
前段时间,在写批量化挖掘的脚本,现在已经收工了,大概也就100+shell左右,用来练手的其余sql注入,未授权都交给公益src了。
作者:echo
前段时间,在写批量化挖掘的脚本,现在已经收工了,大概也就100+shell左右,用来练手的其余sql注入,未授权都交给公益src了。
先上图,大佬勿喷,只做一个思路-实施的过程。
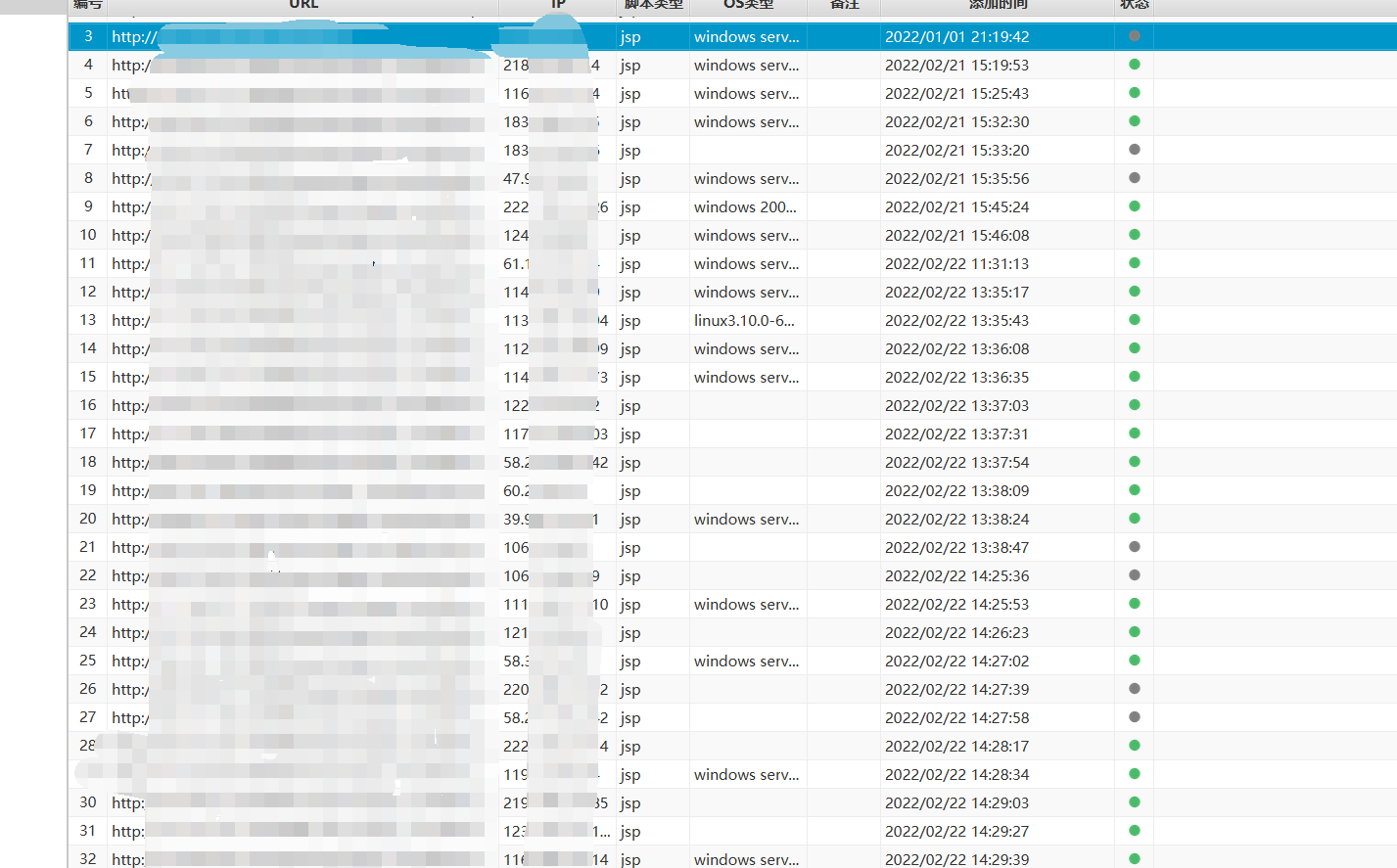
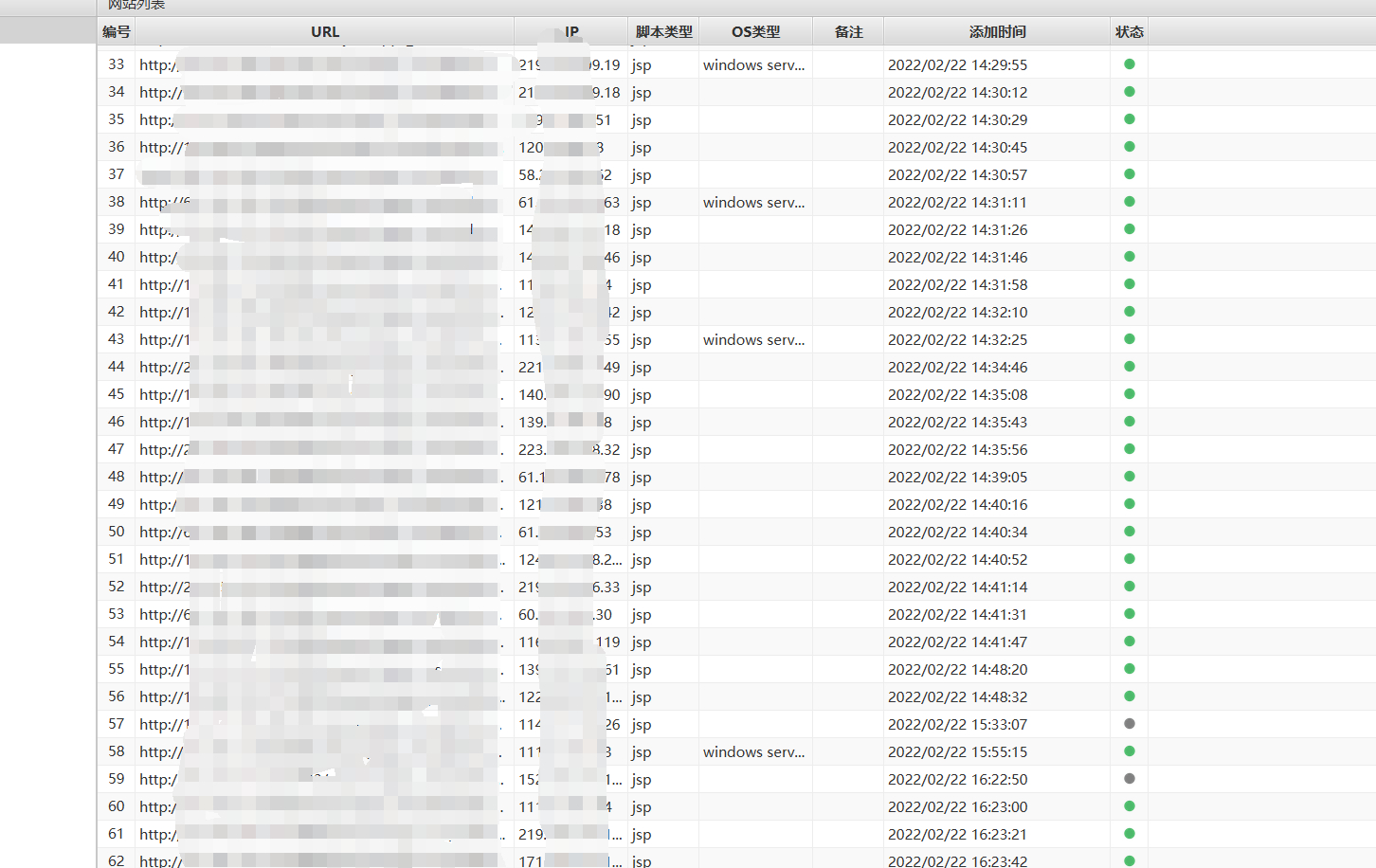
既然大家都是漏洞老千层了,直接上思路图和脚本吧,
这里拿fofa的资产来说,比如说挖的是oa的shell和未授权,大部分是不会有域名的,从业务的角度来说,这自用很少有域名,清洗ip拿域名需要用的一些姿势如图,(脚本在文末)
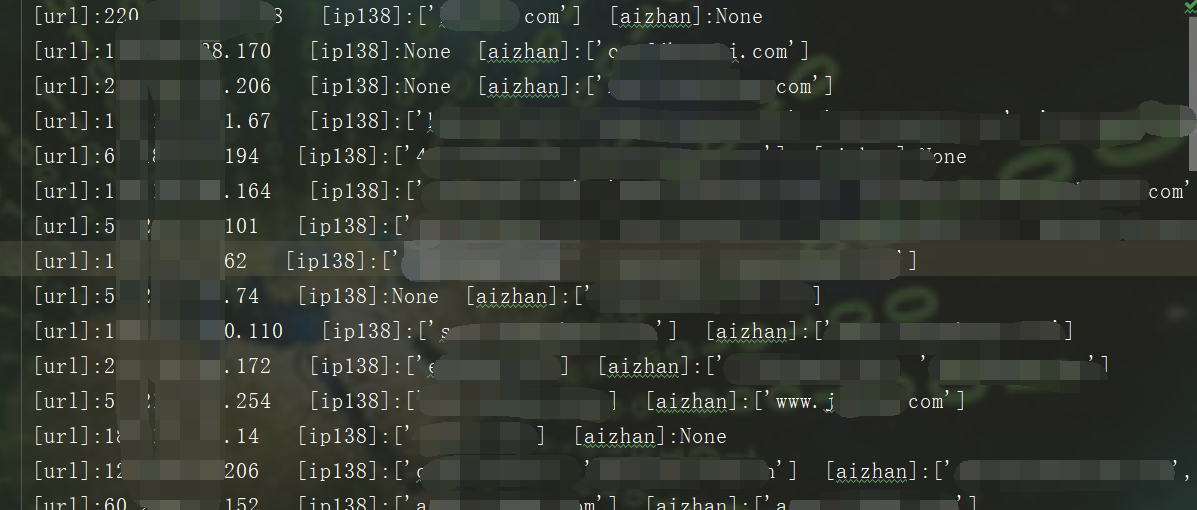
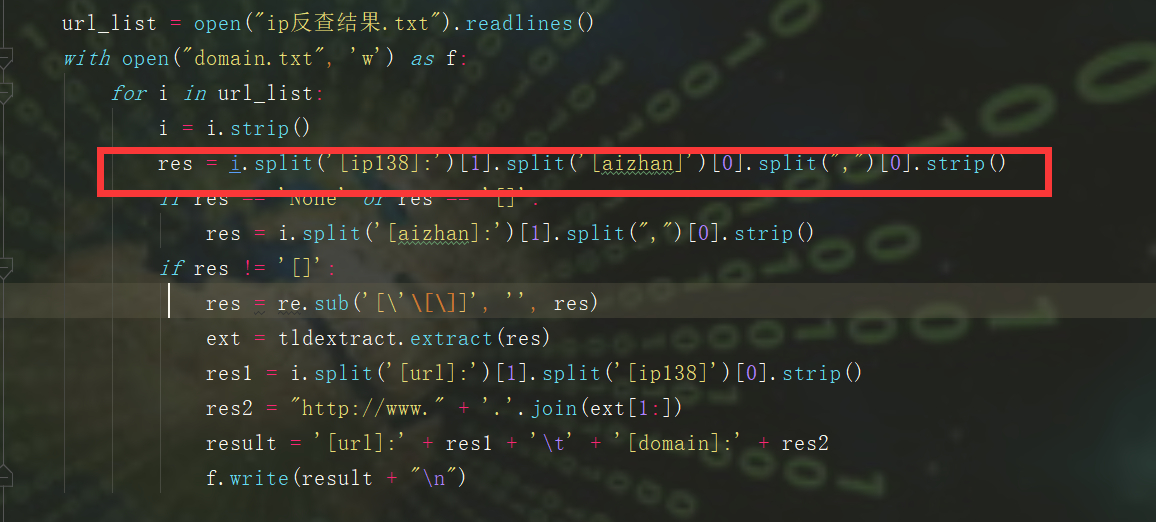
这里的结果是[url]:ip138:xxx aizhan:xxx ,我的思路是split()分割符去ip138和之后的部分,后面在通过split去ip138的部分,拿到查询结果

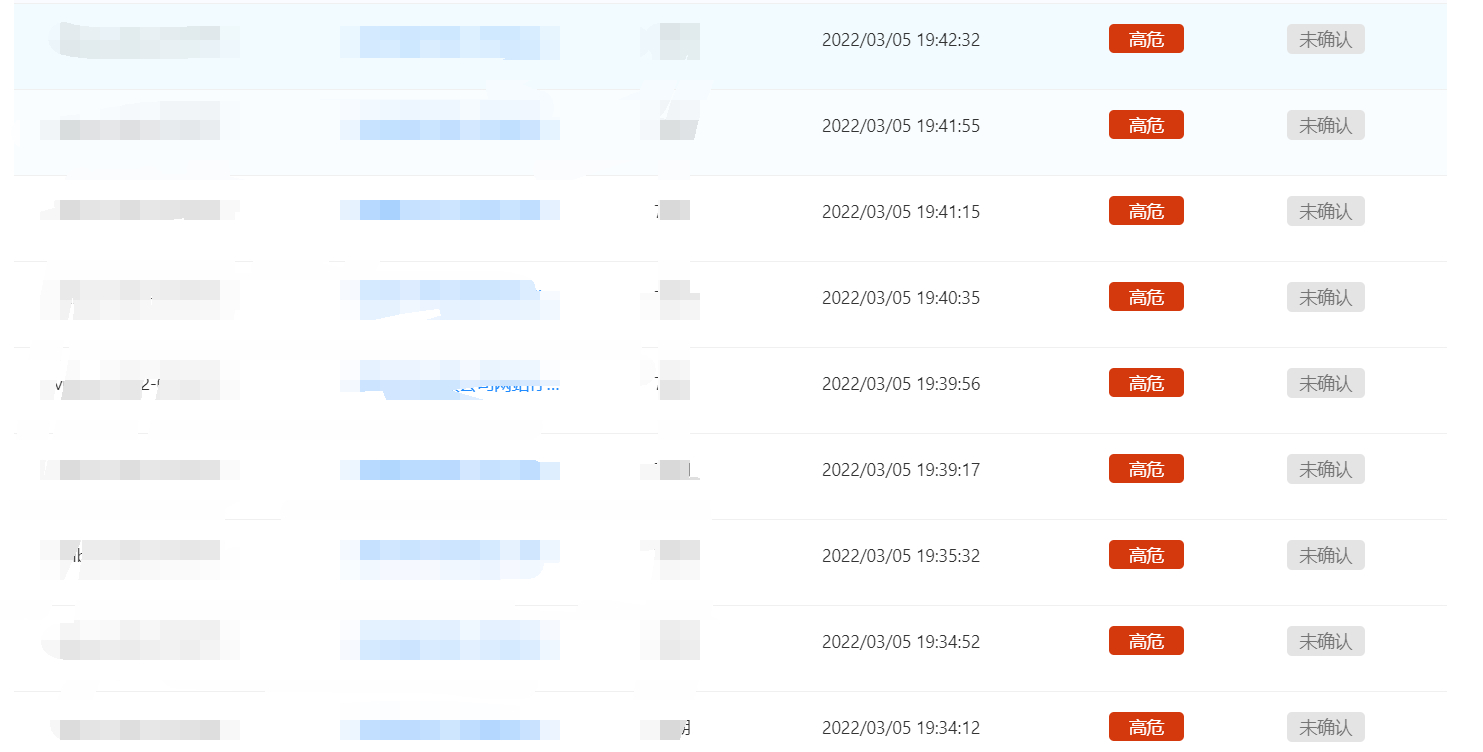
2.拿到域名后需要找归属和权重,如果是要交src,报告里要附有归属的截图,(脚本在文末,仅供参考)
1.通过re正则匹配返回包标签内的内容,常用匹配
re.findall(r"""<span data-v-dcbac042>(.*?)</span></a>""", result.text)
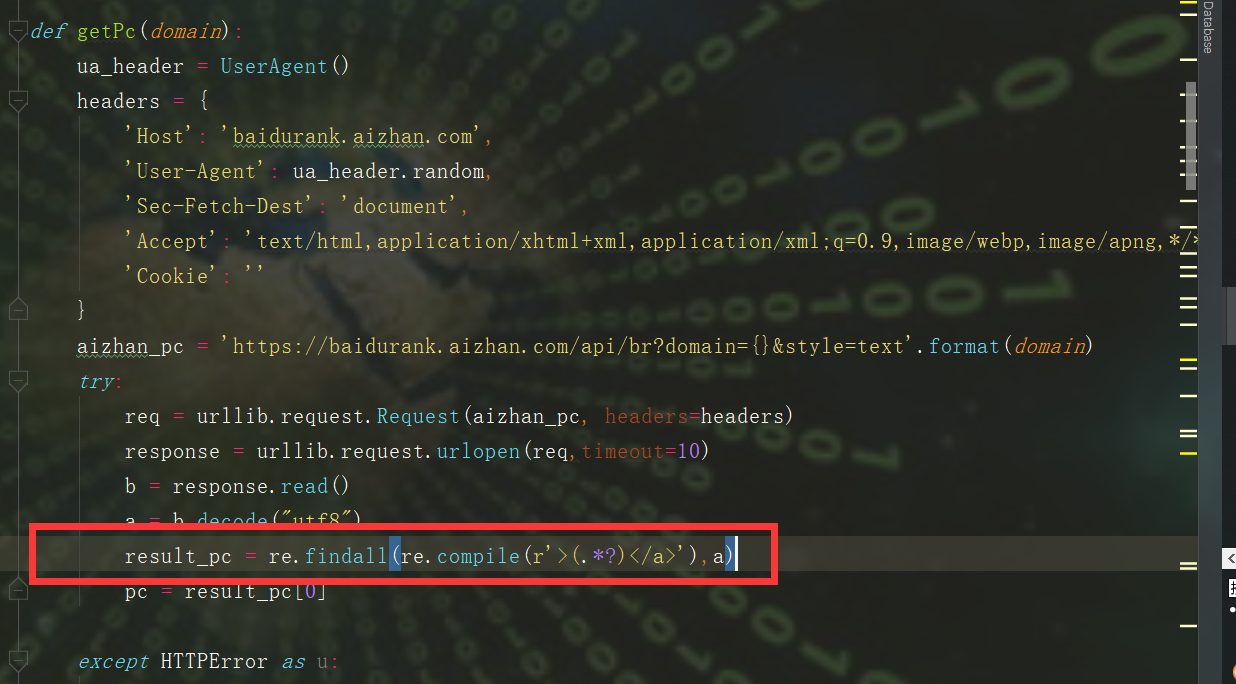
i找到归属后
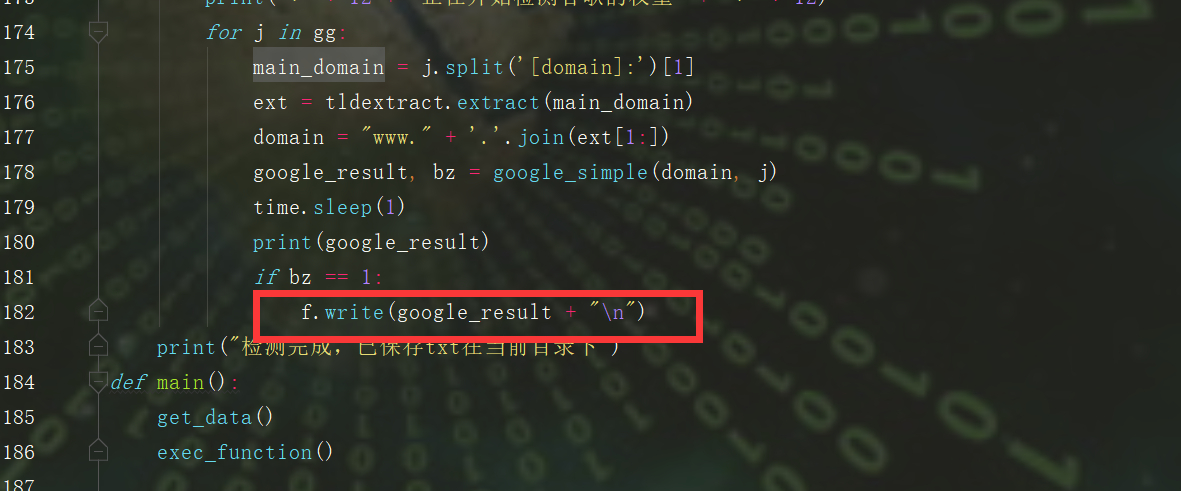
ii. 打开一个文本,用来保存查询的结果,常用
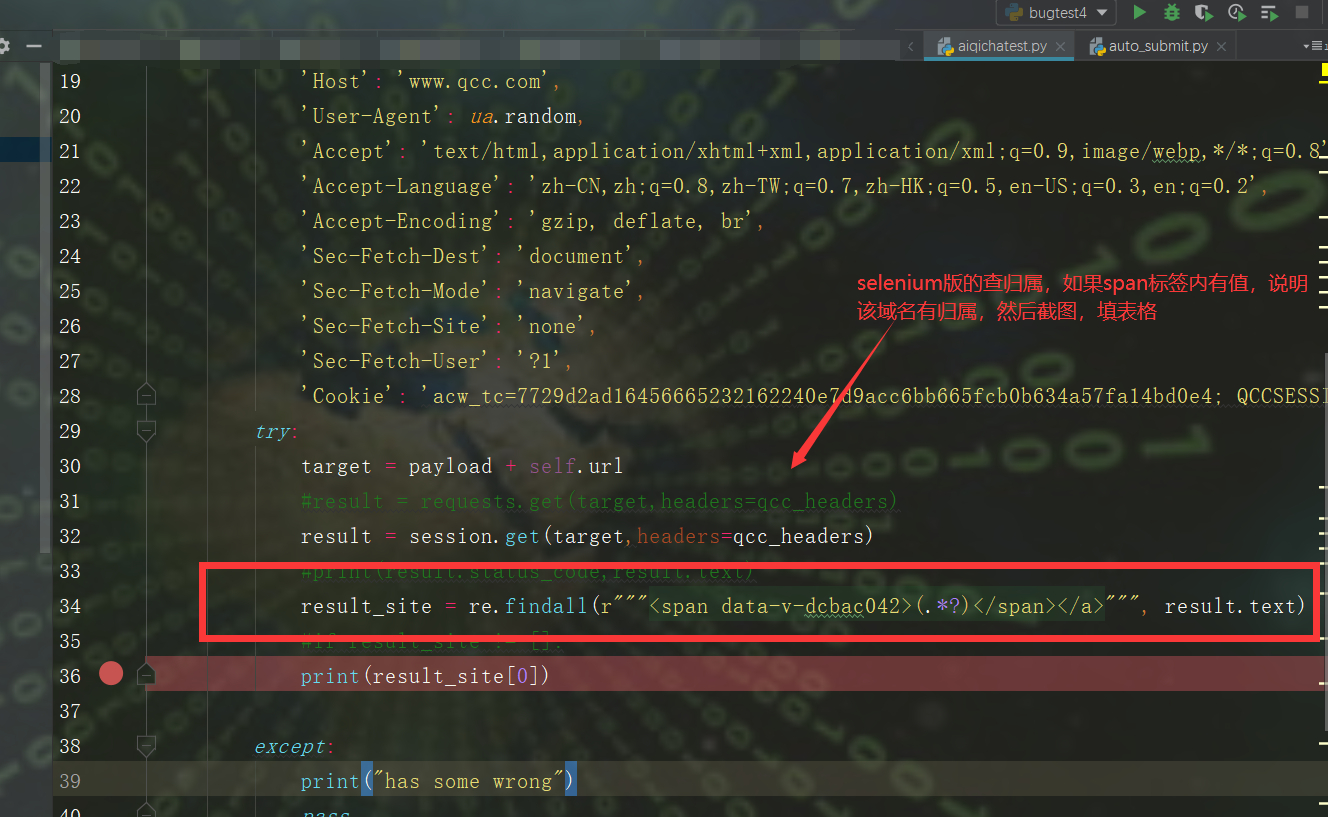
iii.查归属常用姿势
3.漏洞提交,
i.准备个csv,(不用xlsx的原因有很多,主要是兼容问题)
ii.通过pandas.drop()可以实现不用递归excel表格内的内容,比如盒子,补天提交,提交后等待几秒即可提交下一部分。
4.一些探讨
实际漏洞验证很复杂,src平台对提交的内容(厂商归属和漏洞验证截图)都看重,你这里没截图就没过,如果说量比较少的情况下,尽量手工收集材料截图。selenium截图不包括地址栏的内容,这样就看不到归属,直接pass掉了。
另外,excel两个常用姿势清洗数据内容: 1. 选中某列,查找aaa*,会全部去掉aaa*的内容,2.选中某列,智能筛选,输入需要的表达式,会筛选相关的符合要求的列。。
5.脚本内容
1.通过批量验证+文件保存
import re
import requests
import time
from requests.packages.urllib3.exceptions import InsecureRequestWarning
import sys
import random
poc =”/index.php/xxxx”
def module():
print(‘——————————‘)
print(‘+来源peiqi文库修改版,魔改author:echo’)
print(‘+使用格式:python vuln-echo.py’)
print(‘输入漏洞地址’)
print(‘——————————‘)
def vuln(url):
headers = {
“User-Agent”: “Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.111 Safari/537.36”,
}
try:
target = url + poc
req_result = requests.get(target,timeout=3, headers=headers, verify=False)
if (‘syntax’ in req_result.text) and req_result.status_code == 200:
print(“站点{}存在sqli注入”.format(url))
f.write(url)
# print(req_result.text)
print(result_site)
else:
sys.exit(0)
#else:
print(“站点{}不存在sqli注入”.format(target_url))
sys.exit(0)
except:
print(“nmm的手气炸了,出bug了”)
print(target)
pass
def Scan(file_name):
with open(file_name, “r”, encoding=’utf8’) as scan_url:
for url in scan_url:
if url[:4] != “http”:
url = “http://“ + url
url = url.strip(‘\n’)
try:
vuln(url)
except:
print(“请求报错”)
continue
if __name__ == ‘__main__‘:
module()
target_url = str(input(“输入漏洞文件名\n”))
with open(‘./vulnsql1.txt’, ‘a’, encoding=’utf-8’) as f:
Scan(target_url)
2.selenium版批量查域名归属+截图
from selenium import webdriver
import requests
import os
from fake\_useragent import UserAgent
session = requests.session()
import re
class Poc:
def \_\_init\_\_(self, url):
self.url = url
# self.url = info
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:93.0) Gecko/20100101 Firefox/93.0",
"Host": "www.qcc.com",
}
# self.chrome = webdriver.Chrome(executable\_path='chromedriver.exe')
def qcc(self,ua):
payload = "https://www.qcc.com/web/search?key="
qcc\_headers = {
'Host': 'www.qcc.com',
'User-Agent': ua.random,
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,\*/\*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'none',
'Sec-Fetch-User': '?1',
'Cookie': 'acw\_tc=7729d2ad16456665232162240e7d9acc6bb665fcb0b634a57fa14bd0e4; QCCSESSID=d7b8f5ab4f4b6865b70c9afbf9;'}
try:
target = payload + self.url
#result = requests.get(target,headers=qcc\_headers)
result = session.get(target,headers=qcc\_headers)
#print(result.status\_code,result.text)
result\_site = re.findall(r"""<span data-v-dcbac042>(.\*?)</span></a>""", result.text)
#if result\_site != \[\]:
print(result\_site\[0\])
except:
print("has some wrong")
pass
if \_\_name\_\_ == '\_\_main\_\_':
location = os.getcwd() + '/fake\_useragent\_0.1.11.json'
ua\_header = UserAgent(path=location)
targets = open("./domain.txt", "r")
#数据清洗
for target in targets.readlines():
target = target.strip()
targets = target.split("http://")\[1\]
# print(targets)
poc = Poc(targets)
poc.qcc(ua\_header)
3.批量ip反查(aizhan+ip138)
import time
import re
import requests
from fake_useragent import UserAgent
from tqdm import tqdm
import os
# ip138
def ip138_chaxun(ip, ua):
ip138_headers = {
'Host': 'site.ip138.com',
'User-Agent': ua.random,
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://site.ip138.com/'}
ip138_url = 'https://site.ip138.com/' + str(ip) + '/'
try:
ip138_res = requests.get(url=ip138_url, headers=ip138_headers, timeout=2).text
if '<li>暂无结果</li>' not in ip138_res:
result_site = re.findall(r"""</span><a href="/(.*?)/" target="_blank">""", ip138_res)
return result_site
except:
pass
# 爱站
def aizhan_chaxun(ip, ua):
aizhan_headers = {
'Host': 'dns.aizhan.com',
'User-Agent': ua.random,
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8',
'Accept-Language': 'zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2',
'Accept-Encoding': 'gzip, deflate, br',
'Referer': 'https://dns.aizhan.com/'}
aizhan_url = 'https://dns.aizhan.com/' + str(ip) + '/'
try:
aizhan_r = requests.get(url=aizhan_url, headers=aizhan_headers, timeout=2).text
aizhan_nums = re.findall(r'''<span class="red">(.*?)</span>''', aizhan_r)
if int(aizhan_nums[0]) > 0:
aizhan_domains = re.findall(r'''rel="nofollow" target="_blank">(.*?)</a>''', aizhan_r)
return aizhan_domains
except:
pass
def catch_result(i):
ua_header = UserAgent()
i = i.strip()
try:
# ip = i.split(':')[1].split('//')[1]
ip = i.split(":")[0]
ip138_result = ip138_chaxun(ip, ua_header)
aizhan_result = aizhan_chaxun(ip, ua_header)
time.sleep(1)
if ((ip138_result != None and ip138_result!=[]) or aizhan_result != None ):
with open("vulnwebshell.txt", 'a') as f:
result = "[url]:" + i + " " + "[ip138]:" + str(ip138_result) + " [aizhan]:" + str(aizhan_result)
print(result)
f.write(result + "\n")
else:
with open("反查失败列表.txt", 'a') as f:
f.write(i + "\n")
except:
pass
if __name__ == '__main__':
url_list = open("vuln.txt", 'r').readlines()
url_len = len(open("vuln.txt", 'r').readlines())
#每次启动时清空两个txt文件
if os.path.exists("反查失败列表.txt"):
f = open("反查失败列表.txt", 'w')
f.truncate()
if os.path.exists("vulnmail.txt"):
f = open("vulnmail.txt", 'w')
f.truncate()
for i in tqdm(url_list):
#i=i.split(":")[0]
catch_result(i)
- 本文作者: echoa
- 本文来源: 奇安信攻防社区
- 原文链接: https://forum.butian.net/share/1446
- 版权声明: 除特别声明外,本文各项权利归原文作者和发表平台所有。转载请注明出处!

