
概述trapfuzzer-gdb 基于 gdb-9.2 修改,目前主要用于trapfuzzer的一个组件,用于对二进制程序进行Fuzzing。代码地址’’’https//github.com/hac425xxx/trapfuzzer-gdb’’’…
概述
trapfuzzer-gdb 基于 gdb-9.2 修改,目前主要用于trapfuzzer的一个组件,用于对二进制程序进行Fuzzing。
代码地址
https://github.com/hac425xxx/trapfuzzer-gdb
GDB源码分析
概述
GDB为了支持多个平台、架构,代码量非常的多,代码的结构也比较复杂,本节主要介绍Linux平台下的工作机制。
在Linux平台下, GDB的主要工作原理是使用 ptrace 来对进程进行调试。在GDB中一个进程称为 inferior,所以代码中带这个单词的大概率与目标进程的操作有关。
GDB中各种操作是基于事件驱动的,start_event_loop 函数会在事件到来时调用相应的处理函数处理事件。
start_event_loop () at ../../gdb/event-loop.c:370
captured_command_loop () at ../../gdb/main.c:359
captured_main at ../../gdb/main.c:1202
gdb_main at ../../gdb/main.c:1217
main at ../../gdb/gdb.c:32
比如当用户输入调试命令时会进入 handle_command 处理,当目标进程(inferior)命中一个断点,收到一个信号时则会进入 fetch_inferior_event 。fetch_inferior_event 可以认为是GDB中的最核心部分,当inferior触发各种事件时都会进到这个函数,比如进程创建,SO加载,进程退出、命中断点等。
信号处理
fetch_inferior_event 会调用 handle_inferior_event 处理具体的inferior事件。handle_inferior_event 会对不同的事件进行相应的处理,如果该事件是进程收到了信号,则会进入handle_signal_stop进一步处理。
该函数主要是在处理断点和观察点,这两者的处理方式基本类似,大概流程如下
- 进程命中一个断点或者观察点,进程会进入该函数处理,函数发现是命中断点断点或者观察点时则会停止下来让用户可以输入gdb命令。
- 当用户需要继续执行时,GDB的首先取消断点和观察点,然后单步步过刚刚那条指令
- 最后恢复断点和观察点,继续执行接下来的代码。
具体到代码则是如果发现需要单步步过触发断点或者时观察点的指令时,则会设置相应的字段通知下层的函数:该信号处理完成后以单步执行的方式执行进程,这样当进程执行完一条指令后就会再次进入handle_signal_stop,第二次进入handle_signal_stop则会把上一次临时取消的断点和观察点重新启用。
具体设置字段如下
ecs->event_thread->stepping_over_breakpoint = 1// 断点
ecs->event_thread->stepping_over_watchpoint = 1// 观察点
handle_signal_stop函数有三种返回的方式
keep_going
stop_waiting
prepare_to_wait
下面分别介绍
- keep_going:表示让inferior以continue的方式恢复执行,gdb进入事件等待循环。
- stop_waiting:表示gdb暂停等待用户输入命令,inferior处于暂停状态。
- prepare_to_wait:表示目标进程已经处于运行状态,gdb进入事件等待循环,往往和 resume (恢复进程执行)一起使用。
如果我们想自己处理某些信号的话,就可以在handle_signal_stop里面进行处理,然后使用keep_going、stop_waiting等函数返回即可。
比如如果我们想在目标进程收到abort信号时停止下来,可以在handle_signal_stop函数中查看ecs->event_thread->suspend.stop_signal的值来判断是否为abort信号,如果是则调用stop_waiting表示让gdb停下来等待用户的操作,然后返回当前函数。
/* At this point, get hold of the now-current thread's frame. */
frame = get_current_frame ();
gdbarch = get_frame_arch (frame);
.....................
.....................
if (ecs->event_thread->suspend.stop_signal == GDB_SIGNAL_ABRT)
{
stop_waiting (ecs);
fprintf_unfiltered (gdb_stdlog, "ABORT, total exec count:%d\n", g_exec_count++);
return;
}
想要自定义gdb的信号处理机制只能通过修改源码的方式实现,gdb提供的python插件接口只能在事件发生后收到一个通知,而不能修改信号处理机制。
命令注册
在gdb源码中添加一个命令也比较简单,使用add_com函数即可。
c = add_com ("inject-so", class_run, inject_so_cmd, _("inject so to process.\n" RUN_ARGS_HELP));
set_cmd_completer (c, filename_completer);
上面的例子会往gdb中添加inject-so命令,处理命令的函数为inject_so_cmd,命令回调函数的入参如下
void
inject_so_cmd (const char *args, int from_tty)
{
if(args == NULL)
{
fprintf_unfiltered (gdb_stdlog, "inject_so_cmd so_full_path\n");
return;
}
CORE_ADDR lib_addr = target_load_library((char*)args);
dl_handle_list.push_back(lib_addr);
fprintf_unfiltered (gdb_stdlog, "inject_so_cmd(%s):%p\n", args, lib_addr);
}
其中 args 为命令的参数字符串。
新增功能实现分析
这节介绍对gdb源码的修改尝试,以及实现细节。
SO注入
首先使用 add_com 增加一个命令 inject-so, 作用是往进程空间中注入一个so,命令的回调函数是 inject_so_cmd 。
c = add_com ("inject-so", class_run, inject_so_cmd, _("inject so to process.\n" RUN_ARGS_HELP));
set_cmd_completer (c, filename_completer);
inject_so_cmd的实现如下
void
inject_so_cmd (const char *args, int from_tty)
{
if(args == NULL)
{
fprintf_unfiltered (gdb_stdlog, "inject_so_cmd so_full_path\n");
return;
}
CORE_ADDR lib_addr = target_load_library((char*)args);
dl_handle_list.push_back(lib_addr);
fprintf_unfiltered (gdb_stdlog, "inject_so_cmd(%s):%p\n", args, lib_addr);
}
主要逻辑位于 target_load_library 函数,在gdb调试程序时可以使用 p func() 或者 call func() 等方式调用被调试进程中的某个函数,其大概的思路如下
- 修改原始进程中某些代码为特定的shellcode
- 在shellcode中设置函数的参数并调用对应的函数
- 调用函数返回后会通知gdb,gdb取出返回值返回给用户。
为了方便使用对gdb的这块功能进行了封装
get_func_value 用于获取 module_name 中 func_name 的地址。
struct value * get_func_value(char* module_name, char* func_name)
{
struct type *type;
struct gdbarch *gdbarch = get_current_arch ();
type = lookup_pointer_type (builtin_type (gdbarch)->builtin_char);
type = lookup_function_type (type);
type = lookup_pointer_type (type);
CORE_ADDR addr = get_func_addr_by_module_name(module_name, func_name);
struct value *func = value_from_pointer (type, addr);
return func;
}
然后按照gdb源码调用的方式调用相应的函数,以调用 malloc 为例。
CORE_ADDR
target_call_malloc (CORE_ADDR size)
{
struct value *addr_val;
CORE_ADDR retval;
struct value *arg[1];
struct gdbarch *gdbarch = get_current_arch ();
struct value *func = get_func_value("libc", "malloc");
arg[0] = value_from_longest (builtin_type (gdbarch)->builtin_unsigned_long, size);
addr_val = call_function_by_hand (func, NULL, arg);
retval = value_as_address (addr_val);
if (retval == (CORE_ADDR) 0)
fprintf_unfiltered (gdb_stdlog, "target_call_malloc failed\n");
if(g_debug)
fprintf_unfiltered (gdb_stdlog, "target_call_malloc: %p\n", retval);
return retval;
}
- 首先使用
get_func_value获取libc中malloc函数的地址 - 然后
call_function_by_hand调用具体的函数。 - 使用
value_as_address将返回值value*转为CORE_ADDR。
下面继续看target_load_library的代码
CORE_ADDR
target_load_library (char* library)
{
CORE_ADDR addr = target_call_malloc(strlen(library) + 1);
target_write_memory(addr, (const gdb_byte *)library, strlen(library) + 1);
CORE_ADDR so_handle = target_call_dlopen(addr);
target_call_free(addr);
return so_handle;
}
- 首先在目标进程中调用 malloc 分配内存用于存放库的全路径,然后使用target_write_memory往分配的地址中写入库路径。
- 然后调用target_call_dlopen加载需要的库。
继续看 target_call_dlopen 的实现,由于 dlopen 位于 libdl.so,大多数进程中不一定会加载 libdl.so,所以为了通用这里调用的时 libc 里面的 __libc_dlopen_mode 函数,这个函数的功能和 dlopen的功能一样,可以用来加载一个so。
CORE_ADDR
target_call_dlopen (CORE_ADDR addr)
{
struct value *retval_val;
CORE_ADDR retval;
struct gdbarch *gdbarch = get_current_arch ();
struct value *func = get_func_value("libc", "__libc_dlopen_mode");
enum
{
ARG_ADDR, ARG_MODE, ARG_LAST
};
struct value *arg[ARG_LAST];
arg[ARG_ADDR] = value_from_pointer (builtin_type (gdbarch)->builtin_data_ptr, addr);
arg[ARG_MODE] = value_from_longest (builtin_type (gdbarch)->builtin_int, 0x80000001);
retval_val = call_function_by_hand (func, NULL, arg);
retval = value_as_address (retval_val);
return retval;
}
so注入后会把得到的handle 保存到 gdb里面的一个全局列表中,以便后面可以卸载加载的so。卸载so的命令实现如下
void
unload_so_cmd (const char *args, int from_tty)
{
for(int i=0; i < dl_handle_list.size(); i++)
{
target_call_dlclose(dl_handle_list[i]);
}
dl_handle_list.clear();
}
主要就是调用 libc 中的 __libc_dlclose 卸载之前加载的 so, 这个函数对应 libdl.so 的 dlclose.
CORE_ADDR
target_call_dlclose (CORE_ADDR addr)
{
struct value *retval_val;
CORE_ADDR retval;
struct gdbarch *gdbarch = get_current_arch ();
struct value *func = get_func_value("libc", "__libc_dlclose");
enum
{
ARG_ADDR, ARG_LAST
};
struct value *arg[ARG_LAST];
arg[ARG_ADDR] = value_from_pointer (builtin_type (gdbarch)->builtin_data_ptr, addr);
retval_val = call_function_by_hand (func, NULL, arg);
retval = value_as_address (retval_val);
return retval;
}
软件内存断点
在gdb中可以使用 watch 和 rwatch 命令来使用内存断点,默认情况下采用硬件断点实现的,而硬件断点的个数是有限的,而且在某些平台默认没有启用(某些安卓设备),而软件观察点实现是通过单步执行实现的,可想而知其性能损耗会非常大,基本不可用。
本节实现软件内存断点的原理如下,假设需要监视 [A, A+B] 范围的读写访问
- 首先将
[A, A+B]所在页面P标记为 不可读写,然后让程序继续运行 - 如果程序发生了
SEGV,判断程序需要访问的内存是否为页面 P 中的,如果是进一步判断是否位于[A, A+B]范围,如果不是则恢复页面的权限,然后单步执行该指令,指令执行完后重新将页面标记为不可读写 - 如果命中观察点,则停下来,通知用户进一步处理。
首先看看设置内存断点的命令 membrk_cmd.
void
membrk_cmd (const char *args, int from_tty)
{
if(args == NULL)
{
fprintf_unfiltered (gdb_stdlog, "membrk addr size rw\n");
return;
}
CORE_ADDR addr = 0;
char prot[10] = {0};
unsigned int sz = 0;
sscanf(args, "%p 0x%x %3s", &addr, &sz, prot);
fprintf_unfiltered (gdb_stdlog, "membrk %p 0x%x %s\n", addr, sz, prot);
MEM_BRK_INFO* info = (MEM_BRK_INFO*) malloc(sizeof(MEM_BRK_INFO));
info->prot = 7;
for(int i=0; i<3; i++)
{
switch(prot[i])
{
case 'r':
info->prot &= ~PROT_READ;
break;
case 'w':
info->prot &= ~PROT_WRITE;
break;
case 'x':
info->prot &= ~PROT_EXEC;
break;
}
}
fprintf_unfiltered (gdb_stdlog, "prot:%d\n", info->prot);
unsigned int pad_size = FUZZ_PAGE_SIZE - (sz % FUZZ_PAGE_SIZE);
unsigned int page_len = sz + pad_size;
CORE_ADDR page_addr = addr - (addr % FUZZ_PAGE_SIZE);
target_call_mprotect(page_addr, page_len, info->prot);
info->address = addr;
info->length = sz;
info->page_address = page_addr;
info->page_size = page_len;
mem_brk_info_list.push_back(info);
}
代码流程如下
- 首先获取命令参数,监控的地址、大小以及监控的类型
- 然后将监控类型转换为页面的权限,比如监控rw,则页面的最终权限为 x.
- 然后调用 mprotect 修改页面权限
- 最后将内存断点信息加入全局列表,供后续流程处理
下面进入内存断点的核心处理逻辑,位于 handle_signal_stop 中
if (ecs->event_thread->suspend.stop_signal == GDB_SIGNAL_SEGV)
{
CORE_ADDR access = 0;
MEM_BRK_INFO* info = NULL;
try
{
access = parse_and_eval_long ("$_siginfo._sifields._sigfault.si_addr");
CORE_ADDR pc = regcache_read_pc (get_thread_regcache (ecs->event_thread));
CORE_ADDR instr_access_size = 4; // 目前设置为一个固定值,可能会有误报
if(g_debug)
fprintf_unfiltered (gdb_stdlog, "pc:%p, access:%p\n", pc, access);
info = get_mem_brk_info_by_addr(access, instr_access_size);
if(info != NULL)
{
if(access >= info->address - instr_access_size && access <= info->address + info->length + instr_access_size)
{
fprintf_unfiltered (gdb_stdlog, "[membrk hit] pc: %p, access: %p-%p, hit: %p-%p\n", pc, access, access + instr_access_size, info->address, info->address + info->length);
target_call_mprotect(info->page_address, info->page_size, 7);
ecs->event_thread->suspend.stop_signal = GDB_SIGNAL_TRAP; // nopass to program
g_need_stop = 1;
g_pre_mem_brk_info = info;
ecs->event_thread->stepping_over_watchpoint = 1;
keep_going (ecs);
return;
}
else
{
if(g_debug)
fprintf_unfiltered (gdb_stdlog, "no catch\n");
target_call_mprotect(info->page_address, info->page_size, 7);
ecs->event_thread->suspend.stop_signal = GDB_SIGNAL_TRAP; // nopass to program
g_need_stop = 0;
g_pre_mem_brk_info = info;
ecs->event_thread->stepping_over_watchpoint = 1;
keep_going (ecs);
return;
}
}
}
catch (const gdb_exception &exception)
{
;
}
当进程试图去访问被修改过权限的页面时,比如页面被设置为只执行,如果进程去读或者写该页面,则会触发 SEGV 信号,此时gdb会捕获到这个信号,然后进入到上面的代码。
- 首先访问
$_siginfo._sifields._sigfault.si_addr获取进程此时要访问的内存 - 然后使用
get_mem_brk_info_by_addr判断是否为内存断点页面中 - 如果访问的内存在某个内存断点的页面中,就进一步校验,判断是否命中内存断点,命中或者不命中的处理大体一致,都需要首先设置当前页面为rwx,然后单步执行这条指令,单步执行后需要恢复页面的权限。
- 如果是命中断点则停下来让用户操作,否则让程序继续运行。
回到上面的代码,首先看命中断点的处理
- 首先使用
mprotect设置页面权限为rwx,然后设置ecs->event_thread->suspend.stop_signal和ecs->event_thread->stepping_over_watchpoint,表示这次函数执行完后,目标程序需要单步执行,执行完一条指令后会再次进入,下次进入的信号为GDB_SIGNAL_TRAP. g_need_stop表示当前指令执行完后是否需要断下来,如果命中断点则为1,否则为0.g_pre_mem_brk_info用于保存触发SEGV的页面信息,用于后面恢复页面的权限。- 设置完之后调用 keep_going (ecs) 让目标进程执行,然后返回该函数。
单步执行完这条指令后会再次进入handle_signal_stop ,不过此时的信号为 GDB_SIGNAL_TRAP .
if (ecs->event_thread->suspend.stop_signal == GDB_SIGNAL_TRAP)
{
struct regcache *regcache;
CORE_ADDR pc;
regcache = get_thread_regcache (ecs->event_thread);
const address_space *aspace = regcache->aspace ();
pc = regcache_read_pc (regcache);
if(g_pre_mem_brk_info != NULL)
{
MEM_BRK_INFO* mbi = g_pre_mem_brk_info;
g_pre_mem_brk_info = NULL;
ecs->event_thread->stepping_over_watchpoint = 0;
target_call_mprotect(mbi->page_address, mbi->page_size, mbi->prot);
if(g_debug)
fprintf_unfiltered (gdb_stdlog, "mem brk retore single_step, pc:%p\n", pc);
if(g_need_stop)
{
stop_waiting (ecs);
}
else
{
keep_going (ecs);
}
g_need_stop = 0;
return;
}
这里的处理很简单,首先设置 ecs->event_thread->stepping_over_watchpoint,然后使用mprotect恢复页面的权限,如果命中了断点则调用 stop_waiting 让gdb停下来让用户操作,否则调用keep_going让程序继续运行。
获取程序覆盖率
trapfuzzer-gdb 最主要的功能是作为 trapfuzzer 的一个组件,用于在Fuzz过程中获取程序的覆盖率。该功能的主要工作流程是在启动 trapfuzzer-gdb后,使用load-trapfuzzer-info 命令导入之前使用IDA导出的目标二进制的基本块信息,然后运行目标程序,当程序执行到一个新的基本块时会触发基本块的断点,然后trapfuzzer-gdb记录当前执行的位置并恢复基本块的指令,让程序继续往下执行。
load-trapfuzzer-info命令的实现如下:
static void
load_trapfuzzer_info (const char *args, int from_tty)
{
if(args == NULL)
{
fprintf_unfiltered (gdb_stdlog, "load-trapfuzzer-info bb_file\n");
return;
}
if(g_debug)
{
fprintf_unfiltered (gdb_stdlog, "load-trapfuzzer-info %s\n", args);
}
COV_MOD_INFO* cmi = new COV_MOD_INFO;
FILE *fp = fopen(args, "rb");
fread(&cmi->rva_size, 4, 1, fp);
int fname_sz = 0;
fread(&fname_sz, 4, 1, fp);
fread(cmi->module_name, fname_sz, 1, fp);
BB_INFO tmp = {0};
while(fread(&tmp, 4 * 3, 1, fp) == 1)
{
fread(&tmp.instr, tmp.instr_size, 1, fp);
BB_INFO* info = (BB_INFO*)malloc(sizeof(BB_INFO));
memcpy(info, &tmp, sizeof(BB_INFO));
cmi->bb_info_map[info->voff] = info;
if(g_debug)
fprintf_unfiltered (gdb_stdlog, "voff:0x%X\n", info->voff);
}
fclose(fp);
cmi->image_base = 0;
cmi->image_end = 0;
cmi->full_path[0] = '\x00';
cmi->mod_id = g_cov_mod_count++;
cov_mod_info_list.push_back(cmi);
fprintf_unfiltered (gdb_stdlog, "load-trapfuzzer-info done\n");
}
主要就是解析IDA导出的基本块信息,然后将解析出的信息保存到 cov_mod_info_list 全局列表中。
当命中断点时,gdb会进入handle_signal_stop进行处理
/* Pull the single step breakpoints out of the target. */
if (ecs->event_thread->suspend.stop_signal == GDB_SIGNAL_TRAP)
{
struct regcache *regcache;
CORE_ADDR pc;
regcache = get_thread_regcache (ecs->event_thread);
const address_space *aspace = regcache->aspace ();
pc = regcache_read_pc (regcache);
COV_MOD_INFO* cmi = get_cov_mod_info_by_pc(pc);
if(cmi == NULL)
{
parse_maps(ecs->ptid.pid());
cmi = get_cov_mod_info_by_pc(pc);
}
if(cmi != NULL)
{
// location to add trapfuzzer patch
unsigned int voff = pc - cmi->image_base;
// exit point
if(is_exit_bb(voff))
{
if(g_in_fuzz_mode)
{
g_exec_status = NORMAL;
run_command ("", 0);
prepare_to_wait (ecs);
}
else
{
stop_waiting (ecs);
}
return;
}
if(cmi->bb_info_map[voff] != NULL)
{
BB_INFO* info = cmi->bb_info_map[voff];
target_write_memory(pc, info->instr, info->instr_size);
cmi->bb_trace.push_back(voff);
keep_going (ecs);
return;
}
代码流程如下
- 首先根据此时的PC寄存器的值搜索出指定模块的基本块信息。
- 然后获取到PC处的原始指令
- 最后把原始指令patch回进程中,让进程继续往下执行,并记录执行过的基本块。
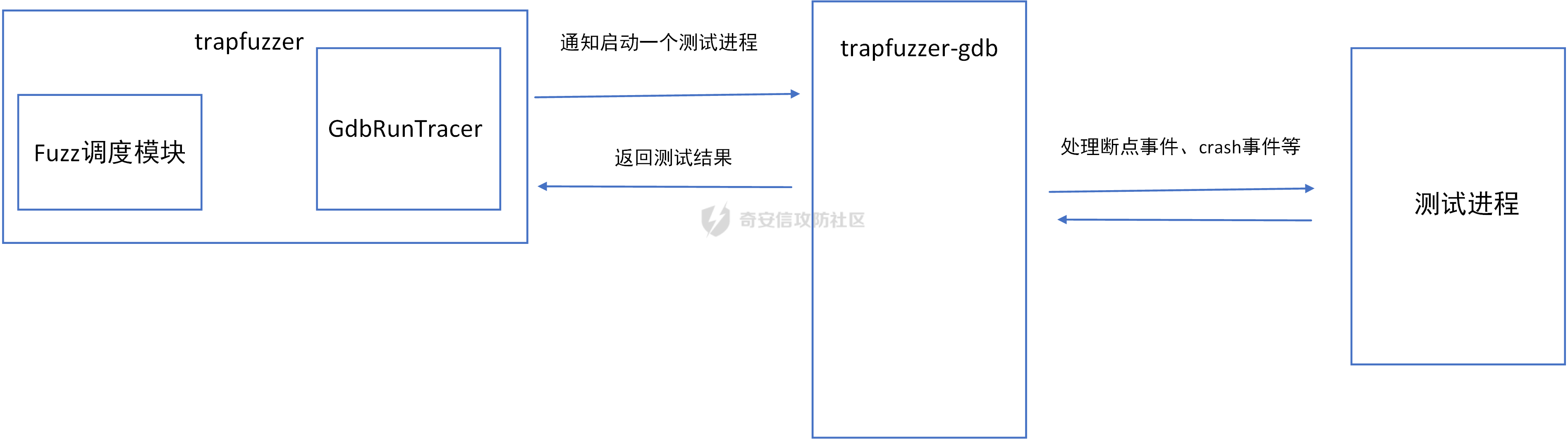
trapfuzzer和trapfuzzer-gdb的交互如图所示
- 首先
trapfuzzer使用GdbRunTracer.trace函数请求执行一个用例并获取执行的情况。 - 然后
GdbRunTracer会通知trapfuzzer-gdb去启动测试进程,trapfuzzer-gdb启动测试进程后会处理测试进程的断点事件(执行到新的基本块),crash事件等。 - 最后
trapfuzzer-gdb会把执行结果返回给GdbRunTracer,信息包括执行的基本块信息,是否crash以及crash信息。
具体使用案例,可以看一篇文章。
- 本文作者: hac425
- 本文来源: 奇安信攻防社区
- 原文链接: https://forum.butian.net/share/671
- 版权声明: 除特别声明外,本文各项权利归原文作者和发表平台所有。转载请注明出处!

