ad*a[5] +0xd02a*a[6] -0x2168*a[7] +0xa89*a[8] +0x2dd*a[9] -0x80cc*a[10] -0x9340*a[11] -0x3f07*a[12] +0x4f74*a[13] +0xb834*a[14] +0x1819*a[15] == 0xa6014d)
s.add(0x48ed*a[0] +0x2141*a[1] +0x33ff*a[2] +0x85a9*a[3] -0x1c88*a[4] +0xa7e6*a[5] -0xde06*a[6] +0xbaf6*a[7] +0xc30f*a[8] -0xada6*a[9] -0xa114*a[10] -0x86e9*a[11] +0x70f9*a[12] +0x7580*a[13] -0x51f8*a[14] -0x492f*a[15] == 0x2fde7c)
if(s.check()==sat):
c = b''
m = s.model()
for i in range(16):
print("a[%d]=%d"%(i, m[a[i]].as_long()))
for i in range(16):
print(chr(m[a[i]].as_long()&0xff), end='')
[RCTF2020]cipher
静态分析
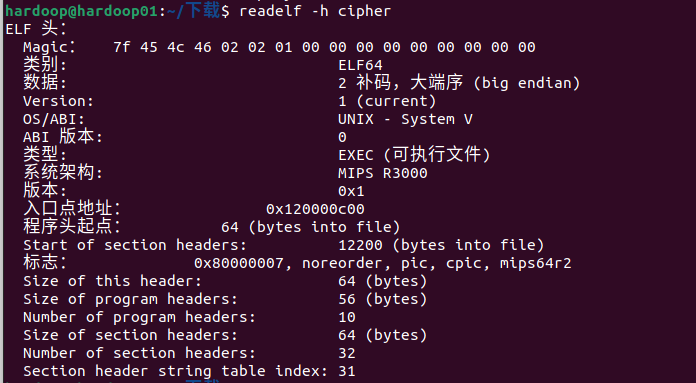
程序为 mips64 大端,起始位置为0x120000c00
将程序放入ghidra分析,找到main函数
undefined8 main(void)
{
uint __seed;
undefined auStack120 [16];
char acStack104 [64];
longlong local_28;
undefined *local_18;
local_18 = &_gp;
local_28 = __stack_chk_guard;
__seed = time((time_t *)0x0);
srand(__seed);
memset(auStack120,0,0x10);
memset(acStack104,0,0x40);
setvbuf(stdin,(char *)0x0,2,0);
setvbuf(stdout,(char *)0x0,2,0);
fp = fopen("flag","r");
fread(acStack104,1,0x40,fp);
cipher(acStack104,auStack120);
fclose(fp);
if (local_28 != __stack_chk_guard) {
/* WARNING: Subroutine does not return */
__stack_chk_fail();
}
return 0;
}
重点关注一下 main函数开头的赋值语句,涉及到一个新知识点&_gp”gp寄存器的重定位
利用gp寄存器相对寻址
前置知识:PLT&GOT 表
linux 下的动态链接是通过 PLT&GOT 来实现的,当我们通过重定位调用glibc中的函数时,链接器会额外生成一小段代码,通过这段代码来获取函数的地址。
总体来说,动态链接每个函数需要两个东西:
1、用来存放外部函数地址的数据段
2、用来获取数据段记录的外部函数地址的代码
对应有两个表,一个用来存放外部的函数地址的数据表称为全局偏移表(GOT, Global Offset Table),那个存放额外代码的表称为程序链接表(PLT,Procedure Link Table)
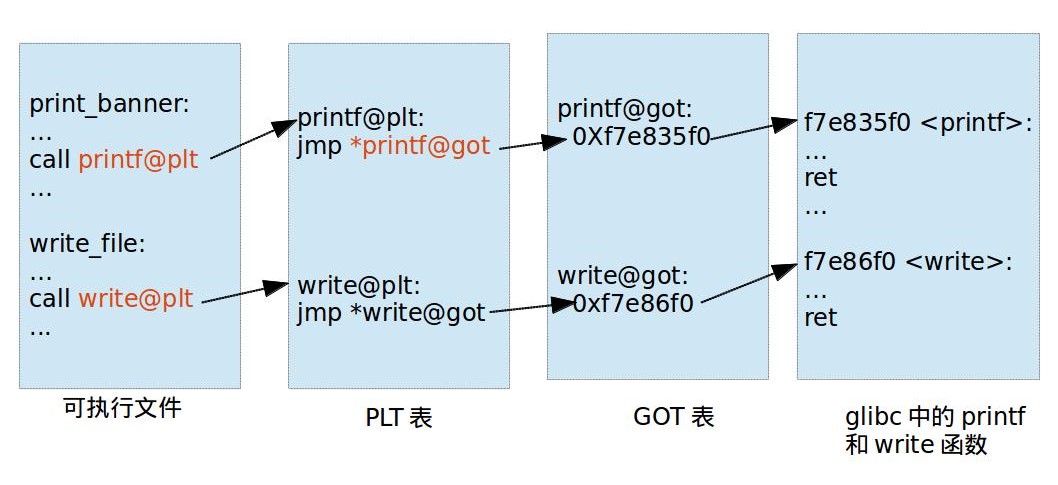
可执行文件里面保存的是 PLT 表的地址,对应 PLT 地址指向的是 GOT 的地址,GOT 表指向的就是 glibc 中的地址
前置知识:延迟绑定机制
在这里面想要通过 plt 表获取函数的地址,首先要保证 got 表已经获取了正确的地址,但是在一开始就进行所有函数的重定位是比较麻烦的,为此,linux 引入了延迟绑定机制。
延迟绑定机制:
源程序在第一次调用一个函数的时候,首先去该函数的plt[0]表项,然后到该函数got表里,然后跳转到该函数plt[1]表项里,进行压栈操作,这里压的是第一个参数rel_offest是函数符号在重定位表中的偏移。然后跳转至公共plt[0],压栈dynamic段中rel_plt节的基地址,此时 dl_runtime_reslove 函数的两个参数压栈完成,随后进入该函数在rel.plt节的表项,rel.plt这里存储了每个函数的结构体:r_offest 这里记录了相应got.plt的地址,r_info右移8位得到该函数在dynsym节区符号下表,dynsym的基地址+下标 = 该函数在dynstr表中的偏移-->函数在dynstr表中的偏移+dynstr表的基地址 = 函数名。找到之后,通过调用_dl_fixup等函数,将函数入口点解析,并写入got_plt,在跳转到函数入口点。
也就是说在想要调用的函数被初次调用时是按照这个过程来调用
xxx@plt -> xxx@got -> xxx@plt -> 公共 @plt -> _dl_runtime_resolve
借用大佬的一张图片来解释该机制:
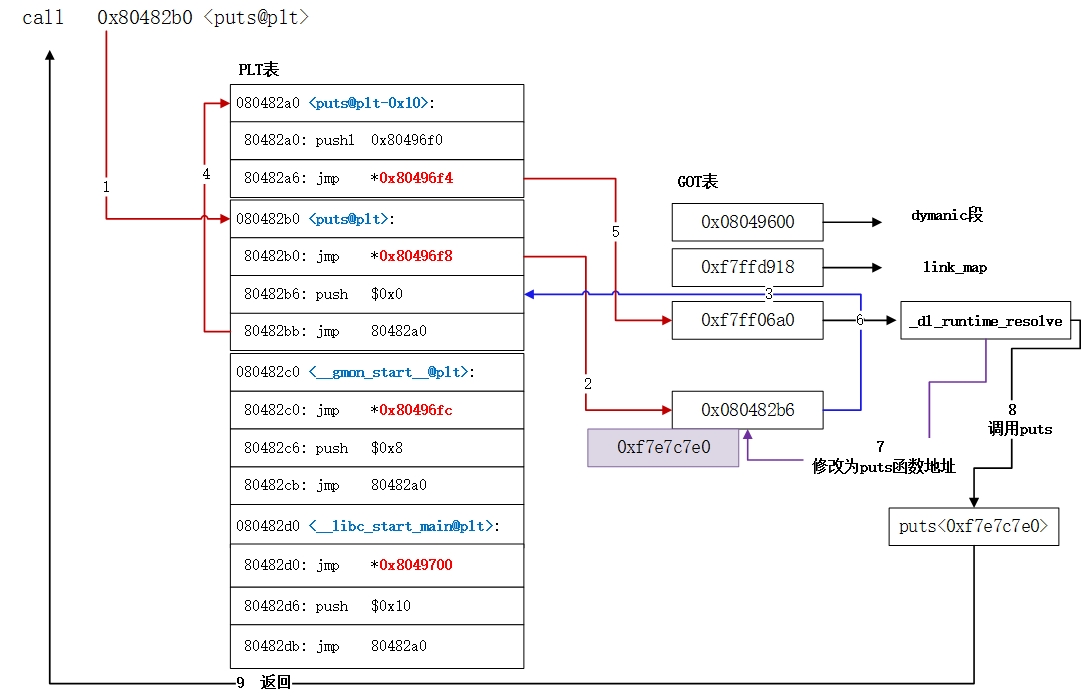
原文链接:https://bbs.pediy.com/thread-257545.htm
作者:yichen115
继续做题
main函数读入flag文件,然后进入cipher函数,我们继续跟进cipher函数。
void cipher(char *param_1,undefined *param_2)
{
undefined4 extraout_v0_hi;
size_t sVar1;
int iVar2;
int iVar3;
int local_70;
char acStack104 [64];
longlong local_28;
undefined *local_18;
local_18 = &_gp;
local_28 = __stack_chk_guard;
sVar1 = strlen(param_1);
iVar2 = (int)(CONCAT44(extraout_v0_hi,sVar1) - 1U >> 4) + 1;
iVar3 = rand();
*param_2 = (char)iVar3;
iVar3 = rand();
param_2[1] = (char)iVar3;
for (local_70 = 0; local_70 < iVar2; local_70 = local_70 + 1) {
encrypt(acStack104 + (local_70 << 4),(int)param_1 + local_70 * 0x10);
}
for (local_70 = 0; local_70 < iVar2 * 0x10; local_70 = local_70 + 1) {
putchar((int)acStack104[local_70]);
}
putchar(10);
if (local_28 != __stack_chk_guard) {
/* WARNING: Subroutine does not return */
__stack_chk_fail();
}
return;
}
第18到20行得到了两个随机数,并分别取char,并保存至param_2[0]和param_2[1]。然后进入循环,调用encrypt函数。看起来是一些简单的异或和位运算,好像不是很难

但是仔细读程序我们会发现,代码中没有任何对第8行声明的in_a2这个指针的赋值地址的行为,我们(和程序)根本不知道这个指针指向何处(如果按照伪代码的逻辑来的话)。参考看雪大佬的博客,了解到是反编译出了问题。在大佬的指导下,我们修改了函数的变量,增加了一个指针变量。
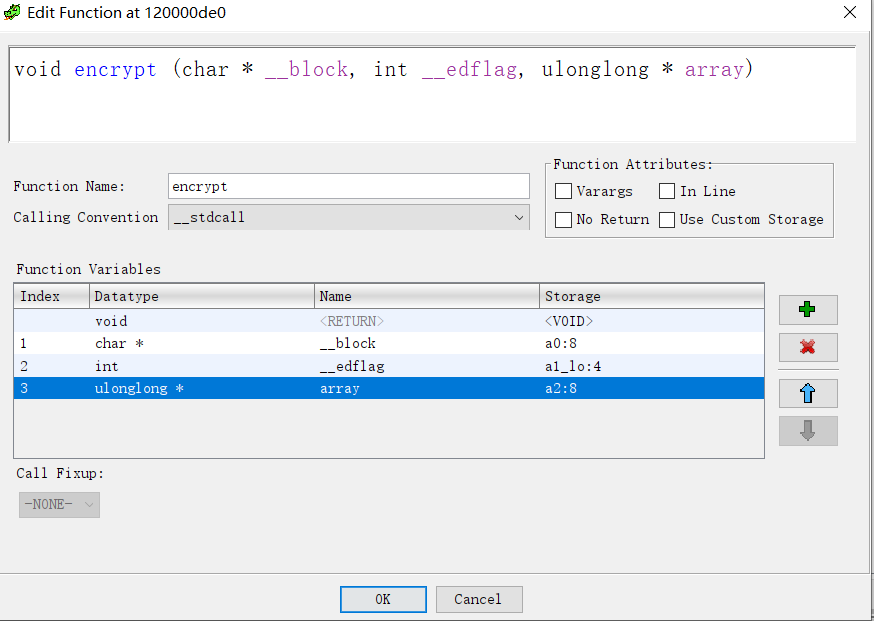
根据修改后的程序整理出加密逻辑
def decrypt(byte16, fc, fd):
v48 = struct.unpack('>Q', byte16[:8])[0]
v40 = struct.unpack('>Q', byte16[8:])[0]
v32, v24 = fc, fd
for i in range(0x1e, -1, -1):
v48 = rol64(v48 ^ v40, 0x3d)
v40 = rol64(ull((v40 ^ v32) - v48), 8)
v32 = rol64(v32 ^ v24, 0x3d)
v24 = rol64(ull((v24 ^ i) - v32), 8)
v48 = rol64(v48 ^ v40, 0x3d)
v40 = rol64(ull((v40 ^ v32) - v48), 8)
return v48, v40
动态调试
由于我们通常的操作系统指令集都是x86的,所以无法跑MIPS程序。这时候就需要装QEMU来模拟,QEMU通过源码编译较为复杂,我们又没有特殊的需求,所以直接使用ubuntu的APT进行安装即可。
首先我们先装好qemu和qemu里对应的mips64的库
apt install qemu-user-static
sudo apt install libc6-mips64-cross
之后可以尝试运行:
qemu-mips64-static -L /usr/mips64-linux-gnuabi64/ cipher
-static参数,显示更多的调试信息
-L 因为是动态链接所以要指定libc库的路径
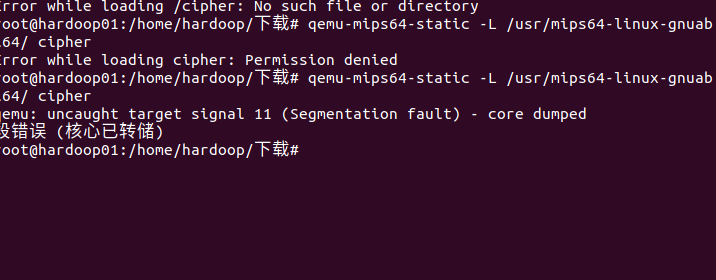
这里出现了两个报错,
permission denied 错误是由于权限不够,我们开启允许执行程序权限
段错误的出现。和上题中的段错误出现原因一致,由于x86架构下EB机器码与jmp命令的混淆问题 nop掉即可。
通过动调得到了 cipher中cd的值与随机数的数量关系
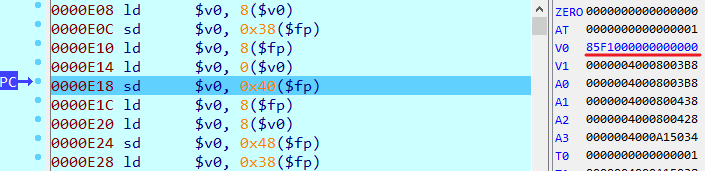
c = char(rand1)<<56 + char(rand2)<<48`,`d = 0
c和d每次运行程序都不一样,但是好在有效取值在两个字节的范围内,可以爆破。
加密逻辑上文通过静态调试获得,解密脚本,笔者暂时能力有限,参考看雪大佬的脚本。
import struct
def solve():
#with open('ciphertext', 'rb')as f:
#enc = f.read()
enc = b'*\x00\xf8+\xe1\x1dw\xc1\xc3\xb1q\xfc#\xd5\x91\xf40\xf1\x1e\x8b\xc2\x88YW\xd5\x94\xabwB/\xebu\xe1]v\xf0Fn\x98\xb9\xb6Q\xfd\xb5]w6\xf2\n'
for i in range(0x10000):
v32, v24 = get_final_r1_r2(i*0x1000000000000, 0)
flag = b''
for k in range(len(enc)//16):
f1, f2 = decrypt(enc[k*16:k*16+16], v32, v24)
flag += struct.pack('>Q', f1) + struct.pack('>Q', f2)
if b'RCTF' in flag:
print(hex(i), flag)
def decrypt(byte16, fc, fd):
v48 = struct.unpack('>Q', byte16[:8])[0]
v40 = struct.unpack('>Q', byte16[8:])[0]
v32, v24 = fc, fd
for i in range(0x1e, -1, -1):
v48 = rol64(v48 ^ v40, 0x3d)
v40 = rol64(ull((v40 ^ v32) - v48), 8)
v32 = rol64(v32 ^ v24, 0x3d)
v24 = rol64(ull((v24 ^ i) - v32), 8)
v48 = rol64(v48 ^ v40, 0x3d)
v40 = rol64(ull((v40 ^ v32) - v48), 8)
return v48, v40
def get_final_r1_r2(c, d):
v32, v24 = c, d
for i in range(0x1f):
v24 = ull(ror64(v24, 8) + v32) ^ i
v32 = ror64(v32, 0x3d) ^ v24
return v32, v24
def rol64(value, k):
return ull(value << k) | ull(value >> (64-k))
def ror64(value, k):
return ull(value << (64-k)) | ull(value >> k)
def ull(n):
return n & 0xffffffffffffffff
solve()
再次对大佬报以我最崇高的膜拜
https://bbs.pediy.com/thread-259892.htm#msg_header_h2_6
把这道题 讲的非常透彻了
0x06 mips架构逆向分析小总结
为了便于使用将上文提到的知识点做一个小总结。
mips的基本数据类型
基本数据类型的不同可能导致函数反编译结果的错误
上官方文档。
指令的主要任务就是对操作数进行运算,操作数有不同的类型和长度,MIPS32 提供的基本数据类型如下:
(1)位(b):长度是 1bit。
(2)字节(Byte):长度是 8bit。
(3)半字(Half Word):长度是 16bit。
(4)字(Word):长度是 32bit。
(5)双字(Double Word):长度是 64bit。
(6)此外,还有 32 位单精度浮点数、64 位双精度浮点数等。
mips读取/存入数据命令
LD rt, offset(base)
从存储器中读取双字的数据到寄存器中。
SD rt, offset(base)
把双字的数据从寄存器存储到存储器中
其中rt是寄存器,offset是偏移量,base是基址
配置mips程序运行环境
由于我们通常的操作系统指令集都是x86的,所以无法跑MIPS程序。这时候就需要装QEMU来模拟,QEMU通过源码编译较为复杂,我们又没有特殊的需求,所以直接使用ubuntu的APT进行安装即可。
首先我们先装好qemu和qemu里对应的mips64的库
apt install qemu-user-static
sudo apt install libc6-mips64-cross
之后可以尝试运行:
qemu-mips64-static -L /usr/mips64-linux-gnuabi64/ cipher
-static参数,显示更多的调试信息
-L 因为是动态链接所以要指定libc库的路径
mips区分大端序小端序
注意mips程序是区分大端序和小端序的,特别是在动调时。对于大端序的mips使用qemu-mips。小端序的则使用qemu-mipsel。
当然,要注意大端序和小端序的mips程序读取数据顺序的问题
反汇编工具
常用的就是ida(7.5+)和ghidra。反汇编出来的伪代码,条理清晰程度随缘,ida的优势在于工具属性,变量跟进方便。ghidra的优势在于对mips的兼容性和支持性较好。
MIPS逆向分析常用汇编指令
1. lw (load word)加载指令,存储器和寄存器沟通的两个桥梁之一,同理还有 la(load address) li (load immediate data) ld(dword) lh(半字) lb(字节)lwc1(加载浮点数)......在ida里看到此类的姑且就当成x86里的mov就好
2.sw(store word)储存指令,存储器和寄存器沟通的另一个桥梁,通常是存到栈里。
3.add 相加 当然还有 mul(乘) sub(减) div(除) ,拿add说明:在ida里很多长daddiu,addiu这个样子,需要注意的是加减乘除是分整数(add),单精度浮点数(add.s),双精度浮点数的(add.d),需注意!
4.beq bne 两数相等,两数不相等,通常结合slt(set less then)来当c语言里的“if”,还要注意的就是分支延时(下文会说)
5. jar 把它当作x86下的call
6. c.eq.s 或者 c.eq.d 分别是单精度浮点数,与双精度浮点数的比较
MIPS特殊寻址方式
MIPS唯一的硬件寻址方式
MIPS32中一条32位的指令是无法直接寻址32位的内存地址,加载(lw,load word)和存储(sw,store word)的机器指令数据域offset只支持16位编码。实际上,MIPS硬件只支持一种寻址方式,那就是“基址寄存器+16位有符号偏移量”。任何加载(存储)指令都类似如下格式:“lw $1,offset($2)”。可以使用任何寄存器作为目的操作数和源操作数,偏移量offset是一个有符号的16位数(-32768~32767),以上指令的效果为$1=$2+offset。
利用gp寄存器相对寻址
前置知识:PLT&GOT 表
linux 下的动态链接是通过 PLT&GOT 来实现的,当我们通过重定位调用glibc中的函数时,链接器会额外生成一小段代码,通过这段代码来获取函数的地址。
总体来说,动态链接每个函数需要两个东西:
1、用来存放外部函数地址的数据段
2、用来获取数据段记录的外部函数地址的代码
对应有两个表,一个用来存放外部的函数地址的数据表称为全局偏移表(GOT, Global Offset Table),那个存放额外代码的表称为程序链接表(PLT,Procedure Link Table)
可执行文件里面保存的是 PLT 表的地址,对应 PLT 地址指向的是 GOT 的地址,GOT 表指向的就是 glibc 中的地址
前置知识:延迟绑定机制
在这里面想要通过 plt 表获取函数的地址,首先要保证 got 表已经获取了正确的地址,但是在一开始就进行所有函数的重定位是比较麻烦的,为此,linux 引入了延迟绑定机制。
延迟绑定机制:
源程序在第一次调用一个函数的时候,首先去该函数的plt[0]表项,然后到该函数got表里,然后跳转到该函数plt[1]表项里,进行压栈操作,这里压的是第一个参数rel_offest是函数符号在重定位表中的偏移。然后跳转至公共plt[0],压栈dynamic段中rel_plt节的基地址,此时 dl_runtime_reslove 函数的两个参数压栈完成,随后进入该函数在rel.plt节的表项,rel.plt这里存储了每个函数的结构体:r_offest 这里记录了相应got.plt的地址,r_info右移8位得到该函数在dynsym节区符号下表,dynsym的基地址+下标 = 该函数在dynstr表中的偏移-->函数在dynstr表中的偏移+dynstr表的基地址 = 函数名。找到之后,通过调用_dl_fixup等函数,将函数入口点解析,并写入got_plt,在跳转到函数入口点。
也就是说在想要调用的函数被初次调用时是按照这个过程来调用
xxx@plt -> xxx@got -> xxx@plt -> 公共 @plt -> _dl_runtime_resolve
借用大佬的一张图片来解释该机制:
原文链接:https://bbs.pediy.com/thread-257545.htm
作者:yichen115
MIPS调试普遍性段错误原因
当我们尝试在x86架构机器模拟运行mips程序时,常出现如上图一般的段错误
动态调试ida报错
查看此时的机器码
问题出在EB,因为我们是在x86下模拟的mips,XEB在x86指令集下是jmp指令,这导致程序让我们遇到这个指令就跳转四字节。又因为一条mips指令为4字节 EB 02 0A E7 相当于跳到下一条指令(mips下一条指令固定是4字节),所以造成了段错误(简而言之就是访问了不该访问的地址),这个东西不止导致动调失败,也会导致静态反编译失败。
编写idapython脚本去花,把所有的eb02都nop掉
from idc_bc695 import *
addr1 = 0x004001F0
addr2 = 0X00403234
while addr1<=addr2:
if Byte(addr1)==0xeb and Byte(addr1+1)==0x02:
PatchByte(addr1,0x00)
PatchByte(addr1+1,0x00)
PatchByte(addr1+2,0x00)
PatchByte(addr1+3,0x00)
addr1=addr1+4
0x07 后记
深夜的一点小流水账
受家乡疫情影响,这段时间被迫离开教室,机房。一定程度上打乱了我的学习计划。蜗居在宿舍里,人容易变得懒惰,迟钝。
因此我选择了研究MIPS架构,一个对我来说完全未知的领域。寄希望富有挑战性的任务来激发我的斗志。
当然,它没让我失望,历时近一周时间,我终于写完了这篇总结。我已经数不清为它我处理了多少次令我头疼的报错。阅读了多少篇大佬博客。就算这样,暂时我也没能独立复现出全部内容,不过我已经很满足了,毕竟这是我和它的初次见面,往后的比赛里,相信我们来日方长。
个人或许无法改变时代命运,唯一能做的,大概只有清醒的认知,坦然接受,然后沉下心来,改变自我,提升自我。
未来,要学习的还有很多,继续加油吧。
0x08 参考链接
https://www.cnblogs.com/CoBrAMG/p/9237609.html
http://blog.chinaunix.net/uid-10167808-id-26020.html
https://blog.csdn.net/m0_46362499/article/details/107629918
https://bbs.pediy.com/thread-257545.htm
https://blog.csdn.net/m0_46362499/article/details/107629918?spm=1001.2014.3001.5502
- 本文作者: 绿冰壶
- 本文来源: 奇安信攻防社区
- 原文链接: https://forum.butian.net/share/1502
- 版权声明: 除特别声明外,本文各项权利归原文作者和发表平台所有。转载请注明出处!

